Core Machine Learning Concepts Part 6 - Ensemble Methods & Regularization
Smart models don't memorize—they generalize
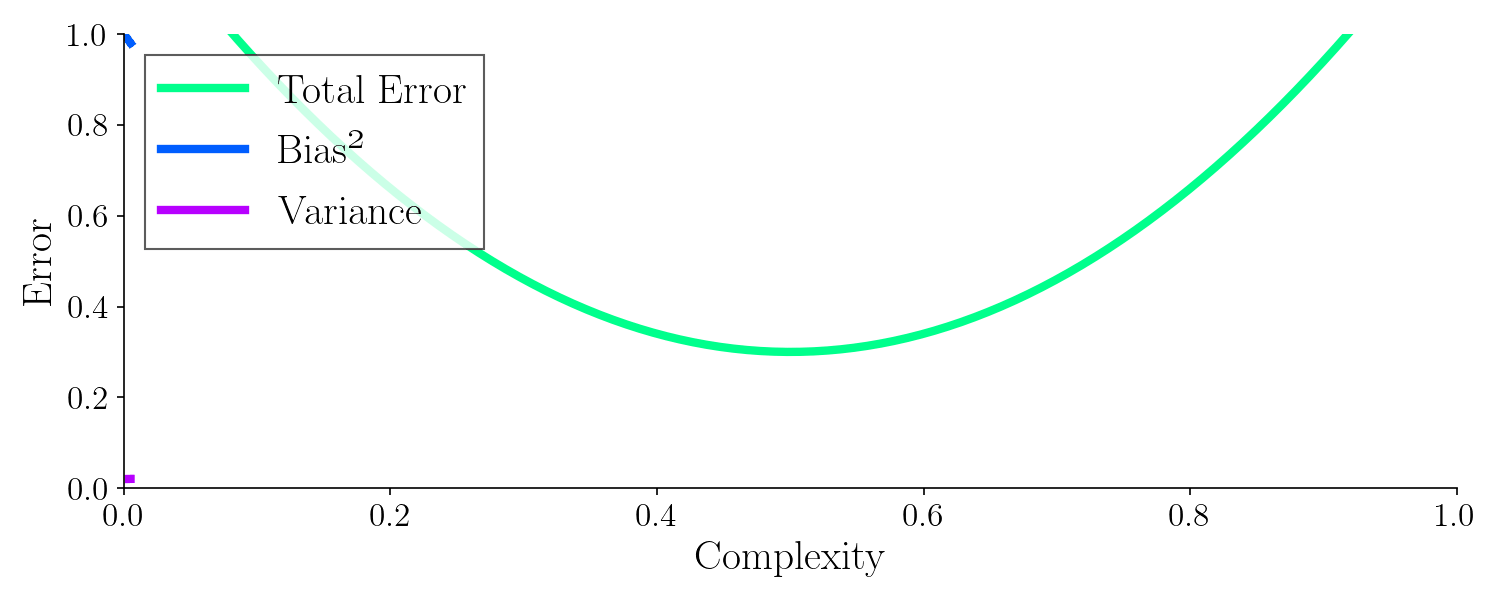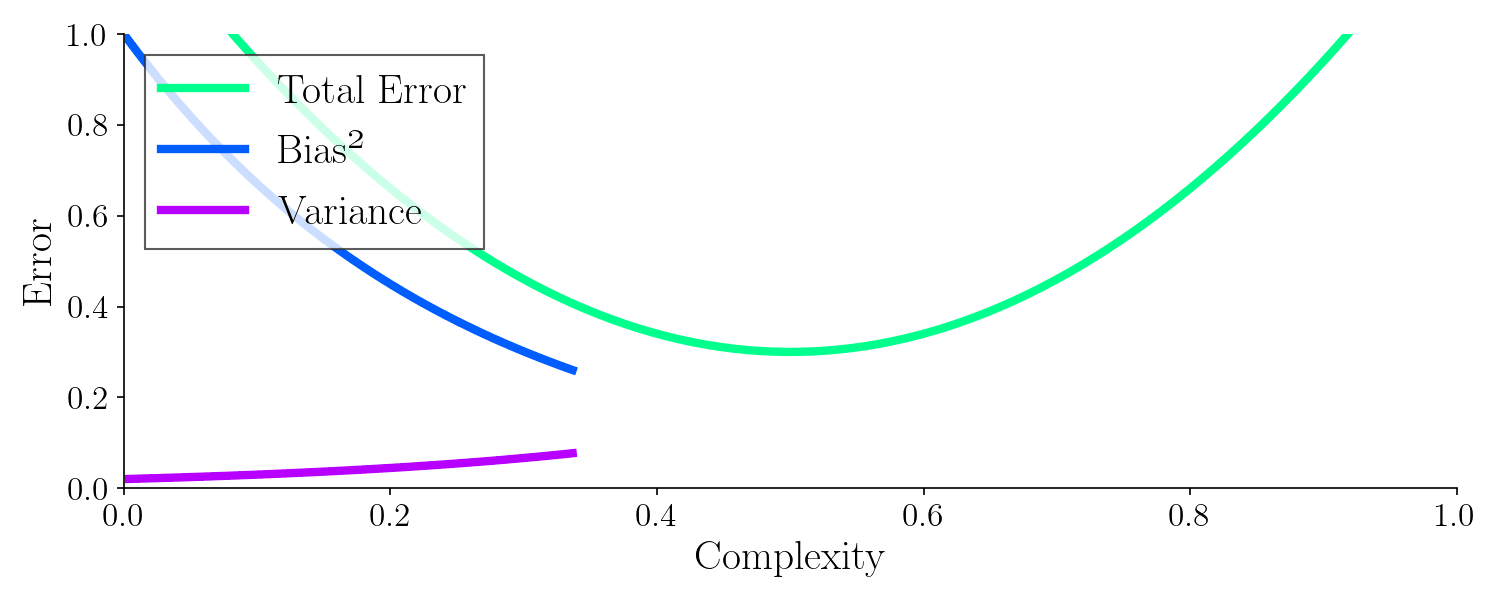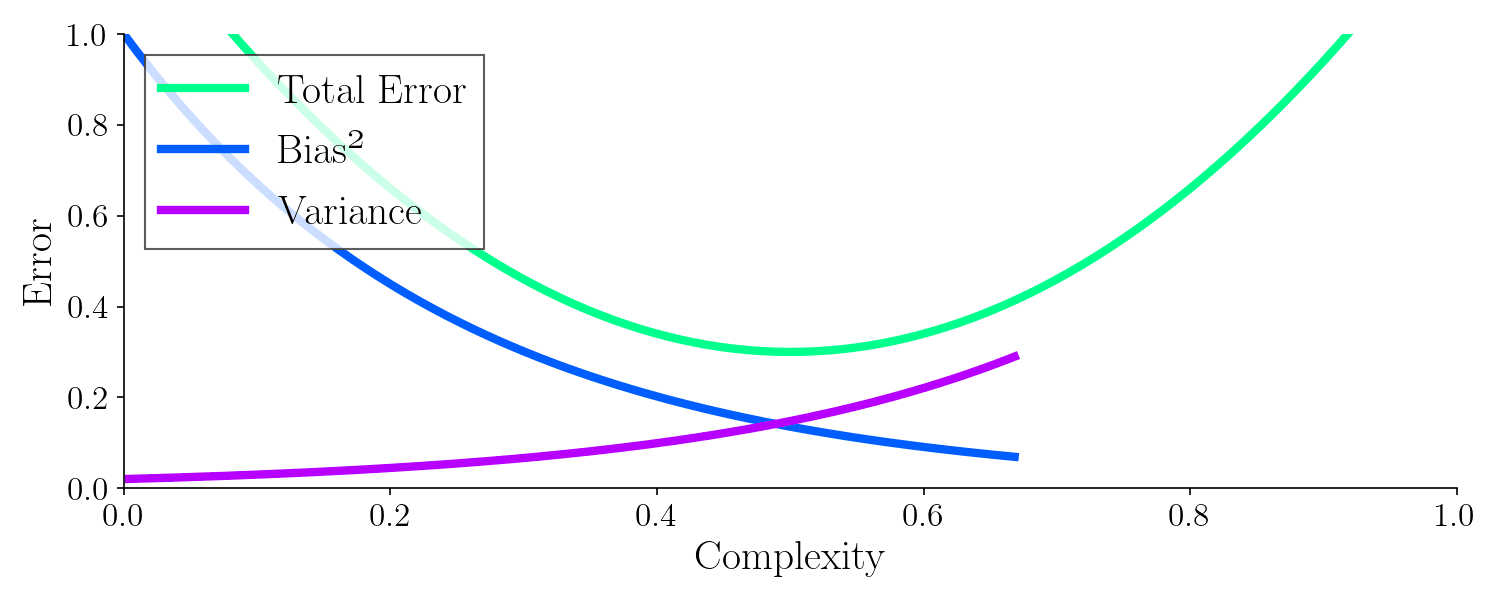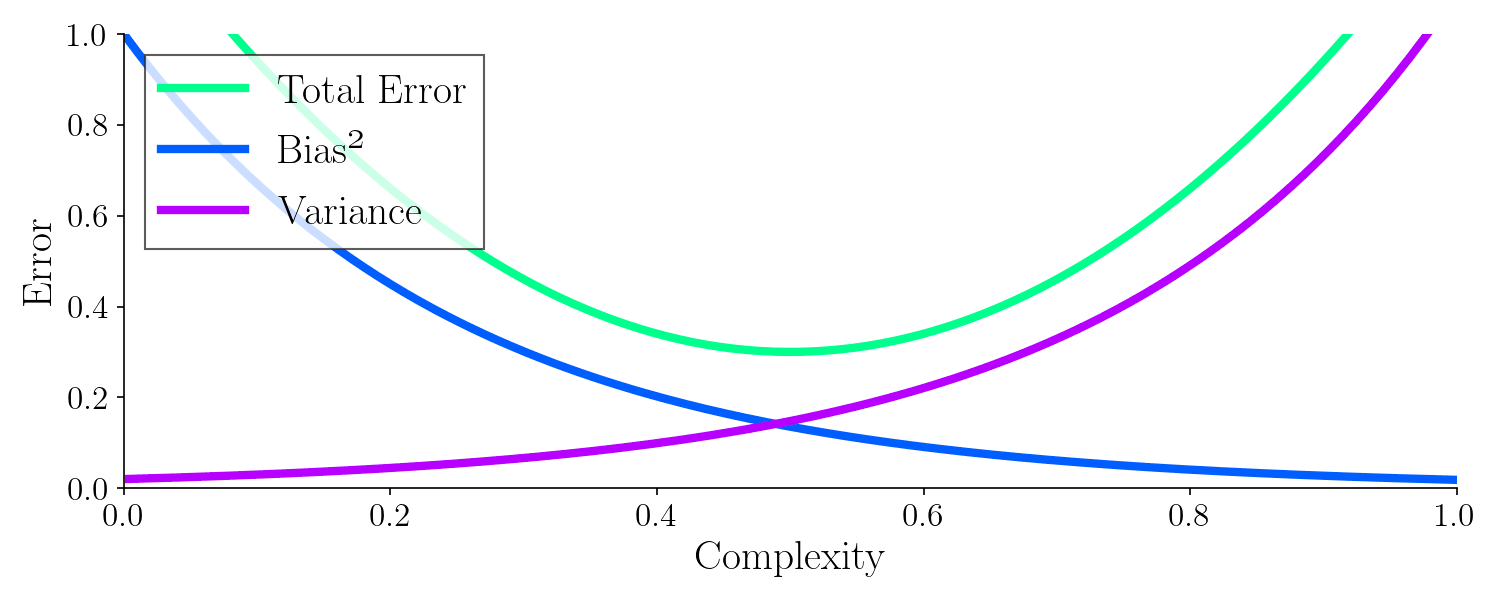
To build an optimal model, we need to achieve both low bias and low variance, avoiding the pitfalls of underfitting and overfitting. This balance typically requires careful tuning and robust modeling techniques.
Imagine you're teaching two students:
- Student A (The Overachiever)
- Memorizes every example perfectly
- Scores 100% on practice tests
- But fails completely on new, unseen questions
- AI Equivalent: Overfitting (perfect on training data, poor on test data)
- Student B (The Under-performer)
- Doesn't learn patterns well
- Scores poorly on both practice tests and real exams
- AI Equivalent: Underfitting (bad on both training and test data)
The Goldilocks Solution:
We want Student C who:
- Learns general patterns (not just memorization)
- Performs well on both practice tests and new questions
- AI Equivalent: Properly regularized model that generalizes well
🔍 Key Clarifications:
- Overfitting:
- ✅ Excellent training performance
- ❌ Terrible test performance
- Like memorizing answers instead of understanding concepts
- Underfitting:
- ❌ Poor training performance
- ❌ Poor test performance
- Like not studying enough to learn even basic patterns
- Good Fit:
- ✅ Good training performance
- ✅ Good test performance
- Achieved through proper regularization
Bias-Variance Tradeoff
Every AI model faces this fundamental challenge:
| Problem | What Happens | Result |
|---|---|---|
| High Bias | Model is too simple | Underfitting (misses patterns) |
| High Variance | Model is too complex | Overfitting (memorizes noise) |
Methods to determine the sweet spot:
1. Ensemble Methods
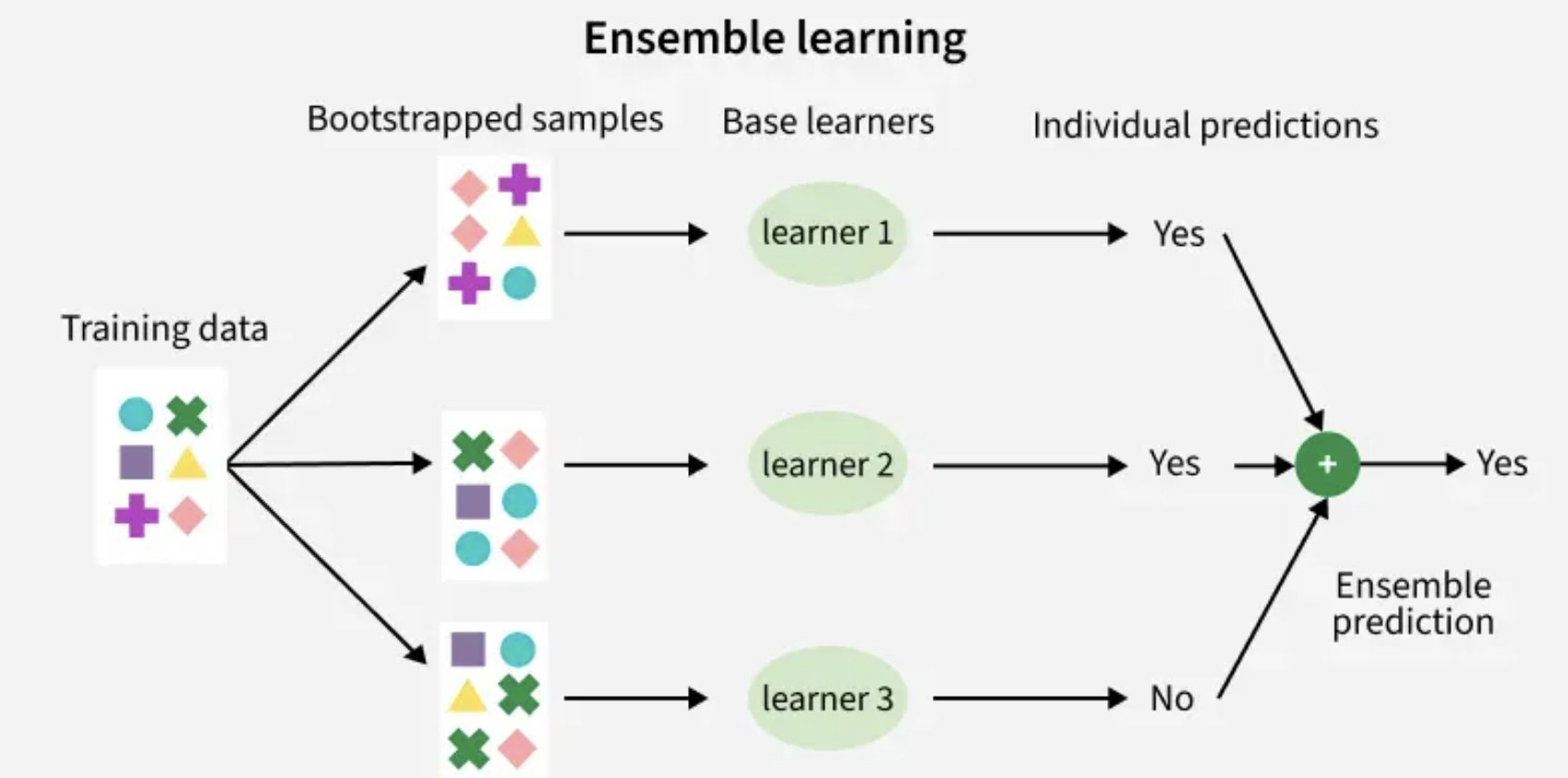
Ensembles combine multiple models to create a stronger, more stable predictor. Think of it like a team of experts working together instead of relying on one opinion.
a. Bagging (Bootstrap Aggregating)
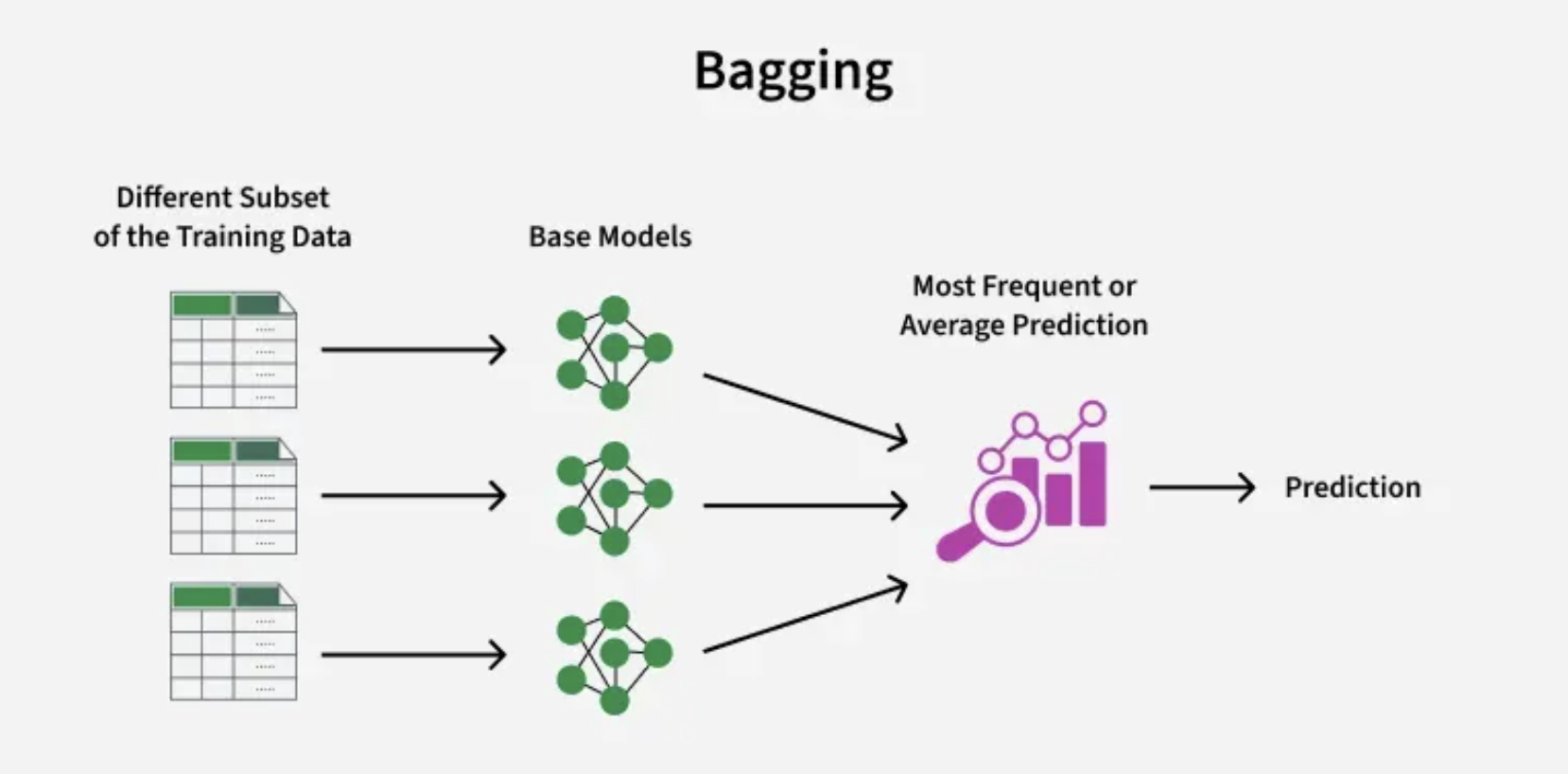
Concept: "Many independent voices voting together"
- Creates multiple versions of the dataset through random sampling (with replacement)
- Trains a separate model on each version
- Combines results through voting (classification) or averaging (regression)
Why it works: Reduces variance by preventing any single model from dominating
Real-world analogy: Like asking 10 doctors for a diagnosis and taking the most common opinion
Best for: High variance models (deep trees, complex models)
Some data samples are left out of the training set for certain base models when using the bootstrapping method. These "out-of-bag" samples can be used to evaluate the model’s performance without needing cross-validation.
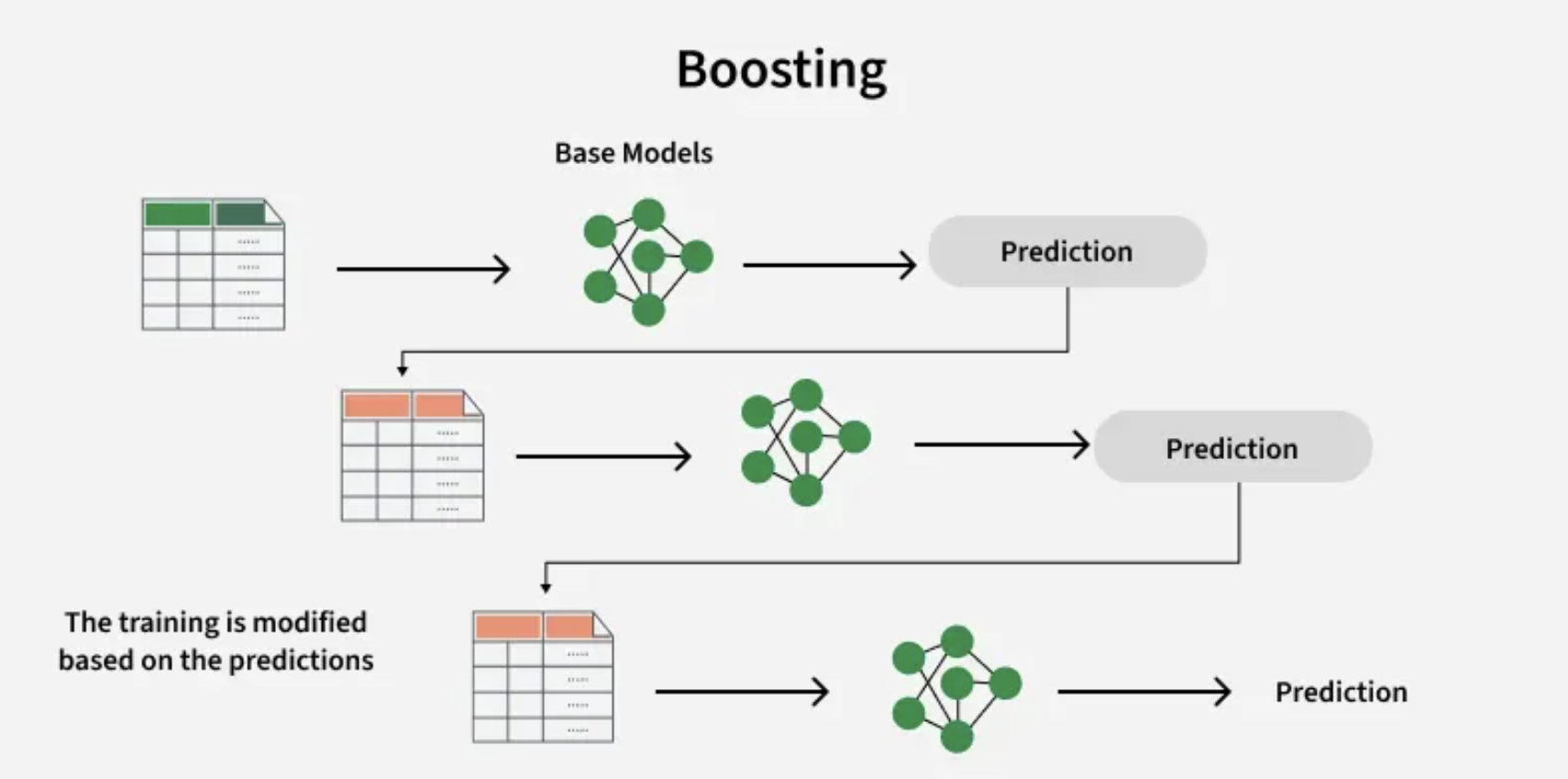
b. Boosting
Concept: "Learn from your mistakes"
Boosting is an ensemble technique that combines multiple weak learners to form a strong learner. Weak models are trained in sequence, with each new model attempting to correct the errors made by the previous one. This process continues until the model performs well on the training data.
One of the most well-known boosting algorithms is AdaBoost (Adaptive Boosting).
Overview of the Boosting Algorithm:
- Initialize Weights: Start by assigning equal weights to all training examples.
- Train First Weak Learner: Fit a weak model (commonly a decision tree) to the weighted dataset.
- Sequential Learning: Train models one after another. Each model focuses on the examples that were misclassified by the previous model.
- Update Weights: After each round, increase the weights of the misclassified examples so that the next learner focuses more on them.
Why it works: Reduces bias by iteratively improving on weaknesses
c. Stacking
Concept: "The wisdom of crowds"
- Trains multiple different models (e.g., decision tree, SVM, neural network)
- Uses another model (meta-learner) to learn how to best combine their predictions
Why it works: Leverages strengths of different algorithms
Real-world analogy: Like having a panel of experts (doctor, nutritionist, trainer) advise a patient, with a head doctor making the final decision
2 .L1 vs L2 Regularization
While ensembles combine models, L1/L2 work within a single model to keep it disciplined.
| Technique | How It Works | Best For |
|---|---|---|
| L1 (Lasso) | Shrinks some coefficients to exactly zero | Feature selection (when you have many features but suspect only some matter) |
| L2 (Ridge) | Shrinks all coefficients smoothly | General cases where you want to prevent any single feature from dominating |
Key difference: L1 can eliminate unimportant features, while L2 just makes all features smaller.
💻 Practical Example: Loan Default Prediction
Let's see these concepts in action with our sample loan dataset.
1. Data Preparation
import pandas as pd
from sklearn.model_selection import train_test_split
# Load data
df = pd.read_csv("loan_default_60.csv")
# Features & target
X = df.drop("Default", axis=1)
y = df["Default"]
# Split data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
2. Comparing Models
from sklearn.metrics import accuracy_score
# Single Decision Tree
tree = DecisionTreeClassifier()
tree.fit(X_train, y_train)
tree_acc = accuracy_score(y_test, tree.predict(X_test))
# Bagging
bag_acc = accuracy_score(y_test, bag_model.predict(X_test))
# Boosting
boost_acc = accuracy_score(y_test, boost_model.predict(X_test))
print(f"Single Tree: {tree_acc:.2f}")
print(f"Bagging: {bag_acc:.2f}")
print(f"Boosting: {boost_acc:.2f}")
Typical Results:
- Single Tree: 65-75% accuracy
- Bagging: 75-85% accuracy
- Boosting: 80-90% accuracy
📊 Key Takeaways
- Ensemble Methods work by combining multiple models:
- Bagging reduces variance (good for complex models)
- Boosting reduces bias (good for weak models)
- Stacking leverages different algorithms' strengths
- Regularization techniques:
- L1 (Lasso) for feature selection
- L2 (Ridge) for general smoothing
- In Practice:
- Start with simple models
- Use ensembles when you need better performance
- Apply regularization to prevent overfitting
🧠 Remember: The best model isn't necessarily the most complex one, but the one that generalizes best to new data