[Day 14] Supervised Machine Learning Type 5 - k-Nearest Neighbors (k-NN) Algorithm (with a Small Python Project)
No training, just intuition—k-NN predicts like a pro using your nearest data points. Discover how it works with fruits & shopping habits!
![[Day 14] Supervised Machine Learning Type 5 - k-Nearest Neighbors (k-NN) Algorithm (with a Small Python Project)](https://storage.ghost.io/c/55/e8/55e827ca-bf8d-4eee-bdb4-ee48e49a011a/content/images/size/w2000/2025/03/_--visual-selection--16-.svg)
Understanding k-Nearest Neighbors (k-NN) in Machine Learning
k-Nearest Neighbors (k-NN) is a simple and effective machine learning that makes predictions based on the majority class or average value of its nearest neighbors in the dataset.
In classification tasks, k-NN assigns a label to a data point based on the most common label of its k nearest neighbors. In regression tasks, k-NN predicts the output as the average of the values of its k nearest neighbors.
What makes k-NN special is its simplicity—there are no explicit training steps, as the model just stores the training data and makes predictions by comparing new data to the stored points.
Videos to watch for better understanding:
1:
2:
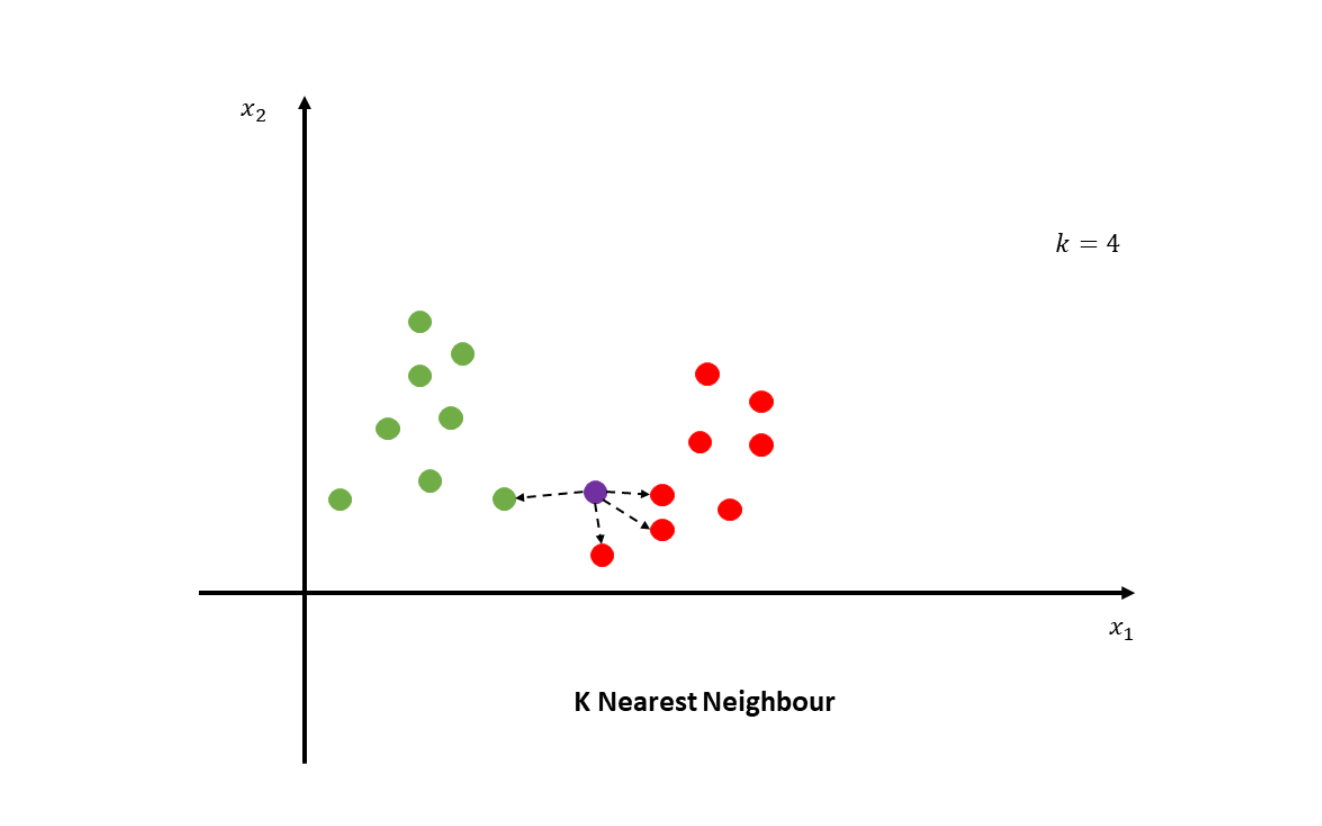
How Does k-Nearest Neighbors Work?
- Choose the Number of Neighbors (k): The first step in k-NN is selecting the number of neighbors, k, that will be used to make predictions. A smaller k makes the model sensitive to noise, while a larger k might over-smooth the data.
- Measure the Distance:For each new data point, k-NN calculates the distance between that point and all other points in the dataset. Common distance measures include Euclidean distance (straight-line distance) and Manhattan distance (distance along axes).
- Find the Nearest Neighbors:The algorithm selects the k closest data points based on the calculated distance.
- Make Predictions:
- For classification: The class label that appears the most among the k neighbors is assigned to the new point.
- For regression: The predicted value is the average of the values of the k neighbors.
Key Metrics in k-NN
- Distance Metric: The most commonly used metric to measure the "closeness" between points is Euclidean distance, which calculates the straight-line distance between two points in a multi-dimensional space. For example, in two dimensions:
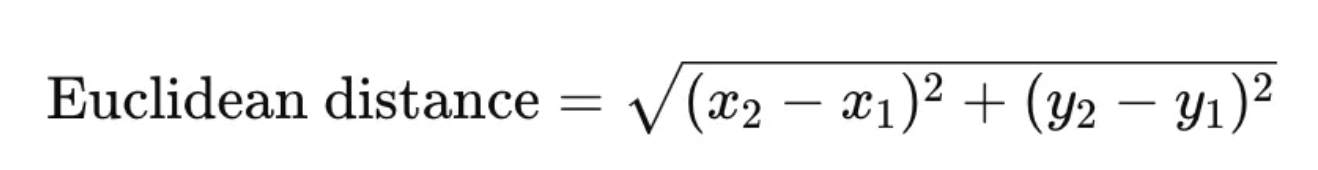
- Other metrics like Manhattan distance or Cosine similarity can also be used depending on the problem.
- Choosing the Value of k:The choice of k affects the model’s performance. A small k makes the model sensitive to noise, while a large k can lead to a smoother decision boundary. Typically, k is chosen based on experimentation or using techniques like cross-validation.
Stopping Criteria in k-NN
k-NN doesn't involve training in the traditional sense; instead, it works by comparing the new data point to the entire dataset. There are no stopping criteria for training, but some key decisions include:
- Choosing k:The value of k is typically chosen through experimentation, often by testing different k values and using cross-validation to select the best one.
- Distance Threshold:In some cases, you can set a distance threshold to ignore neighbors that are farther away than a certain distance, but this is optional.
Example: Classifying Fruits Based on Weight and Size
Let’s say you want to classify fruits based on weight and size. You have data for apples and oranges, and you want to predict whether a new fruit is an apple or an orange.
Here’s how the data might look:
| Weight (g) | Size (cm) | Fruit |
|---|---|---|
| 150 | 7 | Apple |
| 170 | 8 | Apple |
| 180 | 8 | Apple |
| 130 | 6 | Orange |
| 120 | 5 | Orange |
| 110 | 5 | Orange |
A k-NN algorithm might classify a new fruit by checking the k nearest fruits in the dataset and determining the most common fruit type among those neighbors.
Why Use k-Nearest Neighbors?
- Simplicity:k-NN is one of the simplest machine learning algorithms, requiring minimal training and easy implementation. It’s great for problems where the decision boundaries are not necessarily linear.
- Versatility:k-NN can be used for both classification and regression tasks, making it a versatile choice for different types of problems.
- No Assumptions About Data:k-NN makes no assumptions about the underlying data distribution, making it a non-parametric method. It works well when the data is irregular or does not follow a specific pattern.
Limitations of k-Nearest Neighbors
- Computationally Expensive:Since k-NN needs to compare the new data point to all the training data, it can become slow, especially with large datasets. The model doesn’t "train" in the traditional sense but rather stores the data.
- Sensitive to Noise:k-NN is sensitive to irrelevant features or noise in the data. Choosing the right features and normalizing the data is important for performance.
- Curse of Dimensionality:k-NN doesn’t perform well in high-dimensional spaces because the distance between points becomes less meaningful as the number of dimensions increases. This problem is known as the curse of dimensionality.
Quick Python Project
Predicting Product Purchase (Buy/Not Buy)
Dataset Example:
| Age | Income | Purchase Decision |
|---|---|---|
| 25 | 30,000 | Not Buy |
| 32 | 50,000 | Buy |
| 40 | 60,000 | Buy |
| 28 | 40,000 | Not Buy |
| 45 | 75,000 | Buy |
| 38 | 80,000 | Buy |
| 50 | 120,000 | Not Buy |
| 60 | 90,000 | Not Buy |
We’ll use k-NN to predict if a customer will buy a product or not based on their age and annual income.
Solution:
Here’s the simple k-NN code for the above project:
Python Code:
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
# Upload the CSV file
df = pd.read_csv("age_income.csv")
# Remove commas from the 'Income' column and convert it to numeric
df['Income'] = df['Income'].replace({',': ''}, regex=True).astype(float)
# Define the features (X) and target (y)
X = df[['Age', 'Income']] # Features
y = df['Purchase Decision'] # Target variable
# Create and train the k-NN model
model = KNeighborsClassifier(n_neighbors=3) # k = 3
model.fit(X.values, y)
# Make a prediction for a new customer
new_customer = [[35, 70000]] # Example: Age = 35, Income = 70,000$
prediction = model.predict(new_customer)
print(f"Predicted purchase decision for the new customer: {prediction[0]}")
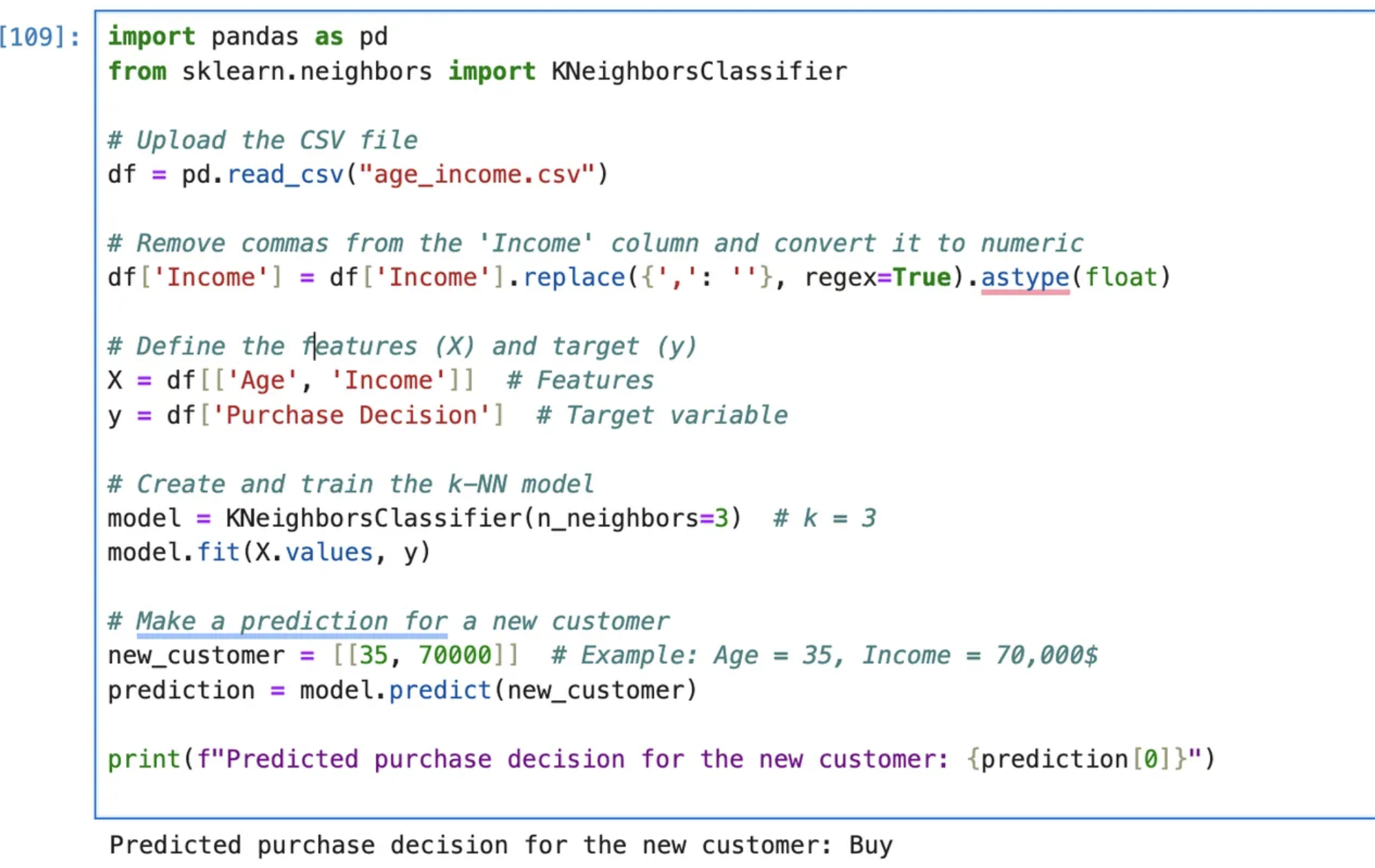
Model Prediction:
- Sample input: Age: 35, Income: 70,000
Model Prediction: BUY
See the code below with the prediction shown at the bottom.
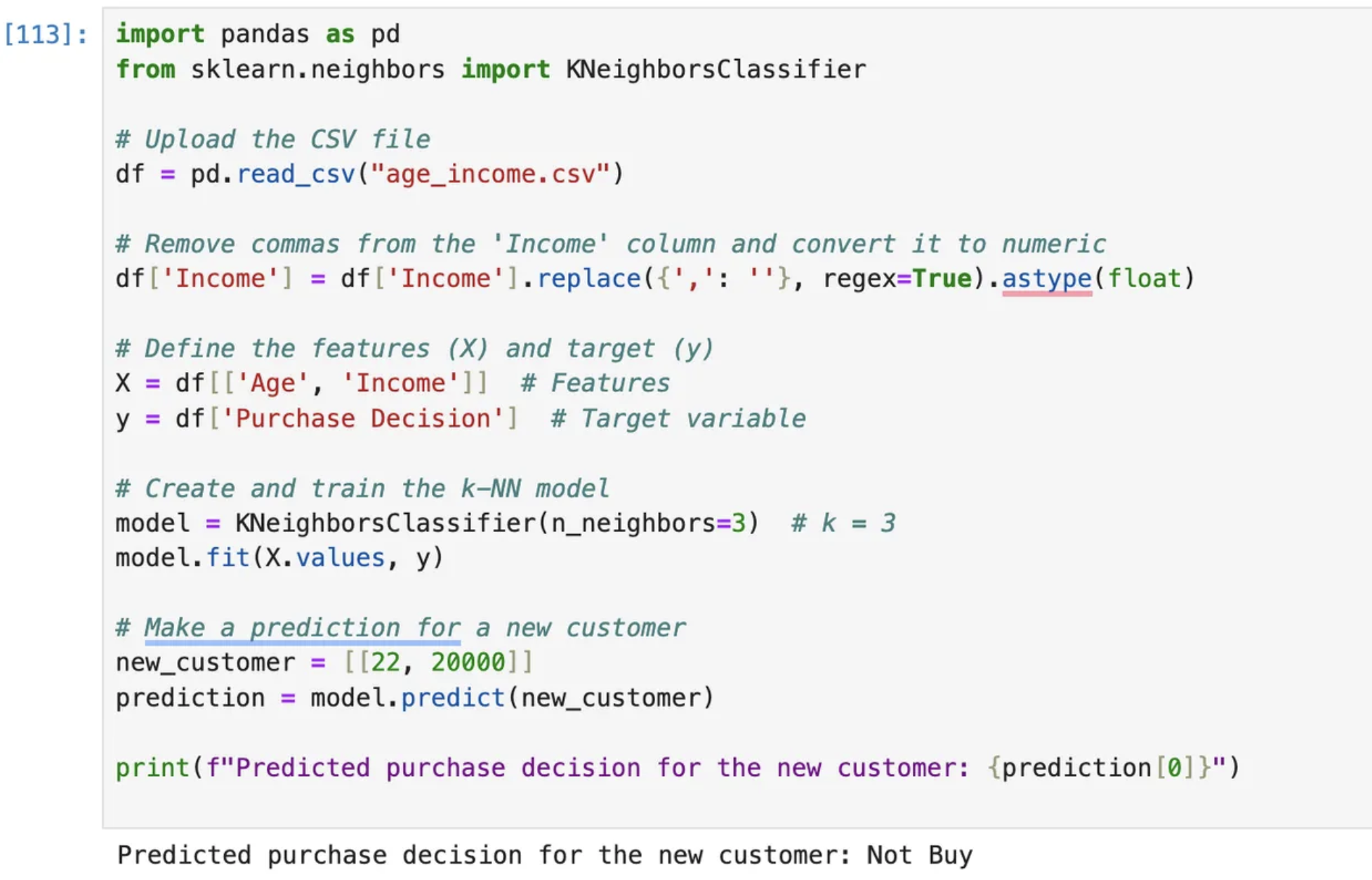
- Sample Input: Age: 22, Income: 20,000
Model Prediction: NOT BUY
explanation
Code explanation:
1. Import Required Libraries
import pandas as pd
from sklearn.neighbors import KNeighborsClassifier
pandas: This is a popular data manipulation library that allows us to load, clean, and handle data in tabular format (DataFrames).KNeighborsClassifier: This is the k-Nearest Neighbors (k-NN) classification model from thesklearn.neighborsmodule. It is used for classification tasks, where it predicts a label based on the majority class of its k nearest neighbors.
2. Load the Dataset
df = pd.read_csv("age_income.csv")
pd.read_csv("age_income.csv"): This line loads the dataset from a CSV file named "age_income.csv" into a pandas DataFrame (df). The DataFrame will store the data in a structured format with rows and columns.- The dataset is assumed to have columns like "Age", "Income", and "Purchase Decision".
3. Data Cleaning: Remove Commas from 'Income' Column
df['Income'] = df['Income'].replace({',': ''}, regex=True).astype(float)
df['Income']: This accesses the "Income" column in the DataFrame.replace({',': ''}, regex=True): This removes any commas from the "Income" column. The commas are typically present in numerical data when represented as strings (e.g., "$30,000" becomes "30000").astype(float): After removing the commas, we convert the "Income" column to a float type, since k-NN and other machine learning algorithms require numerical data.
This ensures that the Income values are in a numerical format that can be used by the machine learning model.
4. Define Features (X) and Target (y)
X = df[['Age', 'Income']] # Features
y = df['Purchase Decision'] # Target variable
X = df[['Age', 'Income']]:Xis the feature matrix, which contains the input data used for prediction. It includes the "Age" and "Income" columns because we want to predict the purchase decision based on these two features.
y = df['Purchase Decision']:yis the target variable, which is the column we want to predict. In this case, it is the "Purchase Decision" (i.e., whether the customer bought the product or not). The target variable is typically categorical (e.g., "Buy" or "Not Buy").
5. Create and Train the k-NN Model
model = KNeighborsClassifier(n_neighbors=3) # k = 3
model.fit(X.values, y)
model = KNeighborsClassifier(n_neighbors=3):- This line creates a k-NN classifier model and specifies the value of k (the number of nearest neighbors). In this case, k=3, meaning that the model will look at the 3 closest data points to predict the class of a new point.
model.fit(X.values, y):- The
.fit()method trains the k-NN model using the feature matrix X (which includes Age and Income) and the target variable y (the Purchase Decision). X.valuesconverts the DataFrame X into a NumPy array, which is required by k-NN to perform calculations efficiently.
- The
6. Make a Prediction for a New Customer
new_customer = [[35, 70000]] # Example: Age = 35, Income = 70,000$
prediction = model.predict(new_customer)
new_customer = [[35, 70000]]:- This is an example of a new data point for which we want to make a prediction. It represents a customer who is 35 years old and has an annual income of $70,000.
- The input data is provided as a list of lists
[[35, 70000]]to match the format of the training data (i.e., two features: Age and Income).
prediction = model.predict(new_customer):.predict()is used to make predictions on new, unseen data. The model predicts whether this new customer will Buy or Not Buy the product based on the 3 nearest neighbors.predictionwill store the predicted label (either "Buy" or "Not Buy").
7. Output the Prediction
print(f"Predicted purchase decision for the new customer: {prediction[0]}")
prediction[0]:- Since
predictionis a list (or array) containing the predicted value for the new customer, we access the first element using[0]. This is the final predicted class ("Buy" or "Not Buy").
- Since
print(f"Predicted purchase decision for the new customer: {prediction[0]}"):- The prediction is printed out, showing whether the new customer is expected to buy or not buy the product.
Summary of the Steps:
- Import Libraries: Import necessary libraries for data manipulation and machine learning.
- Load Data: Load the dataset from a CSV file.
- Clean Data: Remove commas from the "Income" column and convert it to numerical values.
- Define Features and Target: Split the data into input features (X) and the target variable (y).
- Train the Model: Create and train the k-NN classifier with the data.
- Make Predictions: Predict the outcome for a new customer based on their age and income.
- Display Results: Output the prediction for the new customer.
This process involves cleaning the data, training a machine learning model, and making predictions based on the learned patterns.
💬 Join the DecodeAI WhatsApp Channel for regular AI updates → Click here