Core Machine Learning Concepts Part 5 - Word Embeddings - How AI Understands the Meaning of Words
AI's secret sauce for understanding language—turning words into powerful numerical vectors that capture meaning, context, and even creativity
Introduction: The Language Processing Pipeline
For AI to understand human language, it must first break down text into manageable pieces and then represent those pieces numerically. This process involves two crucial steps: tokenization (splitting text into units) and word embeddings (representing those units mathematically). Together, they form the foundation of modern NLP.
Human language is complex. Words can have multiple meanings (e.g., "bank" = financial institution or riverbank), and relationships between words (e.g., "king" → "queen") are not obvious to machines. Traditional AI systems treated words as isolated symbols, leading to poor understanding. Word embeddings changed everything by representing words as numerical vectors that capture meaning, context, and relationships.
1. Tokenization: The First Step in NLP
What is Tokenization?
Tokenization is the process of splitting text into smaller units called tokens, which can be:
- Words ("cat", "running")
- Subwords ("un", "happy")
- Characters ("c", "a", "t")
Why Tokenization Matters
- Converts raw text into processable units
- Handles punctuation and special characters
- Prepares text for embedding models
The Embedding Process
- Tokenize the input text
- Convert tokens to numerical IDs
- Map IDs to embedding vectors
- Process through neural networks
Try it by yourself with: https://platform.openai.com/tokenizer
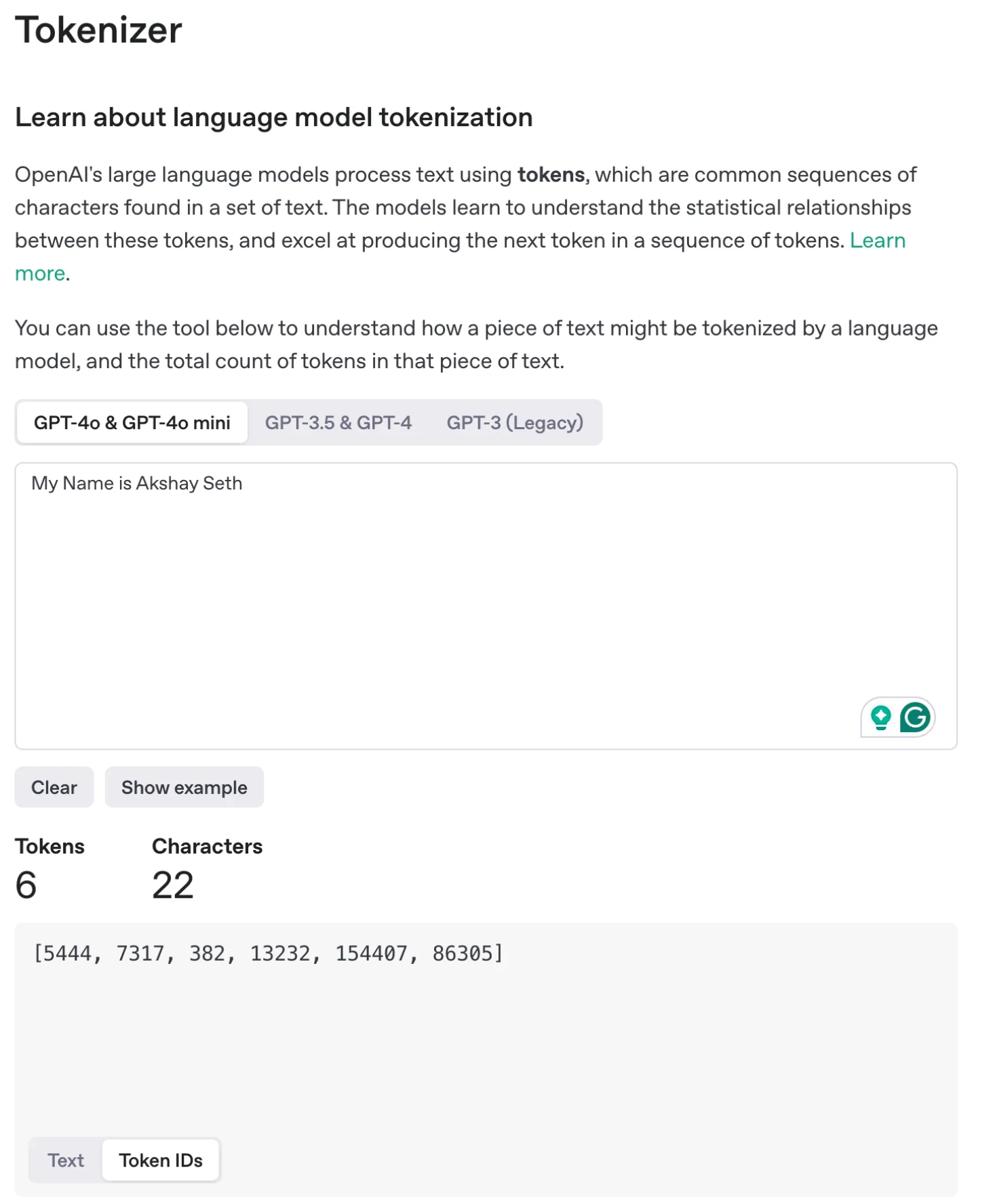
Example: ‘My Name is Akshay Seth’ has 6 tokens.
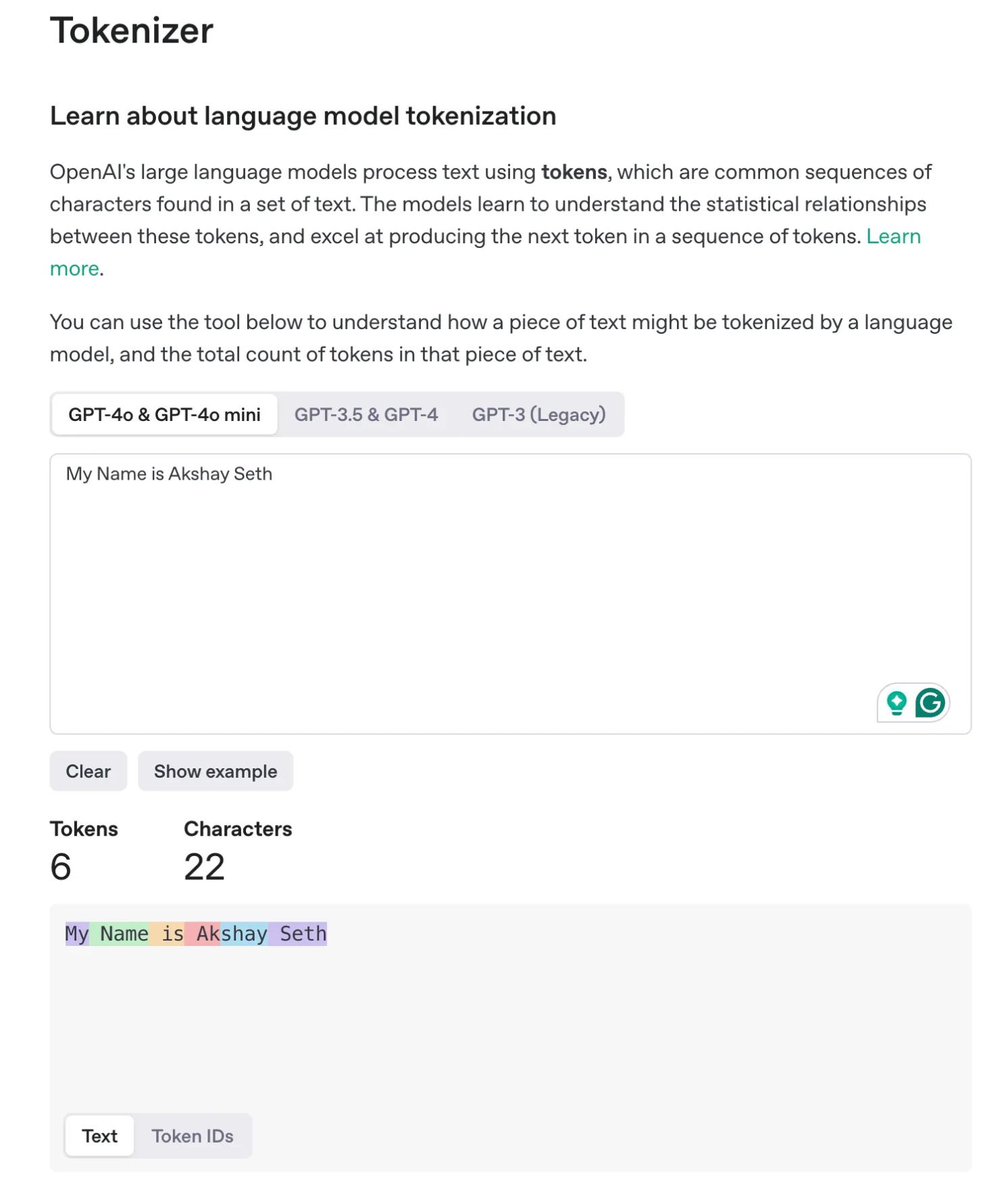
**A helpful rule of thumb is that one token generally corresponds to ~4 characters of text for common English text. This translates to roughly ¾ of a word (so 100 tokens ~= 75 words).
Understanding Word Embeddings
What Are Word Embeddings?
Numerical representations of words in high-dimensional space (usually 50-1000 dimensions) where:
- Similar words are close together
- Opposite words are far apart
- Relationships are preserved (e.g., king - man + woman ≈ queen)
Example: Word2Vec Embeddings
| Word | Vector (Simplified) |
|---|---|
| King | [0.5, -0.2, 0.7] |
| Queen | [0.48, -0.19, 0.69] |
| Apple | [-0.3, 0.8, 0.1] |
In the same example of tokens, OpenAI has assigned below word embeddings for ‘My name is Akshay Seth’
"Ever wondered how AI sees words? Let's explore the hidden geometry of language in multidimensional space!"
The TensorFlow Embedding Projector reveals how words transform into mathematical vectors stored in vector databases. Here's your quick guide:
- Open the portal: Go to projector.tensorflow.org
- Load embeddings: Try "Word2Vec All" (10K English words)
- Rotate: Click+drag
- Zoom: Mouse wheel
- Find words: Search box
Navigate space:
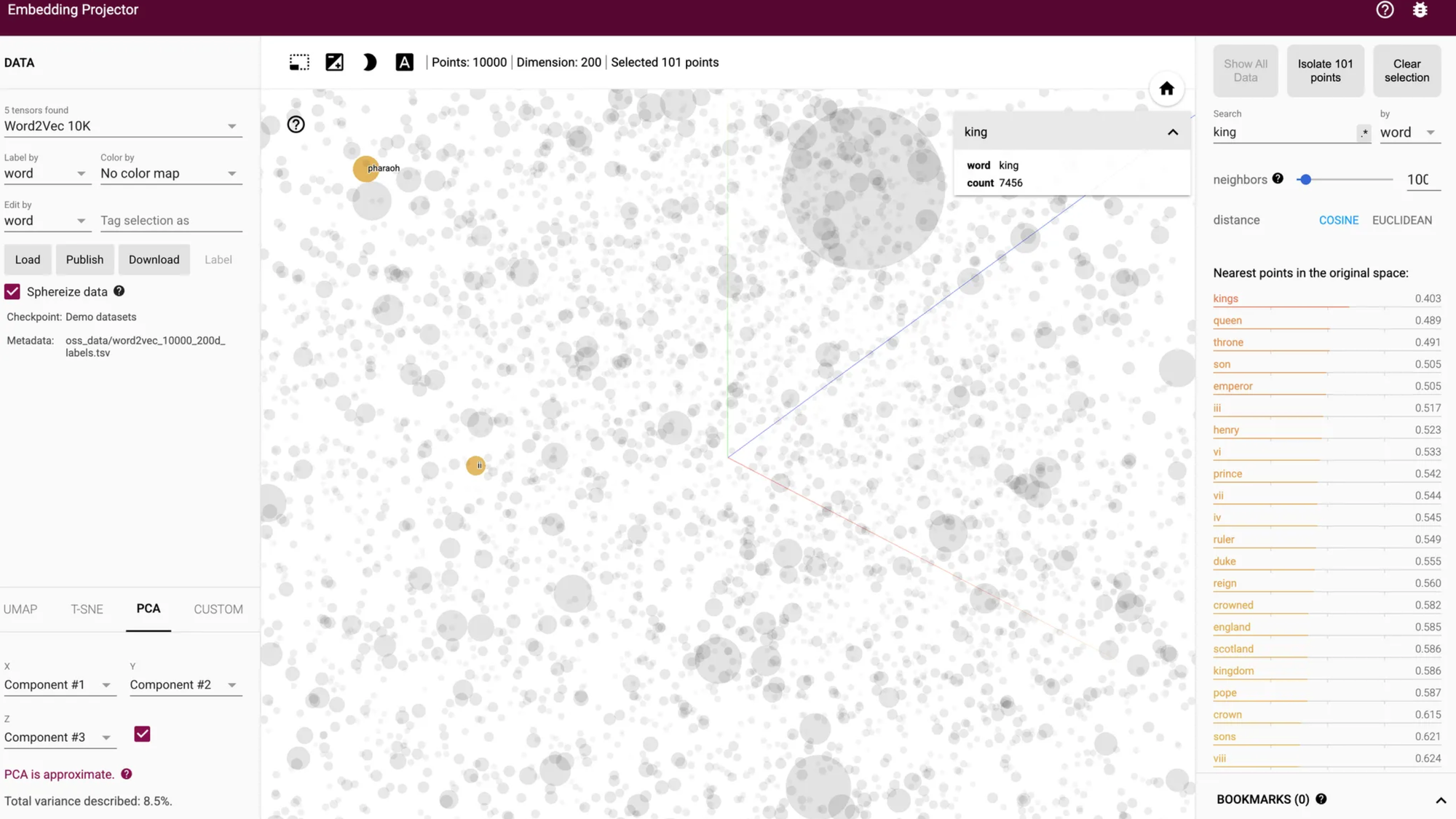
See relationships:
- "king" → "queen" (similar)
- "hot" → "cold" (opposites)
- Change views: Switch between PCA/t-SNE projections
- Database insight: Each point is a word vector stored in vector DBs like Pinecone
Pro tip: Upload your own embeddings (save as TSV) to visualize custom datasets!
"Words become coordinates in AI's conceptual universe!" 🌌
3. How Word Embeddings Are Created
Method 1: Word2Vec (2013)
- Skip-gram: Predicts surrounding words from target
- CBOW: Predicts target word from context
Method 2: GloVe (2014)
Uses global word co-occurrence statistics
Method 3: Contextual Embeddings (BERT, GPT)
Generates different embeddings based on context
Useful videos to understand them all in detail: