Core Machine Learning Concepts Part 4 - Mastering Bias, Variance, Underfitting, and Overfitting
Bias makes your model blind, variance makes it paranoid. The real magic? A sweet spot where it sees clearly and adapts wisely. That’s the bias-variance tradeoff.
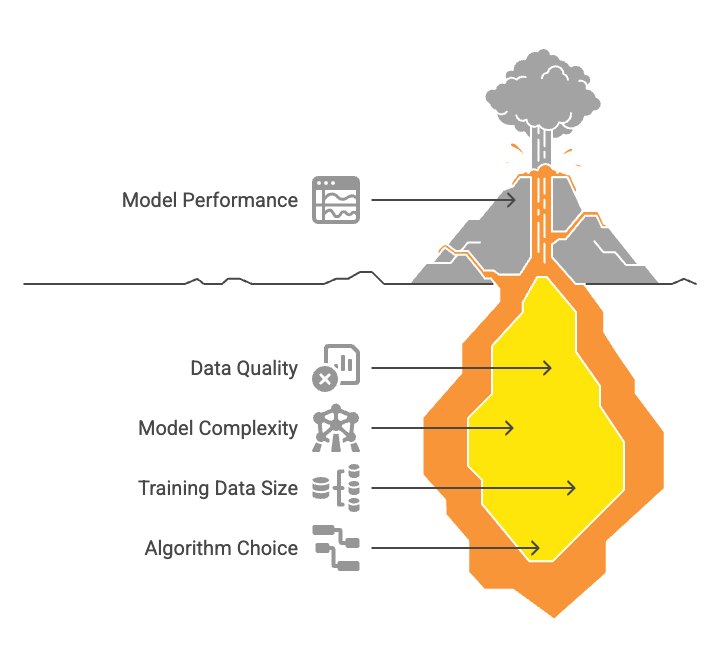
Ever trained a machine learning model that worked great during training but completely flopped on new data? Welcome to the classic machine learning challenge: Bias, Variance, Underfitting, and Overfitting. These aren't just buzzwords — they’re the foundation of every AI model’s success or failure.
🔎 Key Concepts Before Going Ahead
- Training Data: A subset of data used to train the machine learning model. The model learns patterns and adjusts parameters from this data.
- Testing Data: A separate subset is used to evaluate the model's performance on unseen data. It simulates real-world deployment scenarios.
🔎 Understanding Bias and Variance
When you make an AI model, you simply split the dataset into two parts [maybe randomly]: the training set and the testing set.
- If your model performs well on training but badly on testing, that’s low bias and high variance — it memorized the training data and fails to generalize.
👉 This is called Overfitting.
This might perform well in a training dataset with zero train error, but in testing data, this might fail to predict better, as you can see below, it has just learned the pattern but did not generalize it [which is what an AI model does]
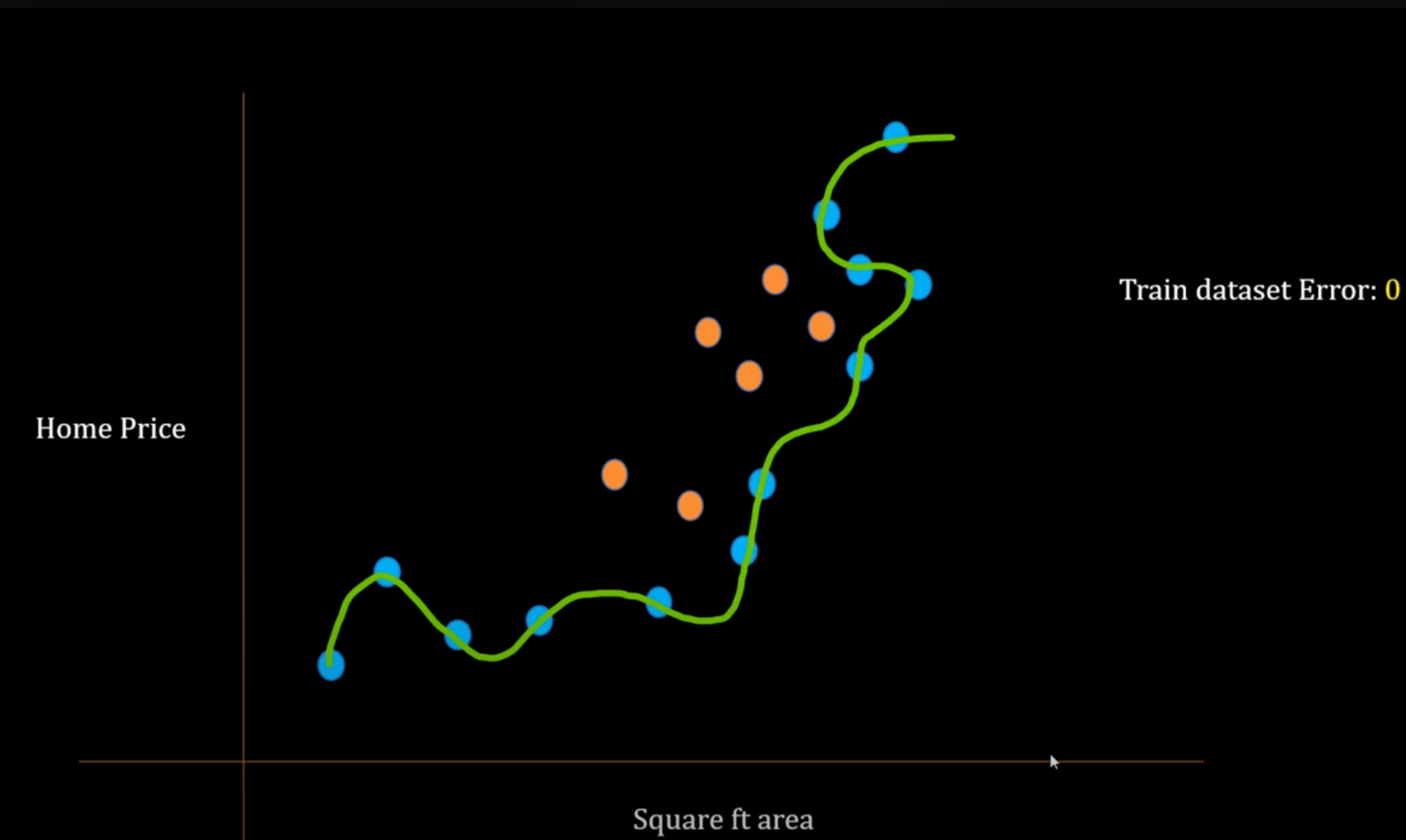
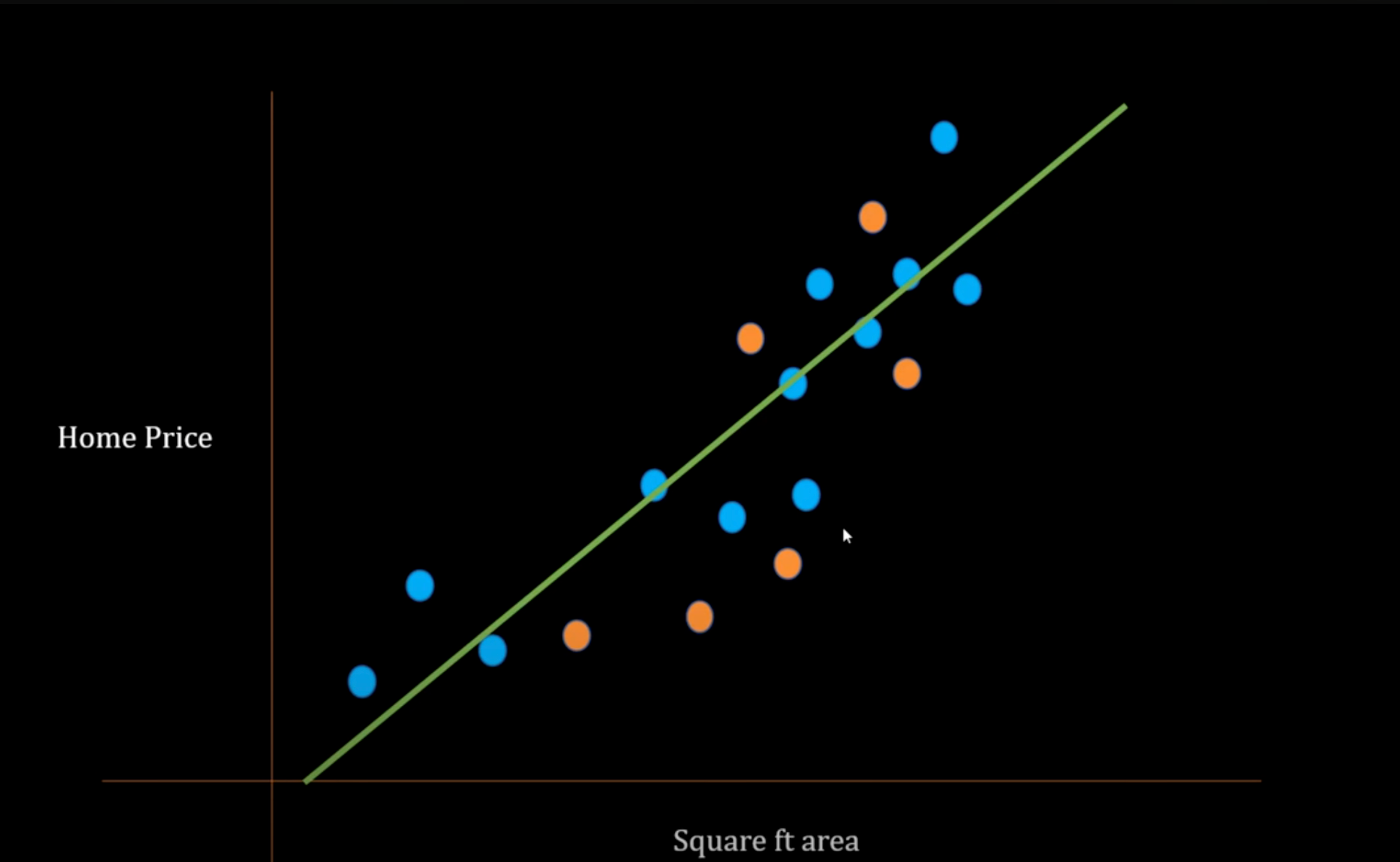
- If your model performs poorly on training (and likely also on testing), that’s high bias — it’s too simple to learn patterns. These models often have low variance, meaning they consistently perform poorly across different datasets.
👉 This is called Underfitting.
This will not perform well in the training dataset [High Bias] but even if you change the dataset of training and testing, the difference between testing errors won't be much, so low Variance, as this model is trying to generalize the trend for good prediction. But this won't be a great prediction either.
Bias shows up during training;
Variance shows up during testing.
💡 Bias vs Variance — Where They Live
| Type | Where You See It | What’s Happening |
|---|---|---|
| Bias | During Training | Model makes wrong assumptions. It learns a simplified view of the world and misses real patterns. |
| Variance | During Testing | Model learned too much from training data, including noise. Generalizes poorly. |
- High Variance: Model performs great on training, fails on test data. It memorized. It can’t generalize.
- High Bias: Model performs poorly even on training data. It's too simple. It can’t capture patterns.
“Bias is about training error. Variance is about testing error.”
👨🏫 Think of It Like This:
You're preparing for an exam:
- Bias problem: You didn’t study enough. You fail both the practice test and the real one. The model underperforms everywhere.
- Variance problem: You memorized the practice test answers. You ace practice but flunk the real exam. The model can't generalize.

1. Overfitting (Low Bias, High Variance)
- The model learns the training data too well, including noise and random fluctuations.
- Training performance: Excellent (low bias).
- Testing performance: Poor (high variance) because it fails to generalize to unseen data.
- Why? The model essentially memorizes the training data instead of learning the underlying pattern.
- Example: A student who memorizes answers to specific questions but fails when faced with new problems.
2. Underfitting (High Bias, Low Variance)
- The model is too simple to capture the underlying patterns in the data.
- Training performance: Poor (high bias).
- Testing performance: Also poor, but it generalizes slightly better than an overfit model (low variance).
- Why? The model oversimplifies the problem, missing key trends.
- Example: Trying to predict house prices using only "number of bedrooms" while ignoring location, size, and age.
(Note: Underfitting does not perform "great" on testing sets—it performs poorly on both. However, it generalizes better than an overfit model because it doesn’t latch onto noise.)
3. Balanced Model (Low Bias, Low Variance)
- The model learns the true patterns without overcomplicating or oversimplifying.
- Training & Testing performance: Both are strong.
- Why? It captures the signal while ignoring noise.
- Example: A student who understands core concepts and can solve both familiar and new problems.
Key Clarifications
✅ Overfitting: Good on training, bad on testing (memorization).
✅ Underfitting: Bad on training, bad on testing (oversimplification).
✅ Balanced Model: Good on both (generalizes well).
Understanding Bias and Variance a bit more:
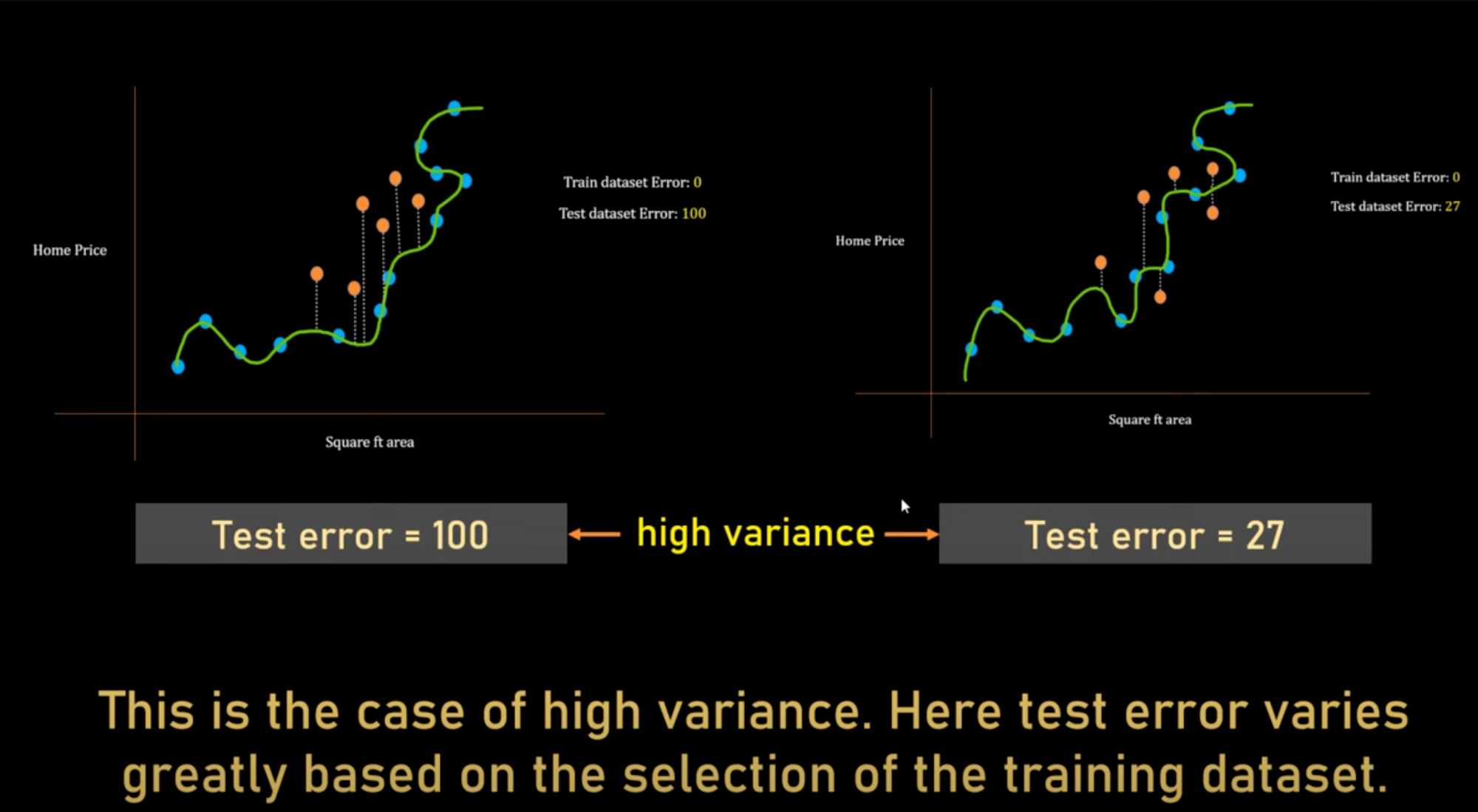
Understanding Variance can be a bit tricky.
Firstly, when we talk about Variance, we talk about testing a dataset, and here in the above picture, we have chosen a complex model that learns the pattern of the training dataset, so the bias is low as there is no training error here.
Variance doesn't mean that if your model is not working well in the testing dataset, it means that if we take random testing sets for training and testing, how random your test error would be, because it overfits so that it remembers the data rather than making patterns.
See patterns below.
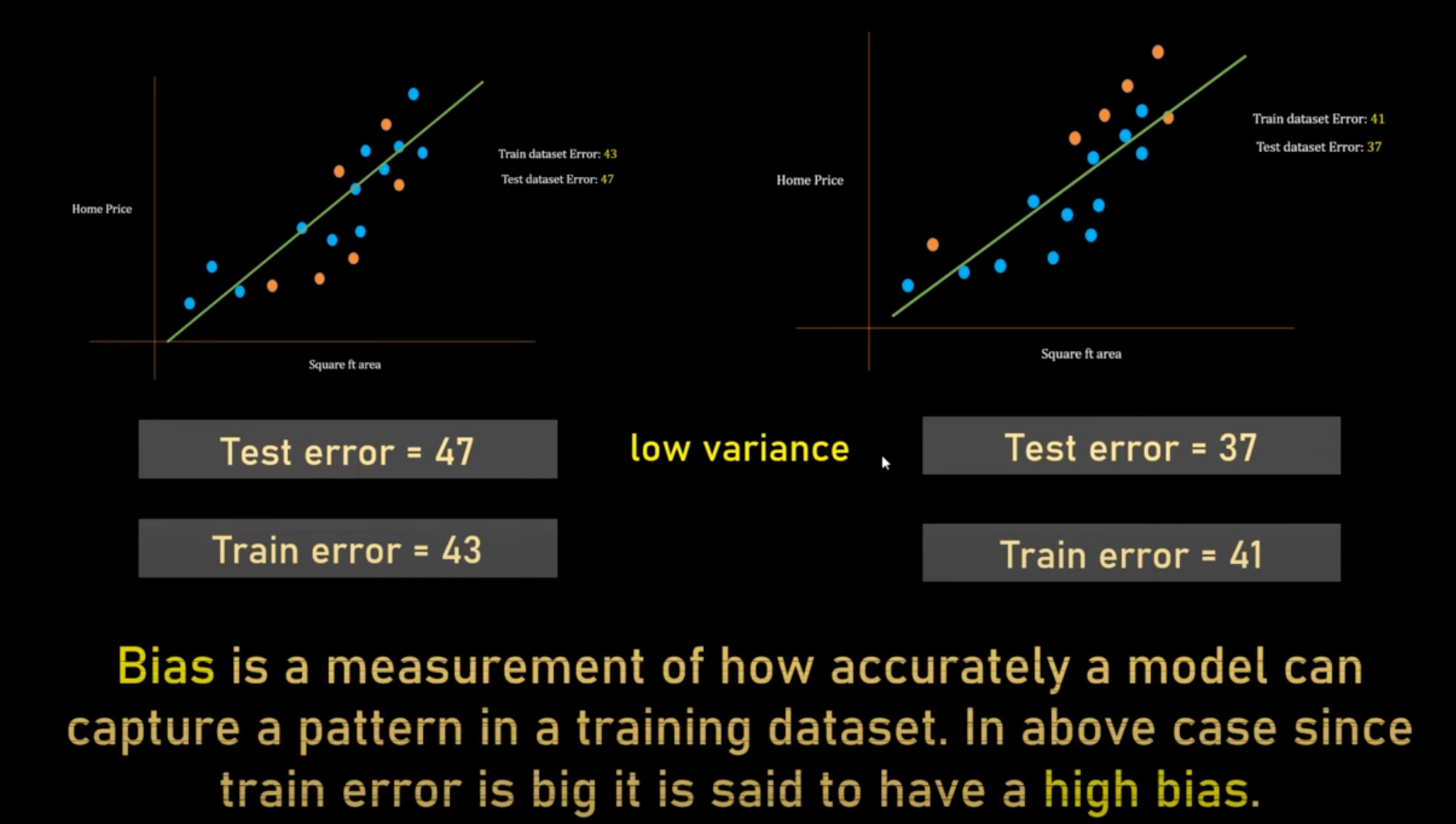
If you are talking about High/Low Bias, think of it as you are talking about the Training data. Here, the variance between two Test errors [which ultimately will be measured in Test data] is less because even if you take random data sets for testing and training, the variance [difference between] test errors won't vary much.
but it has high Bias also as the straight line can't make better predictions of testing data as well.
Underfitting = High bias, Low variance — poor performance on both training and testing data due to oversimplification.
Overfitting = Low bias, High variance — great on training, poor on testing due to overcomplexity and noise fitting.
Finding the Sweet Spot
📊 The Bias-Variance Tradeoff
This is the delicate balancing act in machine learning:
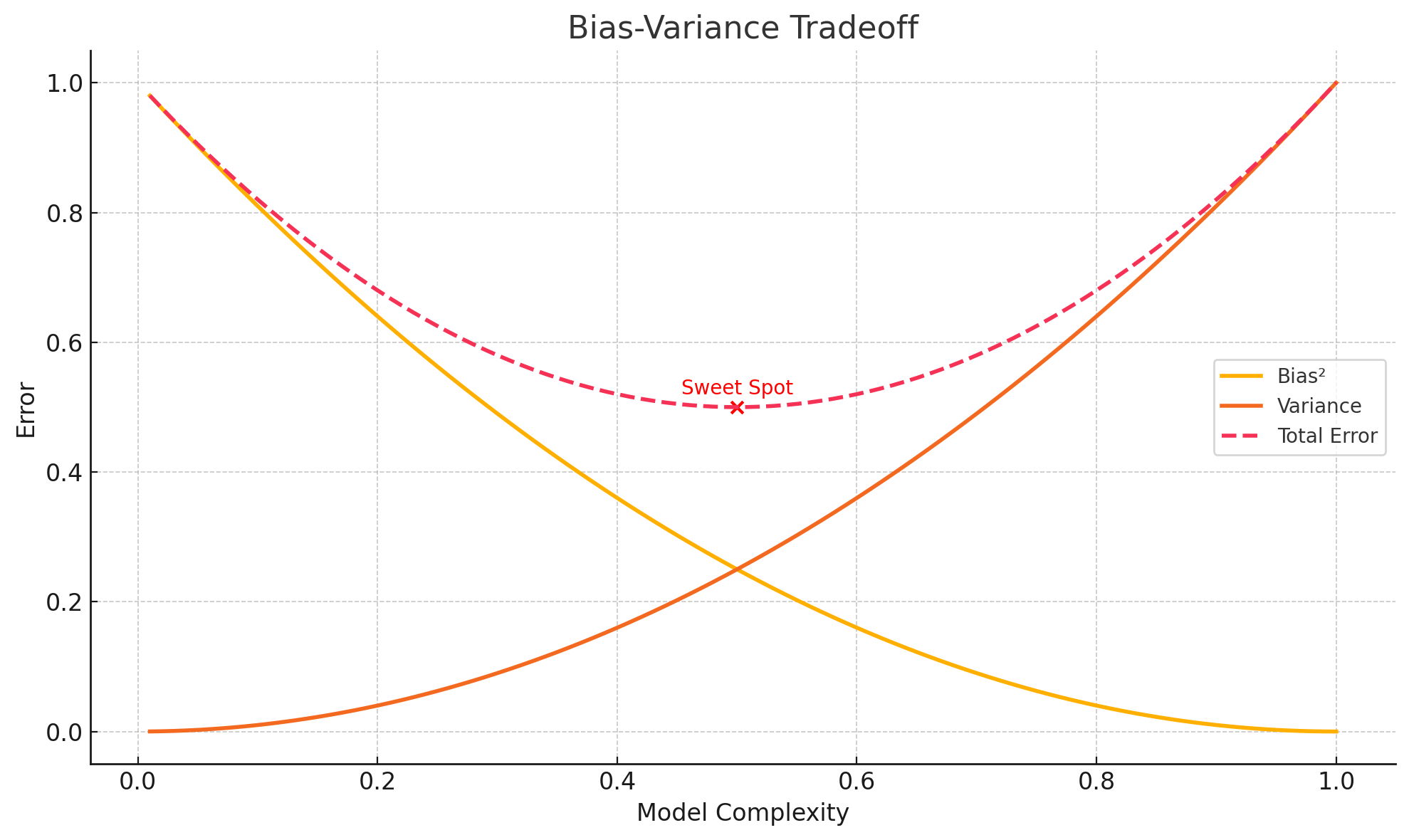
- 📉 Bias decreases as model complexity increases
- 📈 Variance increases with complexity
- 🔁 Total Error is minimized at the sweet spot, where the model is balanced
Achieving a low bias and low variance model often requires tuning and robust techniques.
✨ Regularization
- Penalizes large coefficients or complexity (e.g., L1/L2 penalties).
- Prevents the model from becoming too flexible.
✨ Boosting
- Sequentially builds an ensemble of weak learners to correct previous errors.
- Reduces both bias and variance with enough iterations.
✨ Bagging
- Builds multiple models on different training subsets (bootstrap sampling).
- Reduces variance by averaging predictions.
“Three commonly used methods for finding the sweet spot between simple and complicated models are regularization, boosting, and bagging.”
We will talk about them separately in the next blog.
Final Thoughts
- Bias is all about training error.
- Variance is all about testing error.
- Underfitting: High bias, low variance — consistently bad.
- Overfitting: Low bias, high variance — unstable.
- Balanced Model: Low bias + low variance = generalizes well.
“In machine learning, the ideal algorithm has low bias to capture the true relationship and low variance to produce consistent predictions across different datasets.”
This comprehensive understanding will help you build models that not only perform well but also make reliable, real-world predictions.
A few best videos to Learn the above concepts in detail: