[Day 33] Reinforcement Learning Type 6 – Deep Deterministic Policy Gradient (with a Practical Python Project)
Where AI Masters Precision—Blending Deep Learning’s Brains with Reinforcement Learning’s Bold Moves!
![[Day 33] Reinforcement Learning Type 6 – Deep Deterministic Policy Gradient (with a Practical Python Project)](https://storage.ghost.io/c/55/e8/55e827ca-bf8d-4eee-bdb4-ee48e49a011a/content/images/size/w2000/2025/03/DDPG.svg)
🎯 What is Deep Deterministic Policy Gradient (DDPG)?
Deep Deterministic Policy Gradient (DDPG) is a powerful reinforcement learning method that teaches machines to act decisively in complex, continuous worlds. It blends deep neural networks with policy gradients (like PPO) and Q-learning (like DQN), letting it pick precise actions—like turning a dial just right—rather than guessing from a short list. Think of it as a pilot smoothly steering a plane through turbulence, adjusting controls bit by bit.
Imagine a robot moving through a maze. It decides how far to shift—say, 0.3 steps right—gets a reward or bump, and DDPG fine-tunes its moves: “That nudge worked, let’s refine it.” It uses an “actor” network to choose actions and a “critic” to judge them, learning steadily with tricks like target networks and experience replay to keep things smooth.
Example: Picture a robotic arm painting a wall. It adjusts brush pressure and angle, earns rewards for even strokes, and DDPG tweaks its technique: “Light pressure here, sharper angle there.” It handles continuous control—like brush strength—where discrete choices (e.g., “high” or “low”) won’t cut it.
👨💻 Real-World Use Case: Autonomous Vehicle Steering
Imagine you’re an engineer designing an autonomous car. It navigates roads with curves, traffic, and weather, aiming to drive smoothly and safely. It picks actions like “steer 0.2 radians left” or “accelerate 0.5 m/s²,” based on sensors—cameras, radar, speed.
DDPG rolls in like a driving instructor with a simulator. The car steers slightly, stays on track (+reward), or skids (-penalty), and DDPG adjusts: “That turn was solid, let’s nudge it a bit more.” It learns precise control over continuous actions, adapting to new roads or conditions.
Why DDPG Shines Here
- Continuous Control: Handles steering angles and speeds, not just “left or right.”
- Stable Learning: Uses target networks to keep updates steady.
- Adapts: Masters new routes or weather with experience replay.
- Smooth Rides: Delivers fluid driving without jerky stops.
⚡ Why Use DDPG?
- Precise Moves: Picks exact actions—like “turn 0.7”—not just “turn.”
- Deep Smarts: Combines neural nets for complex decisions.
- Steady Progress: Learns reliably with replay and target tricks.
- Big Challenges: Tackles continuous tasks—motion, flow, or control.
🧠 Project: DDPG Smart Thermostat Controller
🎯 Goal
Train a DDPG agent to act as a smart thermostat that adjusts the room temperature using a continuous action (e.g., increase/decrease by 0.5°C) to reach and maintain a target comfort temperature, like 24°C.
- Most of us relates to ACs or heaters adjusting temperature
- Action is continuous: DDPG adjusts heating/cooling power
- Reward is intuitive: get closer to 24°C = higher reward
- Can easily visualize how well the agent keeps the room comfy
✅ Full Code (DDPG + Custom Smart Thermostat Env)
!pip install stable-baselines3 gymnasium --quiet
import numpy as np
import gymnasium as gym
from gymnasium import spaces
from stable_baselines3 import DDPG
from stable_baselines3.common.noise import NormalActionNoise
import matplotlib.pyplot as plt
# --- Custom Env: Smart Thermostat ---
class SmartThermostatEnv(gym.Env):
def __init__(self):
super().__init__()
self.min_temp = 15.0
self.max_temp = 35.0
self.target_temp = 24.0
self.room_temp = None
self.outdoor_temp = None
self.observation_space = spaces.Box(
low=np.array([15.0], dtype=np.float32),
high=np.array([35.0], dtype=np.float32),
dtype=np.float32
)
self.action_space = spaces.Box(low=-1.0, high=1.0, shape=(1,), dtype=np.float32)
def reset(self, seed=None, options=None):
self.room_temp = np.random.uniform(20.0, 30.0)
self.outdoor_temp = np.random.uniform(10.0, 40.0)
return np.array([self.room_temp], dtype=np.float32), {}
def step(self, action):
action = float(np.clip(action[0], -1.0, 1.0))
drift = (self.outdoor_temp - self.room_temp) * 0.01 # natural temperature drift
self.room_temp += action + drift
self.room_temp = np.clip(self.room_temp, self.min_temp, self.max_temp)
reward = -abs(self.room_temp - self.target_temp) # the closer to 24°C, the better
done = abs(self.room_temp - self.target_temp) < 0.3
return np.array([self.room_temp], dtype=np.float32), reward, done, False, {}
def render(self):
print(f"Room Temp: {self.room_temp:.2f} °C, Target: {self.target_temp} °C")
# --- Train with DDPG ---
env = SmartThermostatEnv()
n_actions = env.action_space.shape[0]
action_noise = NormalActionNoise(mean=np.zeros(n_actions), sigma=0.1 * np.ones(n_actions))
model = DDPG("MlpPolicy", env, action_noise=action_noise, verbose=0)
model.learn(total_timesteps=10000)
# --- Visualize a Run ---
obs, _ = env.reset()
temps = [obs[0]]
for _ in range(50):
action, _ = model.predict(obs, deterministic=True)
obs, reward, done, _, _ = env.step(action)
temps.append(obs[0])
if done:
break
plt.plot(temps, marker='o')
plt.axhline(env.target_temp, color='green', linestyle='--', label='Target Temp (24°C)')
plt.title("DDPG Smart Thermostat: Room Temperature Over Time")
plt.xlabel("Time Step")
plt.ylabel("Room Temperature (°C)")
plt.legend()
plt.grid(True)
plt.show()🧠 Result on Jupyter Notebook
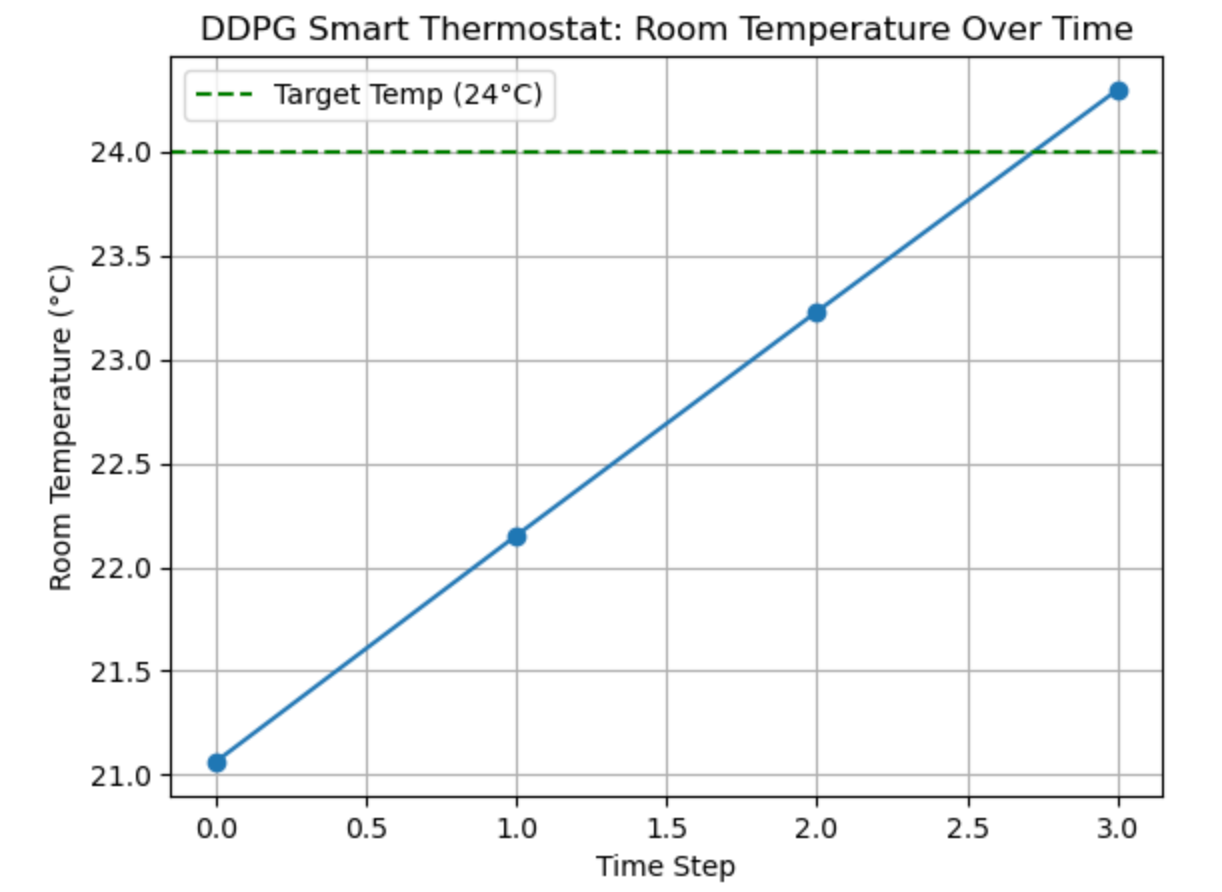
A plot of how the room temperature changes over time, starting from a random temp (say, 28°C), and stabilizing near 24°C with each DDPG-powered adjustment.
💬 Join the DecodeAI WhatsApp Channel for regular AI updates → Click here