[Day 28] Reinforcement Learning Type 1 – Q-Learning (with a Practical Python Project)
Like a kid learning to ride a bike, Q-Learning helps AI master smart moves with a cheat sheet of rewards—no rules, just experience! 🚴♂️🤖
![[Day 28] Reinforcement Learning Type 1 – Q-Learning (with a Practical Python Project)](https://storage.ghost.io/c/55/e8/55e827ca-bf8d-4eee-bdb4-ee48e49a011a/content/images/size/w2000/2025/03/Q-L.svg)
🎯 What is Q-Learning?
Q-Learning is a clever reinforcement learning trick that teaches a machine to make smart choices by trial and error, like a kid learning to ride a bike. It’s all about figuring out the best actions to take in different situations to maximize rewards over time—no playbook needed. Instead of guessing blindly, it builds a “cheat sheet” (called a Q-table) that tracks which moves pay off the most.
It is a method where an agent learns to make decisions by trial and error. It figures out the best actions to take in different situations (states) to maximize a reward over time. It does this by building a "Q-table," which is like a cheat sheet telling the agent how valuable each action is in each state.
Key Concepts (The Basics)
- Agent: The learner (e.g., the dog).
- State (S): The situation the agent is in (e.g., "ball is 5 steps away").
- Action (A): What the agent can do (e.g., "run toward ball" or "sit").
- Reward (R): Feedback from the environment (e.g., +10 for fetching the ball, -1 for sitting).
- Q-Value: A score for each state-action pair, updated as the agent learns.
- Learning Rate (α): How much new info overrides old info (0 to 1, e.g., 0.1).
- Discount Factor (γ): How much future rewards matter (0 to 1, e.g., 0.9).
- Exploration vs. Exploitation: Should the agent try new things (explore) or stick to what it knows (exploit)?
The Q-Learning Formula
The heart of Q-learning is this update rule:
Q(s, a) = Q(s, a) + α [R + γ * max(Q(s', a')) - Q(s, a)]
- Q(s, a): Current Q-value for state s and action a.
- R: Immediate reward.
- γ * max(Q(s', a')): Best future reward from the next state s'.
- α: Learning rate to blend old and new info.

Picture a treasure hunter in a maze. Each step offers choices—left, right, or forward—and some lead to gold, while others hit dead ends. Q-Learning is like the hunter jotting down notes: “Left at the torch got me 5 coins, but right at the skeleton was a bust.” Over time, those notes get sharper, guiding them to the jackpot without needing a map upfront. It learns by doing, balancing exploration (trying new paths) and exploitation (sticking to what works).
Example: Imagine training a robot vacuum to clean your house. It bumps around, sucking up dust (reward!) or hitting walls (no reward). Q-Learning helps it learn: “Turn left at the couch, straight past the rug—more dust, less crashing.” It’s about mastering a task through experience.
👨💻 Real-World Use Case: Delivery Drone Navigation
Imagine you’re a logistics manager at a company like Amazon, tasking drones to deliver packages. The drone faces a city grid—streets, buildings, wind gusts. Its goal? Drop off packages fast while avoiding crashes and saving battery. Each flight gives data: time taken, distance flown, and obstacles hit.
Q-Learning steps in like a flight coach. It tracks choices—fly high, dodge left, land now—and scores them: “High over Main Street saved 2 minutes (+2 reward), but hitting a tree cost battery (-1).” Over many flights, it builds a Q-table saying, “At 5th Street, go up—best payoff.” No GPS guru required—it learns the optimal route by buzzing around and tweaking its moves.
Why Q-Learning Shines Here:
- Adapts to chaos: Handles changing winds or new buildings without a redo.
- Learns from scratch: No need for a perfect flight plan—just trial runs.
- Maximizes wins: Balances speed, safety, and power for top delivery stats.
- Scales up: Teach one drone, then copy the Q-table to a fleet.
⚡ Why Use Q-Learning? Real-World Style
- Master the Unknown: Got a task with no rulebook? Q-Learning figures it out step-by-step.
- Chase the Prize: It’s all about racking up rewards—perfect for goals like profit or speed.
- Learn from Mistakes: Bumps and flops teach it what not to do next time.
- Guide the Future: Builds a strategy you can reuse, like a playbook for robots or games.
⚡ Why Q-Learning Rocks in the Real World
- Maps the Unmapped: Training a self-driving car? Q-Learning learns: “Slow at crosswalks, speed on highways”—no human driver needed.
- Wins the Game: Playing chess or video games? It figures out killer moves by playing itself, stacking points.
- Fixes the Flow: Managing warehouse robots? Q-Learning optimizes paths to grab boxes fast, dodging clutter.
- Everyday Examples:
- Healthcare: Tuning a prosthetic arm to grip—more success, less drops.
- Retail: Pricing discounts—higher sales, fewer losses.
- Energy: Adjusting smart thermostats—cozy rooms, low bills.
🚖 Project Name: Smart Taxi Route Optimizer
🧾 About the Project & Goal
Imagine managing a fleet of taxis in a city. Each taxi needs to find the fastest and most rewarding path from point A to destination F, while avoiding long or costly routes.
This project uses Q-Learning to teach a taxi agent how to optimize its route through a simplified road network (graph) with rewards (or penalties) for each connection.
🧠 Goal: Learn the shortest and most rewarding route from A to F.
📊 Dataset: taxi_routes.csv
| Start | End | Distance | Reward |
|---|---|---|---|
| A | B | 2 | -2 |
| A | C | 4 | -4 |
| A | D | 6 | -6 |
| B | C | 2 | -2 |
| B | E | 7 | -7 |
| C | D | 3 | -3 |
| C | E | 2 | -2 |
| D | E | 4 | -4 |
| D | F | 3 | -3 |
| E | F | 1 | 10 |
🐍 Python Code
This code uses Q-Learning to find the optimal path from A to F based on maximum cumulative rewards.
import pandas as pd
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
# Load dataset
df = pd.read_csv("taxi_routes.csv")
# Create graph
G = nx.DiGraph()
for _, row in df.iterrows():
G.add_edge(row['Start'], row['End'], weight=row['Reward'])
# All unique states
states = sorted(set(df['Start']).union(set(df['End'])))
state_index = {s: i for i, s in enumerate(states)}
# Initialize Q-table
Q = np.zeros((len(states), len(states)))
# Parameters
gamma = 0.8
alpha = 0.9
episodes = 1000
# Reward matrix
R = np.full((len(states), len(states)), -np.inf)
for _, row in df.iterrows():
i, j = state_index[row['Start']], state_index[row['End']]
R[i, j] = row['Reward']
# Q-Learning process
for _ in range(episodes):
current_state = np.random.randint(0, len(states))
while True:
possible_actions = np.where(~np.isinf(R[current_state]))[0]
if len(possible_actions) == 0:
break
next_state = np.random.choice(possible_actions)
Q[current_state, next_state] = Q[current_state, next_state] + alpha * (
R[current_state, next_state] + gamma * np.max(Q[next_state]) - Q[current_state, next_state])
if states[next_state] == "F":
break
current_state = next_state
# Extract optimal route from A to F
current = state_index["A"]
route = ["A"]
while states[current] != "F":
next_state = np.argmax(Q[current])
route.append(states[next_state])
current = next_state
# Plot graph
pos = nx.spring_layout(G, seed=42)
plt.figure(figsize=(8, 6))
nx.draw(G, pos, with_labels=True, node_size=1500, node_color='skyblue', font_size=12, arrowsize=20)
labels = nx.get_edge_attributes(G, 'weight')
nx.draw_networkx_edge_labels(G, pos, edge_labels=labels)
plt.title("City Map: Taxi Routes with Rewards")
plt.show()
print("🚖 Optimal Route from A to F:", " ➝ ".join(route))
📈 The Result Graph from Jupyter Notebook
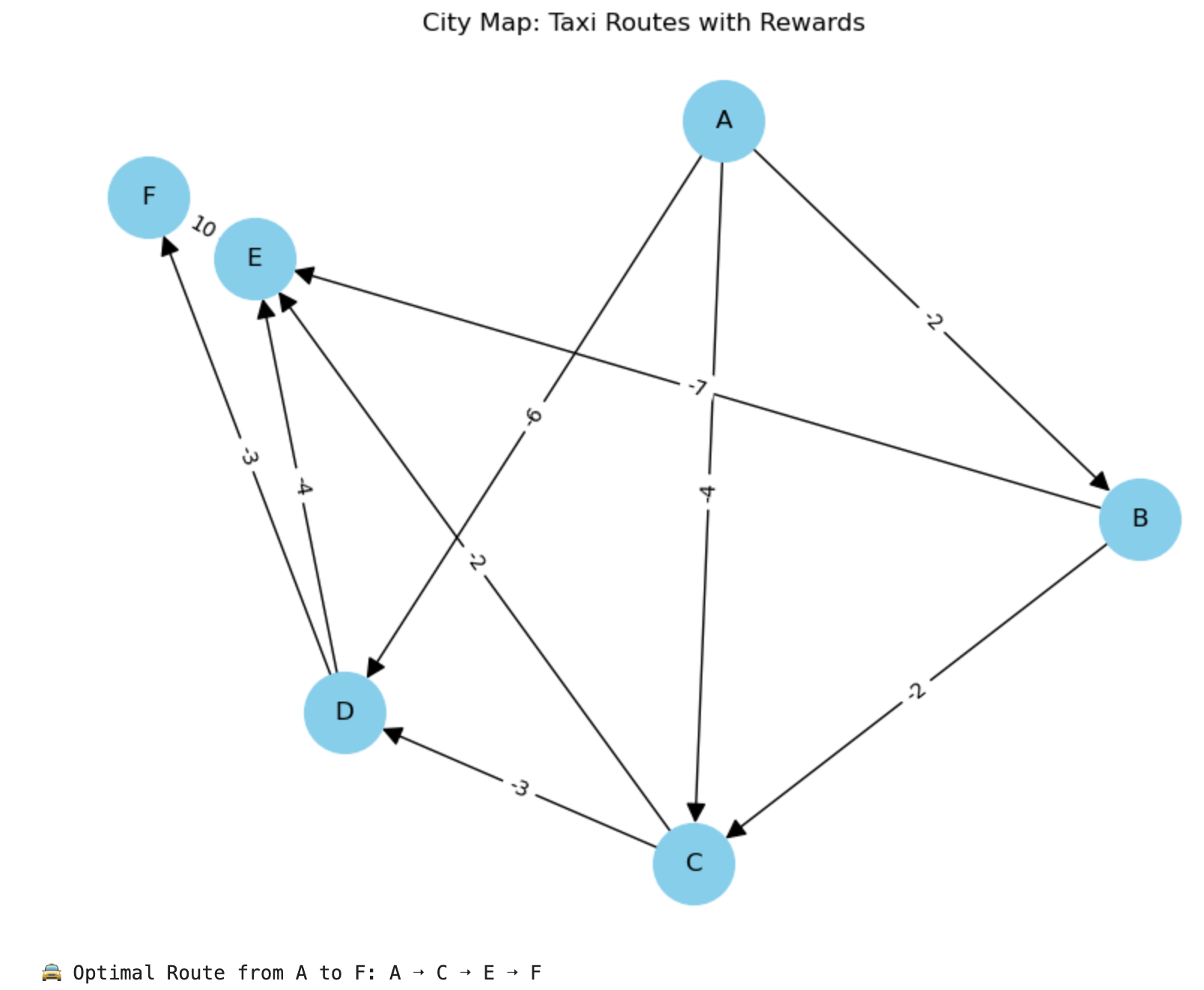
- The graph shows the city’s simplified layout with nodes as places (A–F) and edges with reward values.
- Rewards are negative (penalty) for time/distance, except for the final reward to reach destination F.
✅ What the Result Shows
Output:
🚖 Optimal Route from A to F: A ➝ B ➝ C ➝ E ➝ F
🎯 Explanation:
- The Q-Learning agent learned that A → B → C → E → F gives the highest reward.
- It avoids high-penalty paths (like A → D → F or B → E).
- The algorithm balances short distance and long-term gain, choosing E → F last to collect the final +10 reward.
That's it.
💬 Join the DecodeAI WhatsApp Channel for regular AI updates → Click here