[Day 32] Reinforcement Learning Type 5 – Proximal Policy Optimization (PPO) (with a Practical Python Project)
PPO is the secret sauce for stable and efficient learning. Explore how it fine-tunes decisions, from game bots to robotics, with precision!
![[Day 32] Reinforcement Learning Type 5 – Proximal Policy Optimization (PPO) (with a Practical Python Project)](https://storage.ghost.io/c/55/e8/55e827ca-bf8d-4eee-bdb4-ee48e49a011a/content/images/size/w2000/2025/03/PPO.svg)
🎯 What is Proximal Policy Optimization (PPO)?
Proximal Policy Optimization (PPO) is one of the most popular and practical reinforcement learning methods today. It belongs to the policy-based family, which means it teaches an agent how to act directly, instead of estimating how good each action is.
PPO’s core strength? It learns just enough each time — not too much, not too little. It keeps updates “proximal” (close) to the current policy, which helps avoid wild moves and unstable learning.
💡 Imagine This:
You’re training a dog to fetch a ball. It starts with random zig-zags. After every run, you give feedback. But if you change its behavior too drastically each time (“now do backflips!”), it never settles.
PPO avoids that. It says, “Nice fetch, let’s slightly improve the direction next time.” Over time, it fetches better — steadily, not wildly.
👨💻 Real-World Use Case: Self-Driving Scooter in a Campus
Imagine you’re building an autonomous scooter that must learn to ride across a university campus. It must:
- Follow curved paths
- Avoid people and benches
- Reach destinations smoothly
PPO helps by adjusting its movement strategy slightly with every experience. If a sharp turn fails, it tweaks it — just a little. No dangerous jerks, no overcorrections. The result? A confident scooter that learns to ride calmly, even in crowded spaces.
⚡ Why Use PPO?
- Stability: It avoids overshooting good policies
- Efficiency: Learns faster by using past data well
- Safe Exploration: Prevents big policy jumps
- Scales Up: Powers OpenAI’s agents and modern robotics
🧠 Python Project: PPO Smart Grid Navigator
🎯 Goal
Train an agent using PPO to navigate a smart grid (5x5) from a power source (start) to a city node (goal), while avoiding obstacles and minimizing energy waste.
This is not just about reaching the goal — it’s about reaching efficiently, learning smooth movement strategies over episodes.
🗺️ Grid Setup
- Start: (0, 0) — a power station
- Goal: (4, 4) — a city node
- Obstacles: Random blocks representing “broken lines” or high-loss zones
- Reward:
- +10 for reaching the goal
- -1 for every step
- -5 for hitting an obstacle
✅ Python Code
!pip install gymnasium stable-baselines3 --quiet
import numpy as np
import matplotlib.pyplot as plt
import gymnasium as gym
from gymnasium import spaces
from stable_baselines3 import PPO
from stable_baselines3.common.env_checker import check_env
from stable_baselines3.common.env_util import DummyVecEnv
from matplotlib.colors import ListedColormap
# --- Custom Smart Grid Environment ---
class GridEnergyEnv(gym.Env):
def __init__(self):
super().__init__()
self.size = 5
self.start = (0, 0)
self.goal = (4, 4)
self.obstacles = [(1, 2), (2, 2), (3, 0), (3, 3)]
self.observation_space = spaces.Box(low=0, high=self.size - 1, shape=(2,), dtype=np.int32)
self.action_space = spaces.Discrete(4) # 0=up, 1=down, 2=left, 3=right
self.reset()
def reset(self, seed=None, options=None):
super().reset(seed=seed)
self.agent_pos = self.start
return np.array(self.agent_pos, dtype=np.int32), {}
def step(self, action):
r, c = self.agent_pos
if action == 0: r = max(0, r - 1)
if action == 1: r = min(self.size - 1, r + 1)
if action == 2: c = max(0, c - 1)
if action == 3: c = min(self.size - 1, c + 1)
new_pos = (r, c)
if new_pos in self.obstacles:
reward = -5
done = False
elif new_pos == self.goal:
reward = 10
done = True
else:
reward = -1
done = False
self.agent_pos = new_pos
return np.array(self.agent_pos, dtype=np.int32), reward, done, False, {}
def render(self):
grid = np.zeros((self.size, self.size))
for r, c in self.obstacles:
grid[r, c] = 1
grid[self.goal] = 2
grid[self.agent_pos] = 3
return grid
# --- Training ---
env = GridEnergyEnv()
check_env(env, skip_render_check=True)
vec_env = DummyVecEnv([lambda: env])
model = PPO("MlpPolicy", vec_env, verbose=0)
model.learn(total_timesteps=10000)
# --- Visualization ---
def visualize_path(env, model):
obs, _ = env.reset()
path = [tuple(obs)]
done = False
for _ in range(30):
action, _ = model.predict(obs)
obs, _, done, _, _ = env.step(action)
path.append(tuple(obs))
if done:
break
grid = np.zeros((env.size, env.size))
for r, c in env.obstacles:
grid[r, c] = 1
grid[env.goal] = 2
for r, c in path:
if (r, c) != env.goal and (r, c) != env.start:
grid[r, c] = 3
cmap = ListedColormap(['white', 'black', 'green', 'blue'])
plt.figure(figsize=(6, 6))
plt.imshow(grid, cmap=cmap, vmin=0, vmax=3)
plt.title("PPO Agent — Smart Grid Navigation\nGreen = Goal, Black = Obstacles, Blue = Learned Path")
plt.scatter(env.start[1], env.start[0], s=200, c='orange', label='Start')
plt.legend()
plt.grid(False)
plt.xticks([]), plt.yticks([])
plt.show()
visualize_path(env, model)
🖼️ Run it on Jupyter Notebook
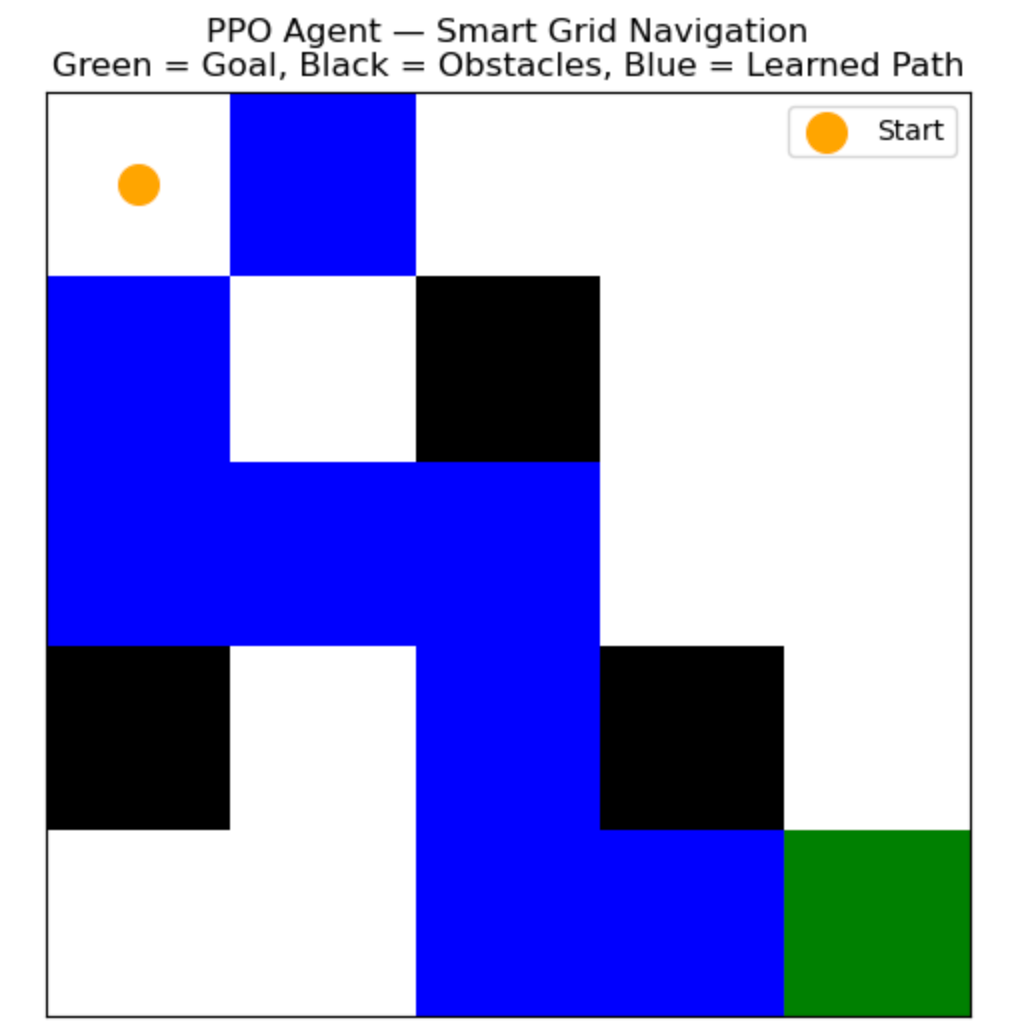
- 🟠 Start: Orange dot (Power Station)
- 🟢 Goal: Green square (City Node)
- ⬛ Obstacles: Black blocks (Bad power lines)
- 🔵 Path: PPO agent’s learned route — efficient, smooth, and avoids losses
🧩 What This Project Shows
- PPO learns stable, safe routes from sparse feedback
- The agent avoids bad spots, reaches goals in fewer steps
- You can tweak reward settings to simulate real-world trade-offs (e.g., faster vs safer)
💬 Join the DecodeAI WhatsApp Channel for regular AI updates → Click here