[Day 34] Reinforcement Learning Type 7 – Actor-Critic Methods (with a Practical Python Project)
Actor-Critic: AI's Dynamic Duo—One Learns to Act, the Other Judges Like a Pro!
![[Day 34] Reinforcement Learning Type 7 – Actor-Critic Methods (with a Practical Python Project)](https://storage.ghost.io/c/55/e8/55e827ca-bf8d-4eee-bdb4-ee48e49a011a/content/images/size/w2000/2025/03/AC.svg)
🎯 What is Actor-Critic?
Actor-Critic is a hybrid reinforcement learning method that combines the best of policy-based and value-based approaches, working like a dynamic duo to make smart decisions. The “Actor” learns a policy—deciding what action to take—while the “Critic” evaluates those actions by estimating their value, giving feedback to improve the Actor’s choices. Think of it as a director (Actor) staging a play while a reviewer (Critic) critiques each scene to make the next one better.
Actor-Critic is a powerful reinforcement learning technique that combines two smart components:
- 🧠 Actor: Learns to pick the best action (like move left, accelerate, send a notification)
- 🧠 Critic: Evaluates how good that action was (by estimating expected future rewards)
Imagine you're building a food delivery app:
- The Actor is the routing engine suggesting which turn to take.
- The Critic is the system tracking delivery time, traffic, and rider delays — giving a score for each route decision.
Instead of learning only at the end (like in Monte Carlo), the critic gives feedback after every move, helping the actor refine decisions in real-time.
Example: Picture a chef tweaking a recipe. The Actor (chef) decides to add more salt, and the Critic (taster) says, “That’s a bit better, but not perfect.” The chef adjusts the next batch, learning to perfect the dish through continuous feedback.
👨💻 Real-World Use Case 1: Adaptive Traffic Light Control
Imagine you’re a city planner optimizing traffic lights at a busy intersection. The system adjusts light timings—green for 30 seconds, red for 20—aiming to reduce congestion. It observes states (car queues, time of day) and picks actions (extend green, shorten red), earning rewards for smoother traffic flow.
Actor-Critic steps in like a traffic coordinator with a data analyst. The Actor chooses “extend green by 5 seconds,” the Critic evaluates the result (shorter queues = +reward), and the Actor refines its timing strategy. It learns to adapt to rush hours or quiet times, keeping traffic flowing efficiently.
👨💻 Real-World Use Case 2: Actor-Critic for Dynamic Ad Timing
Let’s say you’re building a smart content app (like YouTube or Instagram) that wants to place ads at the right moment.
If you place the ad too early, users may bounce.
If you wait too long, you miss monetization.
The system must learn when to show the ad based on real engagement data.
This is where Actor-Critic shines:
- 🎬 The Actor decides whether to show the ad now or wait.
- 📊 The Critic evaluates that decision based on how long the user stayed after the ad.
⚡ Why Use Actor-Critic?
- Teamwork Wins: Actor explores, Critic guides—better decisions together.
- Smooth Learning: Combines policy and value updates for stability.
- Flexible Approach: Works for both discrete and continuous actions.
- Scales Up: Handles complex tasks—control, games, or optimization.
Python Project: Actor-Critic Instagram Rewards Simulator
🎯 Goal
Train an agent using Actor-Critic to manage a 7-day Instagram-like marketing campaign. The agent starts with a fixed daily budget (100 units) and must allocate it across three actions: creating organic posts, running ads, and offering rewards (e.g., discounts or giveaways). The goal is to maximize user engagement (likes, comments, shares) over the 7 days. Each action has a different impact on engagement, and the agent learns to balance them. We’ll visualize the campaign’s daily engagement with a colorful bar chart and track cumulative engagement with a line graph.
🧠 What the Agent Learns
- How to allocate budget between organic posts, ads, and rewards to maximize engagement.
- The trade-offs between actions (e.g., ads might boost engagement quickly but cost more, while rewards build loyalty over time).
- A policy to optimize engagement over the 7-day campaign through Actor-Critic teamwork.
✅ Python Code
This project simulates a 7-day Instagram campaign and uses Matplotlib for static visualizations. The bar chart will show daily engagement (likes, comments, shares) in distinct colors, and the line graph will track cumulative engagement.
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
# --- Insta Rewards Simulator Environment ---
class InstaRewardsEnv:
def __init__(self, days=7, daily_budget=100):
self.days = days
self.current_day = 0
self.daily_budget = daily_budget
self.engagement = {'likes': 0, 'comments': 0, 'shares': 0} # Track engagement metrics
self.total_engagement = 0
self.daily_stats = [] # Store daily engagement for visualization
self.reset()
def reset(self):
self.current_day = 0
self.engagement = {'likes': 0, 'comments': 0, 'shares': 0}
self.total_engagement = 0
self.daily_stats = []
# State: [day, current_likes, current_comments, current_shares]
return torch.tensor([self.current_day, 0, 0, 0], dtype=torch.float32)
def step(self, action):
# Action: [budget_for_posts, budget_for_ads, budget_for_rewards]
# Ensure the total budget doesn't exceed daily_budget
budget_posts, budget_ads, budget_rewards = action
total_spent = budget_posts + budget_ads + budget_rewards
if total_spent > self.daily_budget:
# Normalize the budget allocation to fit within daily_budget
scale = self.daily_budget / total_spent
budget_posts *= scale
budget_ads *= scale
budget_rewards *= scale
# Simulate engagement based on budget allocation
# Organic posts: steady but low engagement
likes = budget_posts * 2 # 2 likes per unit spent
comments = budget_posts * 0.5 # 0.5 comments per unit
shares = budget_posts * 0.2 # 0.2 shares per unit
# Ads: high immediate engagement but costly
likes += budget_ads * 5 # 5 likes per unit
comments += budget_ads * 1 # 1 comment per unit
shares += budget_ads * 0.5 # 0.5 shares per unit
# Rewards: lower immediate engagement but boosts shares and loyalty
likes += budget_rewards * 1 # 1 like per unit
comments += budget_rewards * 0.5 # 0.5 comments per unit
shares += budget_rewards * 2 # 2 shares per unit (rewards encourage sharing)
# Update engagement
self.engagement['likes'] += likes
self.engagement['comments'] += comments
self.engagement['shares'] += shares
self.daily_stats.append([likes, comments, shares])
# Calculate reward as a weighted sum of engagement metrics
reward = likes + 2 * comments + 3 * shares # Shares are most valuable
self.total_engagement += reward
self.current_day += 1
done = (self.current_day >= self.days)
# State: [day, current_likes, current_comments, current_shares]
state = torch.tensor([self.current_day, self.engagement['likes'],
self.engagement['comments'], self.engagement['shares']],
dtype=torch.float32)
return state, reward, done
# --- Actor and Critic Networks ---
class Actor(nn.Module):
def __init__(self):
super(Actor, self).__init__()
self.net = nn.Sequential(
nn.Linear(4, 32), # Input: [day, likes, comments, shares]
nn.ReLU(),
nn.Linear(32, 3), # Output: [budget_posts, budget_ads, budget_rewards]
nn.Softmax(dim=-1) # Probabilities for budget allocation
)
def forward(self, x):
return self.net(x) * 100 # Scale to max budget of 100
class Critic(nn.Module):
def __init__(self):
super(Critic, self).__init__()
self.net = nn.Sequential(
nn.Linear(4, 32), # Input: state
nn.ReLU(),
nn.Linear(32, 1) # Output: state value
)
def forward(self, x):
return self.net(x)
# --- Actor-Critic Training ---
def train_insta_rewards_actor_critic(env, episodes=100, gamma=0.99, lr=0.001):
actor = Actor()
critic = Critic()
actor_opt = optim.Adam(actor.parameters(), lr=lr)
critic_opt = optim.Adam(critic.parameters(), lr=lr)
rewards_per_episode = []
for ep in range(episodes):
state = env.reset()
total_reward = 0
done = False
while not done:
# Actor picks action (budget allocation)
probs = actor(state)
dist = torch.distributions.Categorical(probs)
action_idx = dist.sample()
# Convert action_idx to budget allocation
budget = [0, 0, 0]
budget[action_idx] = env.daily_budget
action = torch.tensor(budget, dtype=torch.float32)
log_prob = dist.log_prob(action_idx)
# Take action
next_state, reward, done = env.step(action)
total_reward += reward
# Critic evaluates
value = critic(state)
next_value = critic(next_state).detach()
td_target = reward + gamma * next_value * (1 - int(done))
td_error = td_target - value
# Update Critic
critic_loss = td_error.pow(2)
critic_opt.zero_grad()
critic_loss.backward()
critic_opt.step()
# Update Actor
actor_loss = -log_prob * td_error.detach()
actor_opt.zero_grad()
actor_loss.backward()
actor_opt.step()
state = next_state
rewards_per_episode.append(total_reward)
return actor, rewards_per_episode
# --- Visualize the Campaign Performance ---
def visualize_insta_rewards(actor, env):
state = env.reset()
done = False
while not done:
with torch.no_grad():
action = actor(state)
state, reward, done = env.step(action)
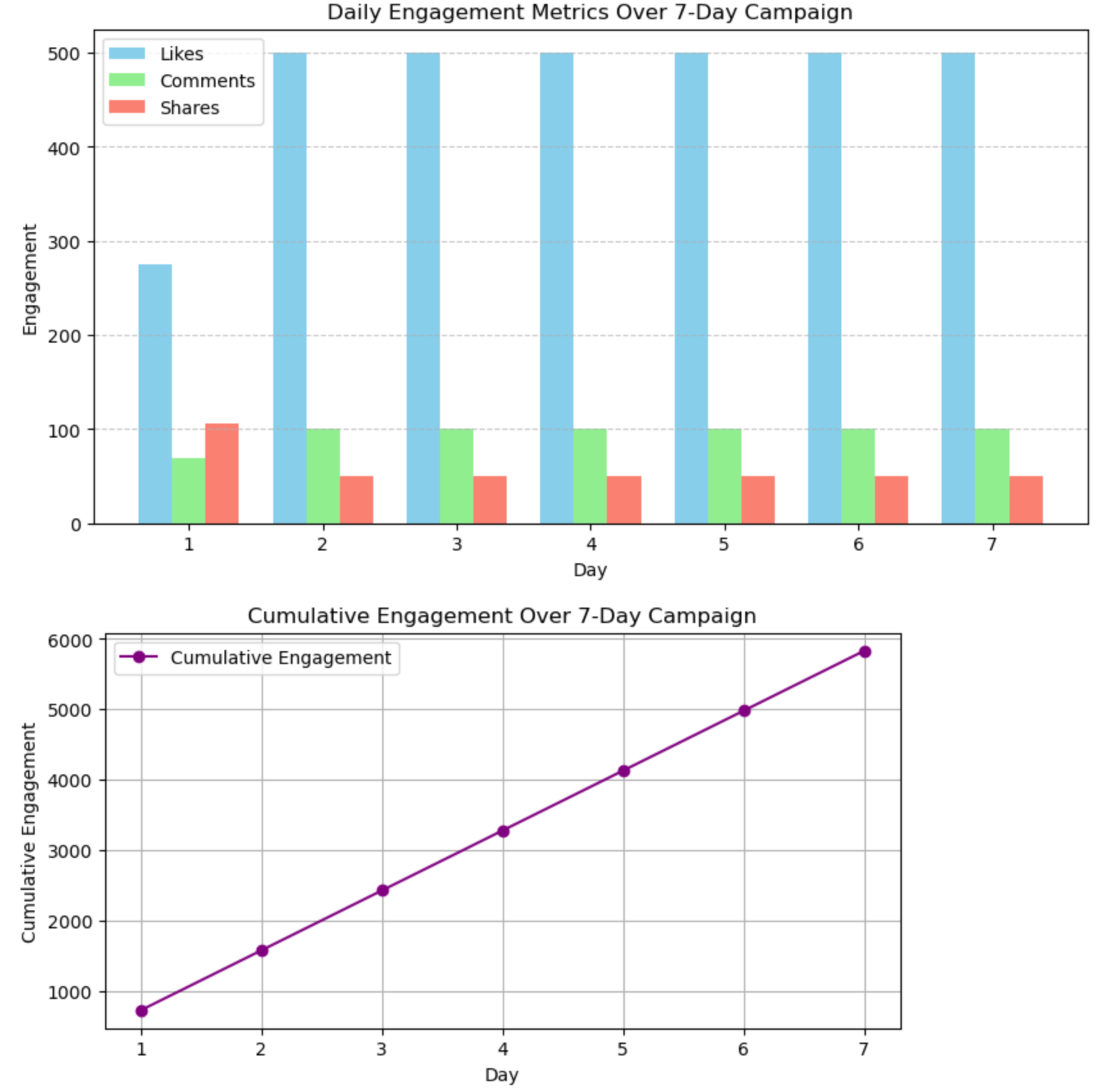
# Bar chart for daily engagement
days = np.arange(1, env.days + 1)
likes = [stat[0] for stat in env.daily_stats]
comments = [stat[1] for stat in env.daily_stats]
shares = [stat[2] for stat in env.daily_stats]
plt.figure(figsize=(10, 5))
bar_width = 0.25
plt.bar(days - bar_width, likes, bar_width, label='Likes', color='skyblue')
plt.bar(days, comments, bar_width, label='Comments', color='lightgreen')
plt.bar(days + bar_width, shares, bar_width, label='Shares', color='salmon')
plt.xlabel('Day')
plt.ylabel('Engagement')
plt.title('Daily Engagement Metrics Over 7-Day Campaign')
plt.xticks(days)
plt.legend()
plt.grid(True, axis='y', linestyle='--', alpha=0.7)
plt.show()
# Line graph for cumulative engagement
cumulative_engagement = np.cumsum([likes[i] + 2 * comments[i] + 3 * shares[i] for i in range(len(likes))])
plt.figure(figsize=(8, 4))
plt.plot(days, cumulative_engagement, marker='o', color='purple', label='Cumulative Engagement')
plt.xlabel('Day')
plt.ylabel('Cumulative Engagement')
plt.title('Cumulative Engagement Over 7-Day Campaign')
plt.xticks(days)
plt.grid(True)
plt.legend()
plt.show()
# --- Run It All ---
env = InstaRewardsEnv()
actor, rewards = train_insta_rewards_actor_critic(env)
visualize_insta_rewards(actor, env)
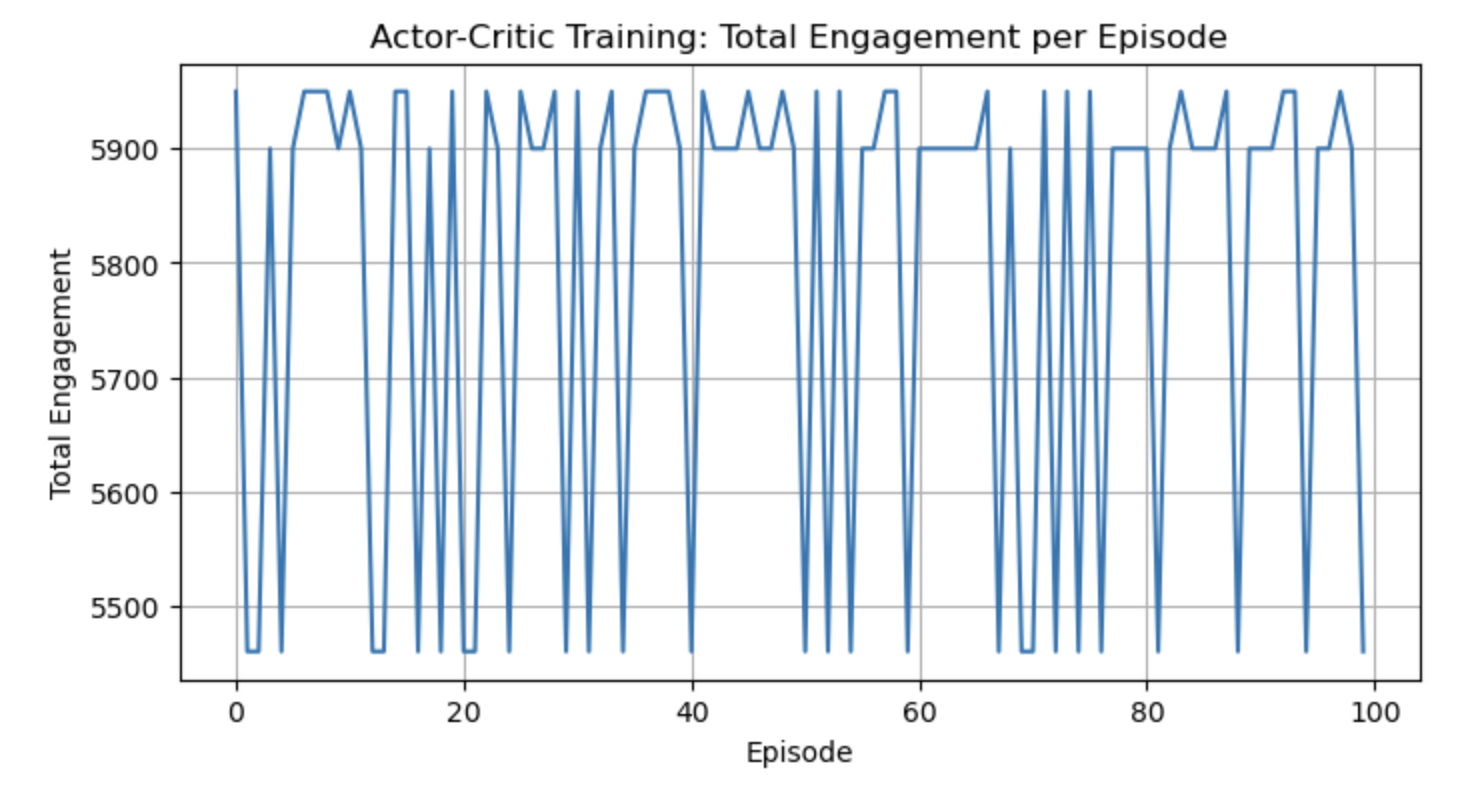
# --- Reward Curve ---
plt.figure(figsize=(8, 4))
plt.plot(rewards)
plt.title("Actor-Critic Training: Total Engagement per Episode")
plt.xlabel("Episode")
plt.ylabel("Total Engagement")
plt.grid(True)
plt.show()
Install Dependencies:
!pip install torch matplotlib numpy
🖼️ Jupyter Notebook Result
🖼️ What You’ll See
- A colorful bar chart of daily engagement:
- Likes (sky blue), Comments (light green), and Shares (salmon) for each of the 7 days.
- Each metric is clearly distinguished by color, showing how the agent’s budget allocation impacts engagement.
- A line graph of cumulative engagement:
- A purple line with markers showing the total engagement (weighted sum of likes, comments, shares) over the 7 days.
- Highlights the campaign’s overall success.
- A training graph showing total engagement over episodes:
- Starts low (poor budget allocation).
- Climbs as the agent learns to balance posts, ads, and rewards for maximum engagement.
How It Works
- Insta Rewards Setup: A 7-day campaign where the agent allocates a daily budget (100 units) across organic posts, ads, and rewards. State: [day, current_likes, current_comments, current_shares]. Actions: Allocate budget to [posts, ads, rewards].
- Engagement Mechanics:
- Organic Posts: Steady but low engagement (2 likes, 0.5 comments, 0.2 shares per unit).
- Ads: High immediate engagement (5 likes, 1 comment, 0.5 shares per unit) but costly.
- Rewards: Lower immediate engagement (1 like, 0.5 comments) but high shares (2 shares per unit) for loyalty.
- Actor-Critic Logic:
- Actor: Neural net outputs budget allocation, learns to maximize engagement.
- Critic: Estimates state values, guides the Actor via TD error.
- Visualization:
- Bar chart shows daily engagement metrics in distinct colors.
- Line graph tracks cumulative engagement, showing the campaign’s growth.
💬 Join the DecodeAI WhatsApp Channel for regular AI updates → Click here