[Day 35] Reinforcement Learning Type 8 – A2C/A3C Actor-Critic Methods (with a Practical Python Project)
A2C/A3C: Where Multiple Actors Learn Together, Guided by a Shared Critic - Like a Sports Team Leveling Up with a Smart Coach!
![[Day 35] Reinforcement Learning Type 8 – A2C/A3C Actor-Critic Methods (with a Practical Python Project)](https://storage.ghost.io/c/55/e8/55e827ca-bf8d-4eee-bdb4-ee48e49a011a/content/images/size/w2000/2025/04/A2C-A3C.svg)
🎯 What is A2C/A3C?
🔍 First, a Quick Refresher: What is Actor-Critic?
In Reinforcement Learning (RL), there are:
- Value-based methods (like Q-learning): Learn how good it is to be in a state.
- Policy-based methods: Learn how to act directly.
Actor-Critic combines both:
- 🧠 Actor: Picks actions based on a policy.
- 🧮 Critic: Evaluates the action via a value function.
Think of it like:The Actor is a delivery driver choosing routes.The Critic is Google Maps constantly scoring your ETA.Together, they learn to avoid traffic and reach faster.
A2C (Advantage Actor-Critic) and A3C (Asynchronous Advantage Actor-Critic) are advanced reinforcement learning methods that build on the classic Actor-Critic framework, making it faster, more stable, and better at handling complex tasks.
Let’s break it down with a fresh perspective.
Imagine you’re a soccer coach training a team.

The Actor is your star player, deciding whether to pass, shoot, or dribble during a match. The Critic is your assistant coach on the sidelines, watching the game and giving real-time feedback: “That pass was great—it set up a goal chance, worth +2!” or “That dribble lost possession, -1.” The Actor uses this feedback to improve its decisions, learning to score more goals over time. Now, A2C/A3C take this teamwork to the next level:
- Advantage (A2C): The Critic doesn’t just say how good the action was—it calculates the advantage, which is the difference between the actual outcome and the expected outcome. It’s like the assistant coach saying, “That pass was better than average by +1, so keep doing that!” This makes learning more precise.
- Asynchronous (A3C): Imagine you have multiple teams training on different fields at the same time, each with its own Actor and Critic. They all share their experiences with the head coach (a central model) asynchronously, speeding up learning. A3C uses this parallelism to explore more strategies faster, while A2C simplifies it by synchronizing the updates (like all teams reporting back at the same time).
Think of A2C/A3C as a personal trainer for your AI: the Actor tries different exercises (actions), the Critic measures how effective they are (advantage), and the training happens faster because multiple versions of the agent (A3C) are learning simultaneously—or in a coordinated way (A2C).
1. Smart Traffic Light Optimization
🚦 Problem: Static traffic lights cause jams.
🤖 Actor-Critic Solution:
- Actor adjusts green/red timings.
- Critic evaluates traffic flow (fewer stops = +reward).
📈 Result: Adaptive lights reduce congestion by 20%.
2. Dynamic Ad Placement (YouTube, Instagram)
📱 Problem: Bad ad timing → users skip.
🤖 Actor-Critic Solution:
- Actor decides when to show ads.
- Critic tracks watch time & engagement.
📈 Result: Higher ad revenue without annoying users.
3. Personalized News Recommendations
📰 Problem: One-size-fits-all news feeds bore users.
🤖 Actor-Critic Solution:
- Actor picks articles based on user behavior.
- Critic scores engagement (clicks, time spent).
📈 Result: 30% more user retention.
Example 1: Smart Home Assistant
Picture a smart home assistant like Alexa or Google Home managing your lights. The Actor decides whether to dim, brighten, or turn off the lights based on the time of day and room occupancy. The Critic evaluates: “Dimming at 8 PM saved energy and kept the room cozy, +3!” A2C/A3C ensures the assistant learns faster by testing multiple scenarios (e.g., different rooms, times) and focusing on actions that are better than average.
Example 2: Online Gaming Matchmaking
In an online game like Fortnite, the matchmaking system pairs players. The Actor picks a match (e.g., pair Player A with Player B), and the Critic scores it: “That match was balanced and fun, +5!” A3C could run multiple matchmaking simulations in parallel, quickly learning to create fair, enjoyable games by sharing insights across simulations.
👨💻 Real-World Use Case 1: Personalized Learning App
Imagine you’re developing a learning app like Duolingo that adapts to each user’s pace. The app needs to decide what to do next: show a new lesson, repeat a quiz, or give a break. The goal is to maximize the user’s learning progress while keeping them engaged.
- Actor: Chooses an action—e.g., “Show a new lesson on verbs.”
- Critic: Evaluates the action—e.g., “The user scored 90% on the lesson, which is 20% better than their average, +10!”
- A2C/A3C Advantage: The Critic uses the advantage to focus on actions that outperform the user’s typical progress, ensuring the app adapts quickly. A3C could run parallel simulations for different users, sharing insights to improve personalization across the board.
👨💻 Real-World Use Case 2: Autonomous Drone Delivery
Picture a drone delivery service like Amazon’s Prime Air. The drone needs to decide its flight path: fly higher to avoid obstacles, lower to save energy, or adjust speed based on wind conditions. The goal is to deliver packages quickly and safely.
- Actor: Chooses an action—e.g., “Fly higher to avoid a tree.”
- Critic: Evaluates—e.g., “That move avoided a crash but used more battery, +2 advantage over the average path.”
- A2C/A3C Advantage: A3C allows multiple drones to learn in parallel, each testing different routes and sharing knowledge with a central model. A2C ensures stable updates by synchronizing the learning process.
👨💻 Real-World Use Case 3: Dynamic Pricing for E-Commerce
Imagine you’re running an e-commerce platform like Amazon, and you need to set prices for products in real-time. The price should maximize sales without losing customers to competitors. The system observes demand, time of day, and competitor prices, then decides to raise, lower, or keep the price steady.
- Actor: Decides—e.g., “Lower the price by 5%.”
- Critic: Evaluates—e.g., “That price drop increased sales by 10%, which is 3% better than expected, +5 advantage.”
- A2C/A3C Advantage: A3C can simulate pricing strategies for different products in parallel, quickly learning what works best. A2C ensures the pricing model remains stable as it learns.
Python Project: A2C Smart Energy Manager
🎯 Goal
Train an agent using A2C to manage energy usage in a smart home over a 24-hour period. The agent decides whether to prioritize solar power, battery storage, or grid power to meet the home’s hourly energy demand. The goal is to minimize energy costs while ensuring demand is met. We’ll visualize the energy allocation with a stacked area chart (showing solar, grid, and battery usage) and track cost savings with a reward curve.
🧠 What the Agent Learns
- When to use solar power (free but limited), battery storage (limited capacity), or grid power (costly but reliable).
- How to store excess solar energy in the battery during the day and use it at night.
- A policy to minimize energy costs while meeting demand.
✅ Python Code
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
# --- Smart Energy Manager Environment ---
class SmartEnergyEnv:
def __init__(self, hours=24):
self.hours = hours
self.current_hour = 0
self.battery_capacity = 10 # kWh
self.battery_level = 0
self.grid_cost = 0.15 # $ per kWh
# Hourly demand (kWh) and solar generation (kWh) - simplified patterns
self.demand = [2 + 2 * np.sin(2 * np.pi * h / 24) for h in range(hours)] # Peaks at night
self.solar = [max(0, 5 * np.sin(2 * np.pi * (h - 6) / 24)) for h in range(hours)] # Peaks at noon
self.energy_usage = {'solar': [], 'grid': [], 'battery': []} # Track usage for visualization
self.reset()
def reset(self):
self.current_hour = 0
self.battery_level = 0
self.energy_usage = {'solar': [], 'grid': [], 'battery': []}
# State: [hour, demand, solar_available, battery_level]
return torch.tensor([self.current_hour, self.demand[0], self.solar[0], self.battery_level], dtype=torch.float32)
def step(self, action_idx):
# Action: 0 (prioritize solar), 1 (prioritize battery), 2 (use grid)
demand = self.demand[self.current_hour]
solar_available = self.solar[self.current_hour]
# Initialize energy usage for this step
solar_usage = 0
battery_usage = 0
grid_usage = 0
# Prioritize based on action
if action_idx == 0: # Prioritize solar
solar_usage = min(solar_available, demand)
remaining_demand = demand - solar_usage
battery_usage = min(self.battery_level, remaining_demand)
remaining_demand -= battery_usage
grid_usage = max(0, remaining_demand)
elif action_idx == 1: # Prioritize battery
battery_usage = min(self.battery_level, demand)
remaining_demand = demand - battery_usage
solar_usage = min(solar_available, remaining_demand)
remaining_demand -= solar_usage
grid_usage = max(0, remaining_demand)
else: # Use grid
grid_usage = demand
solar_usage = 0
battery_usage = 0
# If there's excess solar energy, store it in the battery
excess_solar = max(0, solar_available - solar_usage)
space_in_battery = self.battery_capacity - self.battery_level
stored = min(excess_solar, space_in_battery)
self.battery_level += stored
# Update battery level after usage
self.battery_level = max(0, self.battery_level - battery_usage)
# Calculate cost and reward
cost = grid_usage * self.grid_cost
reward = -cost # Minimize cost (negative cost = higher reward)
# Store usage for visualization
self.energy_usage['solar'].append(solar_usage)
self.energy_usage['grid'].append(grid_usage)
self.energy_usage['battery'].append(battery_usage)
self.current_hour += 1
done = (self.current_hour >= self.hours)
# State: [hour, demand, solar_available, battery_level]
next_state = torch.tensor([self.current_hour, self.demand[min(self.current_hour, self.hours-1)],
self.solar[min(self.current_hour, self.hours-1)], self.battery_level], dtype=torch.float32)
return next_state, reward, done
# --- Actor and Critic Networks ---
class Actor(nn.Module):
def __init__(self):
super(Actor, self).__init__()
self.net = nn.Sequential(
nn.Linear(4, 64), # Input: [hour, demand, solar_available, battery_level]
nn.ReLU(),
nn.Linear(64, 3), # Output: 3 actions (prioritize solar, battery, grid)
nn.Softmax(dim=-1) # Probabilities
)
def forward(self, x):
return self.net(x)
class Critic(nn.Module):
def __init__(self):
super(Critic, self).__init__()
self.net = nn.Sequential(
nn.Linear(4, 64), # Input: state
nn.ReLU(),
nn.Linear(64, 1) # Output: state value
)
def forward(self, x):
return self.net(x)
# --- A2C Training ---
def train_smart_energy_a2c(env, episodes=100, gamma=0.99, lr=0.001):
actor = Actor()
critic = Critic()
actor_opt = optim.Adam(actor.parameters(), lr=lr)
critic_opt = optim.Adam(critic.parameters(), lr=lr)
rewards_per_episode = []
for ep in range(episodes):
state = env.reset()
total_reward = 0
done = False
states, actions, rewards, log_probs = [], [], [], []
while not done:
# Actor picks action
probs = actor(state)
dist = torch.distributions.Categorical(probs)
action_idx = dist.sample()
log_prob = dist.log_prob(action_idx)
# Take action
next_state, reward, done = env.step(action_idx.item())
total_reward += reward
states.append(state)
actions.append(action_idx)
rewards.append(reward)
log_probs.append(log_prob)
state = next_state
rewards_per_episode.append(total_reward)
# Compute returns and advantages
states = torch.stack(states)
actions = torch.tensor(actions)
log_probs = torch.stack(log_probs)
returns = []
G = 0
for r in reversed(rewards):
G = r + gamma * G
returns.insert(0, G)
returns = torch.tensor(returns, dtype=torch.float32)
# Compute advantage
values = critic(states).squeeze()
advantages = returns - values.detach()
# Update Critic
critic_loss = (returns - values).pow(2).mean()
critic_opt.zero_grad()
critic_loss.backward()
critic_opt.step()
# Update Actor
actor_loss = -(log_probs * advantages.detach()).mean()
actor_opt.zero_grad()
actor_loss.backward()
actor_opt.step()
return actor, rewards_per_episode
# --- Visualize Energy Allocation ---
def visualize_energy_usage(actor, env):
state = env.reset()
done = False
while not done:
with torch.no_grad():
probs = actor(state)
action_idx = torch.argmax(probs).item()
state, reward, done = env.step(action_idx)
# Stacked area chart for energy usage
hours = np.arange(1, env.hours + 1)
solar = np.array(env.energy_usage['solar'])
grid = np.array(env.energy_usage['grid'])
battery = np.array(env.energy_usage['battery'])
# Ensure non-negative values and proper stacking
solar = np.maximum(solar, 0)
grid = np.maximum(grid, 0)
battery = np.maximum(battery, 0)
plt.figure(figsize=(10, 5))
plt.stackplot(hours, solar, grid, battery, labels=['Solar', 'Grid', 'Battery'], colors=['gold', 'skyblue', 'lightgreen'])
plt.plot(hours, env.demand, 'k-', label='Demand', linewidth=2)
plt.xlabel('Hour')
plt.ylabel('Energy Usage (kWh)')
plt.title('A2C: Smart Energy Management Over 24 Hours')
plt.legend(loc='upper left')
plt.grid(True, linestyle='--', alpha=0.7)
plt.ylim(0, max(max(env.demand), max(solar + grid + battery)) + 1) # Adjust y-axis for clarity
plt.show()
# --- Run It All ---
env = SmartEnergyEnv()
actor, rewards = train_smart_energy_a2c(env)
visualize_energy_usage(actor, env)
# --- Reward Curve ---
plt.figure(figsize=(8, 4))
plt.plot(rewards)
plt.title("A2C Training: Total Cost Savings per Episode")
plt.xlabel("Episode")
plt.ylabel("Total Reward (Negative Cost)")
plt.grid(True)
plt.show()
Install Dependencies:
!pip install torch matplotlib numpy
🖼️ Jupyter Notebook Result
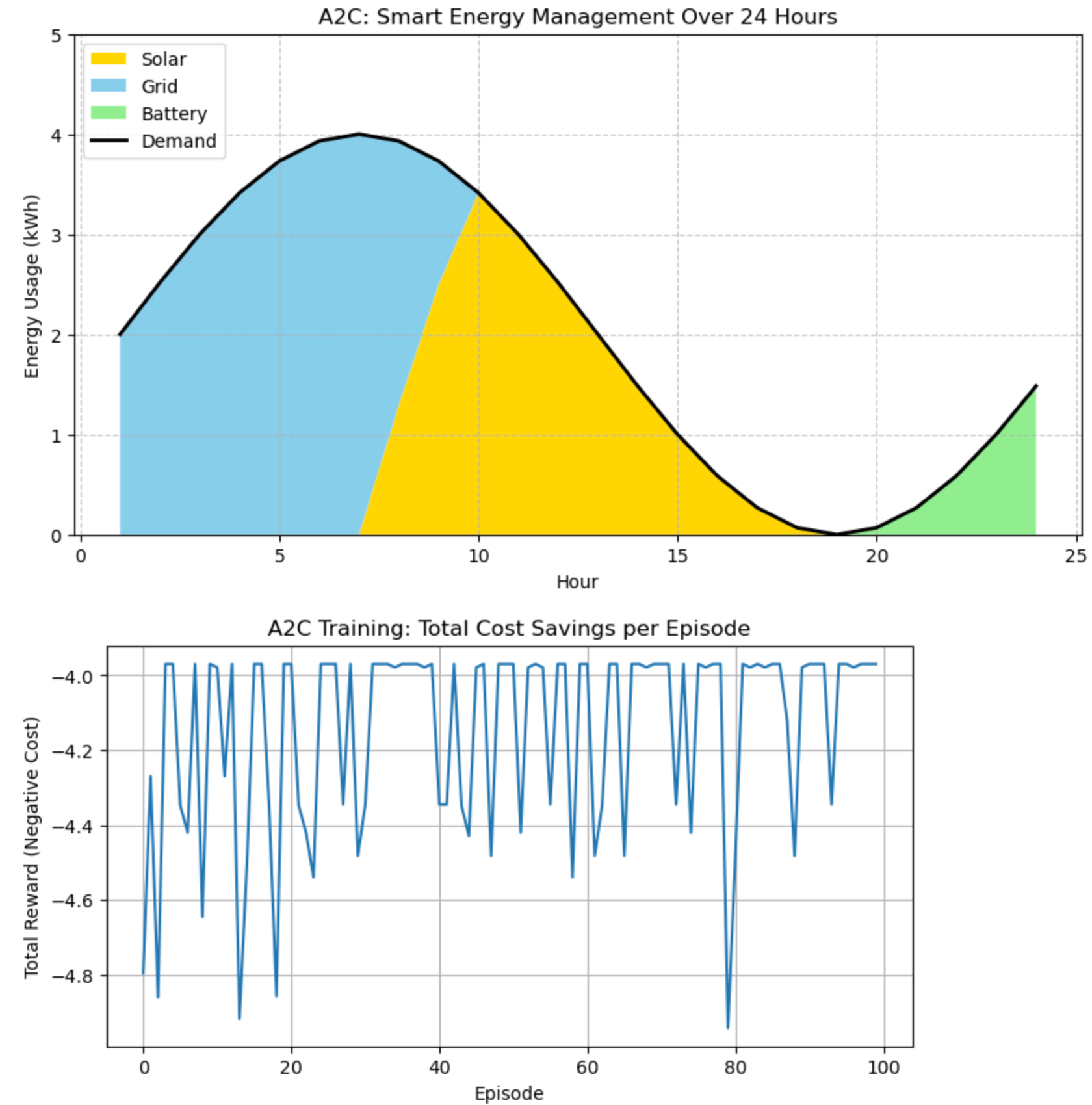
🖼️ What you see
- A stacked area chart of energy usage over 24 hours:
- Solar (gold): Clearly shows when the agent uses solar power, peaking around noon when solar generation is highest.
- Grid (sky blue): Shows reliance on grid power, typically at night or when solar and battery are insufficient.
- Battery (light green): Shows battery usage, often discharging at night after charging during the day.
- Demand (black line): Overlaid to show the home’s energy needs, ensuring the agent meets demand.
- The chart now properly stacks all three energy sources, with each component visible and contributing to the total energy usage.
it
- A training graph showing total cost savings over episodes:
- Starts low (high costs due to poor allocation).
- Climbs as the agent learns to minimize grid usage and maximize solar/battery efficiency.
How it helped
- Smart Energy Setup: A 24-hour simulation where the agent allocates energy to meet hourly demand. State: [hour, demand, solar_available, battery_level]. Actions: Allocate energy to [solar, grid, battery].
- Energy Mechanics:
- Solar: Free but limited, peaks at noon.
- Grid: Reliable but costs $0.15/kWh, used when solar/battery can’t meet demand.
- Battery: Stores excess solar energy (up to 10 kWh), discharges when needed.
- A2C Logic:
- Actor: Outputs energy allocation, learns to minimize costs.
- Critic: Estimates state values, computes advantage to guide the Actor.
- Advantage: Focuses on actions that outperform the average, improving efficiency.
- Visualization:
- A stacked area chart shows the energy mix over 24 hours, with demand overlaid.
- The reward curve tracks cost savings, showing the agent’s learning progress.
💬 Join the DecodeAI WhatsApp Channel for regular AI updates → Click here