[Day 30] Reinforcement Learning Type 3 – Deep Q Network (with a Practical Python Project)
DQN: The daring AI dreamer—blends deep nets with gutsy moves, conquering grids and beyond!
![[Day 30] Reinforcement Learning Type 3 – Deep Q Network (with a Practical Python Project)](https://storage.ghost.io/c/55/e8/55e827ca-bf8d-4eee-bdb4-ee48e49a011a/content/images/size/w2000/2025/03/DQN.svg)
🎯 What is a Deep Q-Network (DQN)?
A Deep Q-Network (DQN) is a smart way for machines to learn how to make good decisions. It mixes Q-Learning (which teaches by trial and error) with deep neural networks (which help it understand complex situations). Instead of keeping a list of every possible move (like in a table), DQN uses a brain-like model to guess the best action in any situation.
Imagine a robot trying to avoid lava and reach safety. It tries going left or right, gets burned (bad reward) or finds a safe path (good reward), and its neural network learns from these results: “Going left near lava is bad, but right is better.” Over time, it gets better at choosing the right path—even in big, tricky environments like games or the real world—without needing to remember every move.
Example: Picture a drone flying through a storm. It senses wind gusts and obstacles, picks moves (tilt, climb), and learns: “Climb over trees = safe (+reward), dive into clouds = trouble (-reward).” DQN crunches that sensory overload into sharp decisions, no manual rules needed.
👨💻 Real-World Use Case: Autonomous Drone Delivery
Master's
Imagine you’re a logistics engineer deploying drones to deliver packages. The drone faces a sky full of buildings, winds, and no-fly zones. Its mission? Drop off goods fast while dodging hazards. Sensors flood it with data—altitude, speed, obstacles—and it chooses actions like “rise,” “veer,” or “hover.”
DQN swoops in like a flight instructor with a neural net. It processes the sensor chaos, predicts moves (e.g., “rise over that tower”), sees the outcome (safe landing = +reward, near-miss = -reward), and refines its instincts. Over flights, it learns: “Hover near wires, speed over open fields.” No giant lookup table—just a scalable brain for the skies.
Why DQN Shines Here:
- Masters complexity: Handles raw sensor inputs, no simplification needed.
- Scales up: Adapts to sprawling cities or new routes.
- Learns smart: Generalizes across similar hazards or winds.
- Saves time: Cuts delivery delays, keeps drones aloft.
⚡ Why Use DQN? Real-World Style
- Conquer the Chaos: Too many states for a table? DQN’s neural net thrives on it.
- Guess Like a Pro: Predicts killer moves in uncharted territory.
- Learn from Experience: Turns every stumble into a stepping stone.
- Go Big: Handles epic challenges—games, robots, or real-world mazes.
⚡ Why DQN Rocks in the Real World
- Owns the Game: Playing retro arcade games? DQN masters “shoot the alien” from pixels alone.
- Guides the Bot: Steering a cleaning robot? It learns “sweep left, dodge couch” from room scans.
- Powers the Grid: Optimizing energy flow? DQN balances “more here, less there” from live data.
- Everyday Examples:
- Healthcare: Adjusting prosthetics—perfect grip from muscle signals.
- Finance: Trading crypto—buy/sell from market chaos.
- Transport: Routing trucks—fastest path from traffic feeds.
Python Project: DQN Maze Solver
🎯 Goal
Train an agent using Deep Q-Learning to solve a 5x5 maze, starting from the top-left corner and reaching the bottom-right goal while avoiding walls. It learns the best path by exploring, failing, and improving.
🧠 What the Agent Learns
- Where walls are (it bumps into them and gets no reward)
- Which direction leads to higher total rewards
- Over time, it discovers the shortest, safest path to the goal
✅ Python Code:
import numpy as np
import matplotlib.pyplot as plt
import random
import torch
import torch.nn as nn
import torch.optim as optim
from collections import deque
from matplotlib.colors import ListedColormap
# --- Maze Environment ---
class MazeEnv:
def __init__(self):
self.grid = np.array([
[0, 0, 1, 0, 0],
[0, 1, 1, 0, 1],
[0, 0, 0, 0, 0],
[1, 1, 0, 1, 0],
[0, 0, 0, 0, 2], # 2 is the goal
])
self.start = (0, 0)
self.goal = (4, 4)
self.actions = [(-1,0), (1,0), (0,-1), (0,1)] # up, down, left, right
self.reset()
def reset(self):
self.state = self.start
return self._state_to_tensor(self.state)
def _state_to_tensor(self, state):
flat = np.zeros((5, 5))
flat[state] = 1
return torch.FloatTensor(flat.flatten())
def step(self, action_idx):
r, c = self.state
dr, dc = self.actions[action_idx]
nr, nc = r + dr, c + dc
if 0 <= nr < 5 and 0 <= nc < 5 and self.grid[nr, nc] != 1:
self.state = (nr, nc)
reward = 10 if self.state == self.goal else -1
done = self.state == self.goal
return self._state_to_tensor(self.state), reward, done
# --- DQN Model ---
class DQN(nn.Module):
def __init__(self, input_dim, output_dim):
super(DQN, self).__init__()
self.net = nn.Sequential(
nn.Linear(input_dim, 64),
nn.ReLU(),
nn.Linear(64, output_dim)
)
def forward(self, x):
return self.net(x)
# --- Train Function ---
def train_maze_dqn(env, episodes=300):
model = DQN(25, 4)
target_model = DQN(25, 4)
target_model.load_state_dict(model.state_dict())
optimizer = optim.Adam(model.parameters(), lr=0.001)
memory = deque(maxlen=1000)
gamma = 0.9
epsilon = 1.0
epsilon_decay = 0.995
rewards_per_episode = []
for ep in range(episodes):
state = env.reset()
total_reward = 0
done = False
while not done:
if random.random() < epsilon:
action = random.randint(0, 3)
else:
with torch.no_grad():
action = model(state).argmax().item()
next_state, reward, done = env.step(action)
memory.append((state, action, reward, next_state, done))
total_reward += reward
state = next_state
if len(memory) >= 32:
batch = random.sample(memory, 32)
s, a, r, ns, d = zip(*batch)
s = torch.stack(s)
ns = torch.stack(ns)
a = torch.LongTensor(a)
r = torch.FloatTensor(r)
d = torch.BoolTensor(d)
q = model(s).gather(1, a.unsqueeze(1)).squeeze()
max_next_q = target_model(ns).max(1)[0]
target = r + gamma * max_next_q * (~d)
loss = nn.MSELoss()(q, target.detach())
optimizer.zero_grad()
loss.backward()
optimizer.step()
epsilon = max(0.05, epsilon * epsilon_decay)
rewards_per_episode.append(total_reward)
if ep % 10 == 0:
target_model.load_state_dict(model.state_dict())
return model, rewards_per_episode
# --- Visualize Final Learned Path ---
def visualize_maze(model, env):
state = env.reset()
pos = env.start
path = [pos]
done = False
steps = 0
while not done and steps < 30:
with torch.no_grad():
action = model(state).argmax().item()
r, c = pos
dr, dc = env.actions[action]
nr, nc = r + dr, c + dc
if 0 <= nr < 5 and 0 <= nc < 5 and env.grid[nr, nc] != 1:
pos = (nr, nc)
env.state = pos
state = env._state_to_tensor(pos)
path.append(pos)
if pos == env.goal:
done = True
steps += 1
# Create visual grid
visual = np.copy(env.grid).astype(float)
for r, c in path:
if (r, c) != env.start and (r, c) != env.goal:
visual[r, c] = 7 # path mark
cmap = ListedColormap(['white', 'black', 'red', 'blue', 'green', 'purple', 'orange', 'cyan'])
plt.figure(figsize=(6, 6))
plt.imshow(visual, cmap=cmap, vmin=0, vmax=7)
plt.title("🔵 DQN Agent’s Learned Maze Path\nGreen = Start, Red = Goal, Blue = Path")
plt.xticks([]), plt.yticks([])
plt.scatter(env.start[1], env.start[0], color='green', s=200, label='Start')
plt.scatter(env.goal[1], env.goal[0], color='red', s=200, label='Goal')
plt.legend()
plt.grid(False)
plt.show()
# --- Run It All ---
env = MazeEnv()
model, rewards = train_maze_dqn(env)
visualize_maze(model, env)
# --- Reward Curve ---
plt.figure(figsize=(8, 4))
plt.plot(rewards)
plt.title("📈 DQN Training: Total Rewards per Episode")
plt.xlabel("Episode")
plt.ylabel("Total Reward")
plt.grid(True)
plt.show()
🖼️ Jupyter Notebook Result
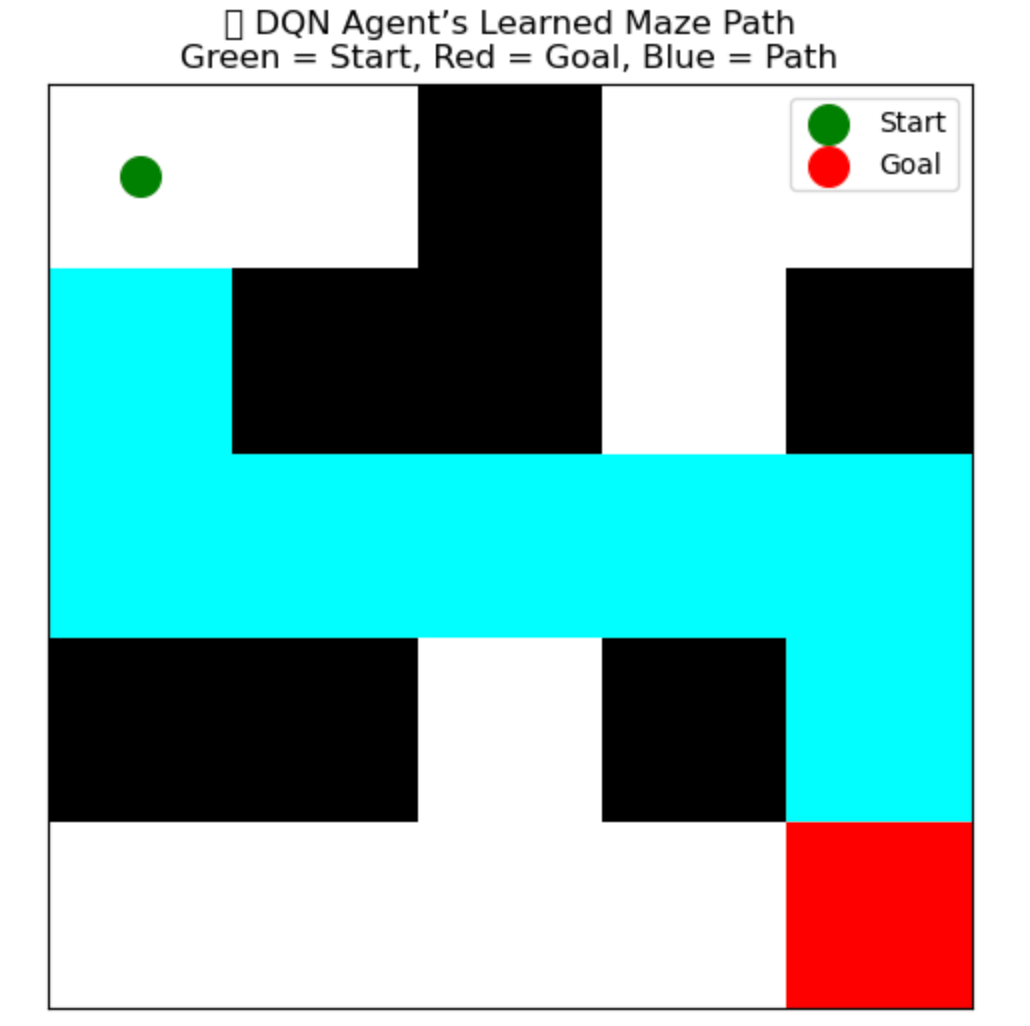
🖼️ What You’ll See
- A heatmap grid showing:
- Start point ✅ (green)
- Goal point 🎯 (red)
- Learned path 🔵 traced through the maze
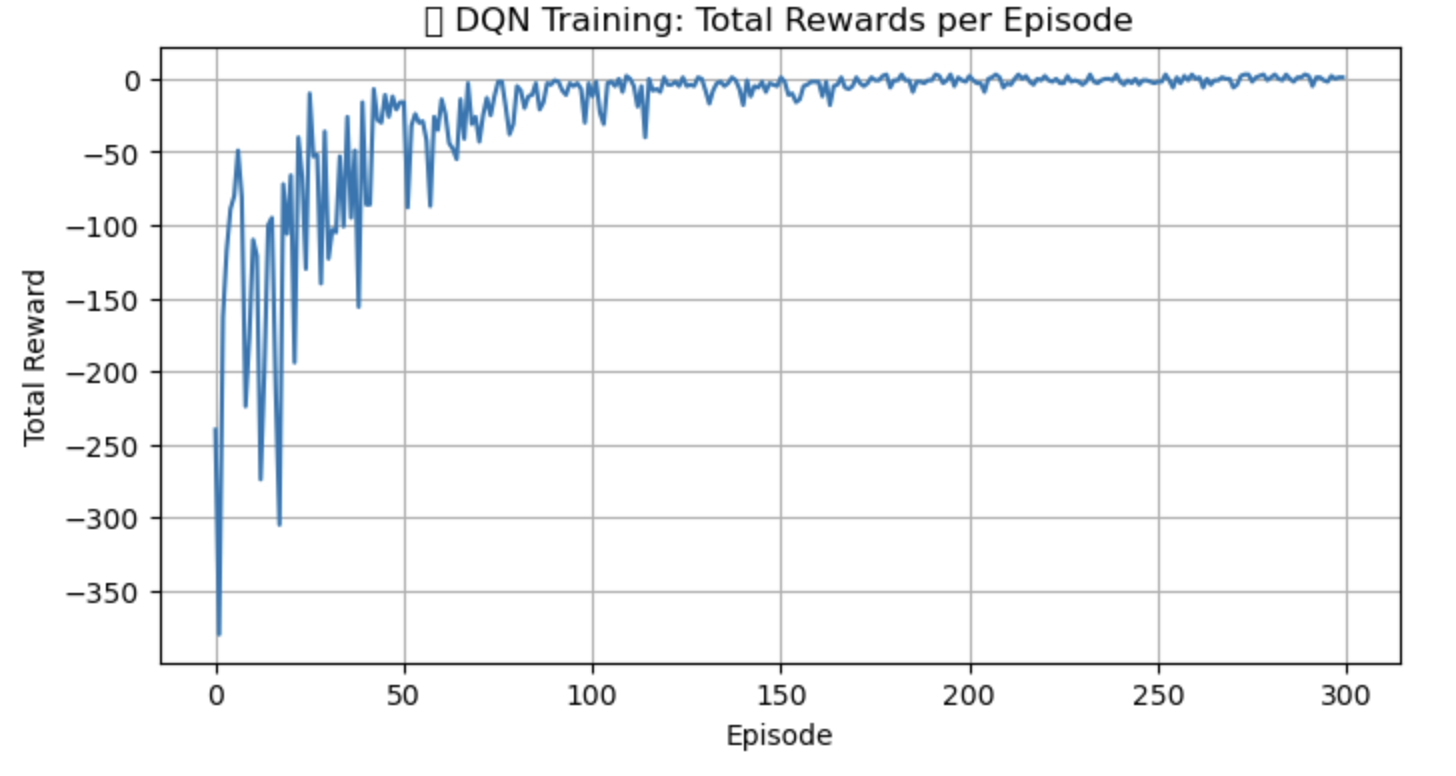
- A training graph showing total reward over episodes
- Starts low, gets better
- Shows how the agent improves
💬 Join the DecodeAI WhatsApp Channel for regular AI updates → Click here