[Day 31] Reinforcement Learning Type 4 – Monte Carlo (with a Practical Python Project)
Master strategies with Monte Carlo! Learn how agents improve by evaluating entire tasks, transforming mistakes into wisdom. Ready to explore?
![[Day 31] Reinforcement Learning Type 4 – Monte Carlo (with a Practical Python Project)](https://storage.ghost.io/c/55/e8/55e827ca-bf8d-4eee-bdb4-ee48e49a011a/content/images/size/w2000/2025/03/MC.svg)
🎯 What is Monte Carlo Reinforcement Learning?
Monte Carlo is a simple yet powerful way for machines to learn from experience. Instead of updating its brain step-by-step like DQN, Monte Carlo waits till the end of a full episode—then learns from the total journey. It keeps track of what worked, what didn’t, and improves its game plan over time.
Imagine a robot exploring a maze. It walks around, sometimes hitting dead ends, sometimes finding the goal. Once it’s done, it looks back and says, “Okay, turning left at that corner worked well,” and updates its memory. Do this enough times, and the robot starts choosing smarter paths from the start.
💡 Example: Think of a delivery bot trying different paths through a building. Every time it completes a delivery, it remembers the full trip and learns: “That shortcut near the kitchen is faster.” Over many episodes, it builds a smarter route map—not from instant feedback, but from full experiences.
👨💻 Real-World Use Case: Optimizing Warehouse Robot Routes
Imagine you're managing a warehouse full of robots moving packages. Each robot needs to learn the best path from pickup to drop-off—without crashing into shelves or wasting time. The layout is complex and changes often.
Monte Carlo comes in like a coach with a clipboard. Every time a robot finishes a delivery run, it tracks the full path, measures how efficient it was (+reward), and updates its strategy for next time. Over thousands of runs, the robot builds a reliable, reward-based understanding of how to move smartly—even if the warehouse changes or new obstacles appear.
Why Monte Carlo Works Here:
- Simple and effective: Easy to implement, no need for fancy models
- Learns from the full journey: Perfect for delivery tasks or games with clear end goals
- Handles unpredictability: Learns even when environments are dynamic
- Great for delayed rewards: Doesn’t need instant feedback at each step
⚡ Why Use Monte Carlo?
- End-to-End Learning: Learns from the full episode, just like a human reflecting on a trip
- No Need for Models: Doesn’t require knowing how the world works, just observes
- Perfect for Games & Tasks: Great for mazes, board games, or goal-based navigation
- Keeps It Simple: No backprop, no neural nets—just smart averages over time
Everyday Examples:
- Finance: Learning full trade cycles that lead to profit
- Healthcare: Understanding full treatment sequences that lead to recovery
- Education: Optimizing lesson paths that help students learn better
🧠 Python Project: Monte Carlo Maze Solver
🎯 Goal
Train an agent using Monte Carlo learning to solve a 5x5 maze. The agent starts at the top-left and must reach the bottom-right corner, learning from complete runs through the maze. It builds a policy that improves with experience.
🧠 What the Agent Learns
- Which moves eventually lead to success
- Which turns waste time or lead to dead ends
- How to complete the maze in fewer steps, using long-term reward instead of instant results
✅ Python Code
import numpy as np
import matplotlib.pyplot as plt
from collections import defaultdict
import random
from matplotlib.colors import ListedColormap
# --- Maze Environment ---
class MazeEnv:
def __init__(self):
self.grid = np.array([
[0, 0, 1, 0, 0],
[0, 1, 1, 0, 1],
[0, 0, 0, 0, 0],
[1, 1, 0, 1, 0],
[0, 0, 0, 0, 2], # 2 is the goal
])
self.start = (0, 0)
self.goal = (4, 4)
self.actions = [(-1,0), (1,0), (0,-1), (0,1)] # up, down, left, right
self.action_space = list(range(len(self.actions)))
def reset(self):
self.state = self.start
return self.state
def step(self, action_idx):
r, c = self.state
dr, dc = self.actions[action_idx]
nr, nc = r + dr, c + dc
# move if not a wall or boundary
if 0 <= nr < 5 and 0 <= nc < 5 and self.grid[nr, nc] != 1:
self.state = (nr, nc)
reward = 10 if self.state == self.goal else -1
done = self.state == self.goal
return self.state, reward, done
# --- Monte Carlo Policy Trainer ---
def train_monte_carlo(env, episodes=5000, gamma=0.9, epsilon=0.2):
Q = defaultdict(lambda: np.zeros(4)) # Q-values
returns = defaultdict(list) # for averaging
policy = {}
for ep in range(episodes):
state = env.reset()
episode = []
done = False
while not done:
if random.random() < epsilon:
action = random.choice(env.action_space)
else:
action = np.argmax(Q[state])
next_state, reward, done = env.step(action)
episode.append((state, action, reward))
state = next_state
# calculate returns from the episode
G = 0
visited = set()
for t in reversed(range(len(episode))):
s, a, r = episode[t]
G = gamma * G + r
if (s, a) not in visited:
returns[(s, a)].append(G)
Q[s][a] = np.mean(returns[(s, a)])
visited.add((s, a))
# derive final policy
for s in Q:
policy[s] = np.argmax(Q[s])
return policy, Q
# --- Visualize Final Path ---
def visualize_monte_carlo_policy(env, policy):
pos = env.start
path = [pos]
env.state = pos
steps = 0
while pos != env.goal and steps < 50:
if pos not in policy:
break
action = policy[pos]
dr, dc = env.actions[action]
r, c = pos
nr, nc = r + dr, c + dc
if 0 <= nr < 5 and 0 <= nc < 5 and env.grid[nr, nc] != 1:
pos = (nr, nc)
path.append(pos)
env.state = pos
else:
break # invalid move or stuck
steps += 1
# visual grid
visual = env.grid.copy().astype(float)
for r, c in path:
if (r, c) != env.start and (r, c) != env.goal:
visual[r, c] = 7 # path mark
cmap = ListedColormap(['white', 'black', 'red', 'blue', 'green', 'purple', 'orange', 'cyan'])
plt.figure(figsize=(6, 6))
plt.imshow(visual, cmap=cmap, vmin=0, vmax=7)
plt.title("🎯 Monte Carlo Agent’s Learned Path\nGreen = Start, Red = Goal, Blue = Path")
plt.xticks([]), plt.yticks([])
plt.scatter(env.start[1], env.start[0], color='green', s=200, label='Start')
plt.scatter(env.goal[1], env.goal[0], color='red', s=200, label='Goal')
plt.legend()
plt.grid(False)
plt.show()
# --- Run It All ---
env = MazeEnv()
policy, Q = train_monte_carlo(env, episodes=5000)
visualize_monte_carlo_policy(env, policy)
🖼️ Jupyter Notebook Result
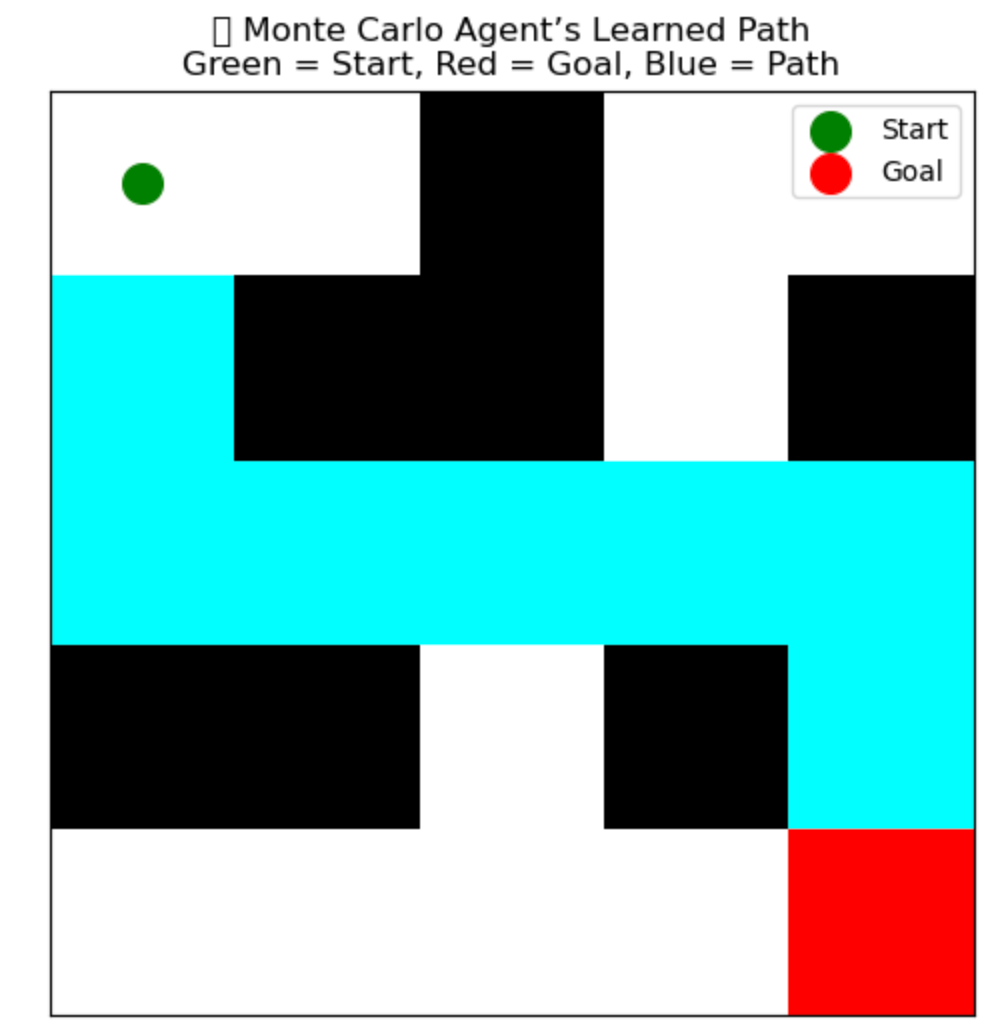
🖼️ What You’ll See
Maze Grid Visualization:
- ✅ Green = Start
- 🎯 Red = Goal
- 🔵 Blue path = Agent’s best route learned from full-episode experiences
- ✅ Agent starts knowing nothing
- ✅ Runs 5,000 full episodes and keeps track of moves that gave better rewards
- ✅ Learns from experience which moves led to the goal efficiently
- ✅ The blue path shows the shortest and safest path learned
💬 Join the DecodeAI WhatsApp Channel for regular AI updates → Click here