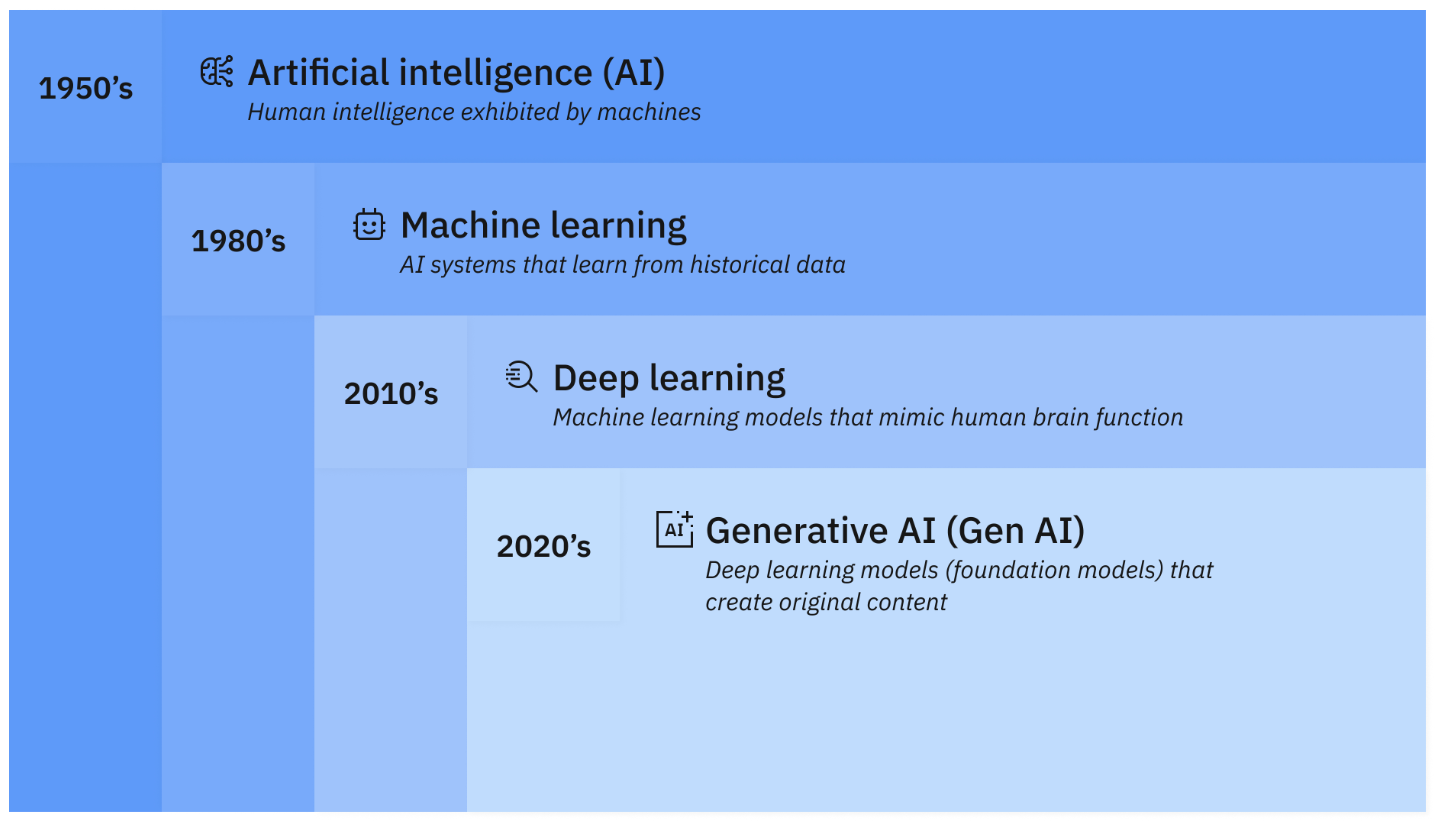
[Day 4] Understanding of Deep Learning
Deep learning uses layered neural networks to mimic the brain, powering smart tech from medical imaging to AI-generated videos. Dive into the future.
![[Day 4] Understanding of Deep Learning](https://storage.ghost.io/c/55/e8/55e827ca-bf8d-4eee-bdb4-ee48e49a011a/content/images/size/w2000/2025/03/_--visual-selection--5-.svg)
Deep learning has revolutionized how machines learn, process information, and solve complex problems, driving advancements in healthcare, autonomous vehicles, natural language processing, and more. But what exactly is deep learning, and why has it become such a transformative technology? Let's find out.
What is Deep Learning?
Deep learning is a subset of artificial intelligence (AI) and machine learning (ML) that focuses on using artificial neural networks (ANNs) to mimic the way the human brain processes information. These networks consist of multiple interconnected layers of nodes (neurons), each layer extracting increasingly
complex features from the data.
Why “Deep”?
The "deep" in deep learning refers to the presence of multiple layers in a neural network. These layers allow the model to learn hierarchical features:
- Shallow Layers: Capture basic patterns, such as edges in an image.
- Deeper Layers: Combine basic features into more complex structures, such as objects or faces.
Unlike traditional machine learning, where feature engineering is manual, deep learning automates this process, making it particularly effective for tasks involving unstructured data like images, audio, and text.
Why Did Deep Learning Emerge?
Deep learning arose to address the limitations of traditional machine learning. Key factors contributing to its rise include:
- Data Explosion: The advent of the internet, smartphones, and IoT devices has led to the generation of massive amounts of data. Deep learning thrives on these large datasets, uncovering patterns that traditional methods cannot handle.
- Advances in Hardware: Training deep neural networks requires immense computational power. Modern GPUs and Tensor Processing Units (TPUs) enable faster training of complex models.
- Improved Algorithms: Innovations like backpropagation, dropout (to prevent overfitting), and advanced optimizers (like Adam) have made deep learning models more accurate and efficient.
- Accessible Tools: Open-source frameworks like TensorFlow, PyTorch, and Keras have made deep learning more accessible to researchers and developers worldwide.
How Does Deep Learning Work?
At its core, deep learning models learn from data by passing it through layers of a neural network. Here’s a breakdown of the process:
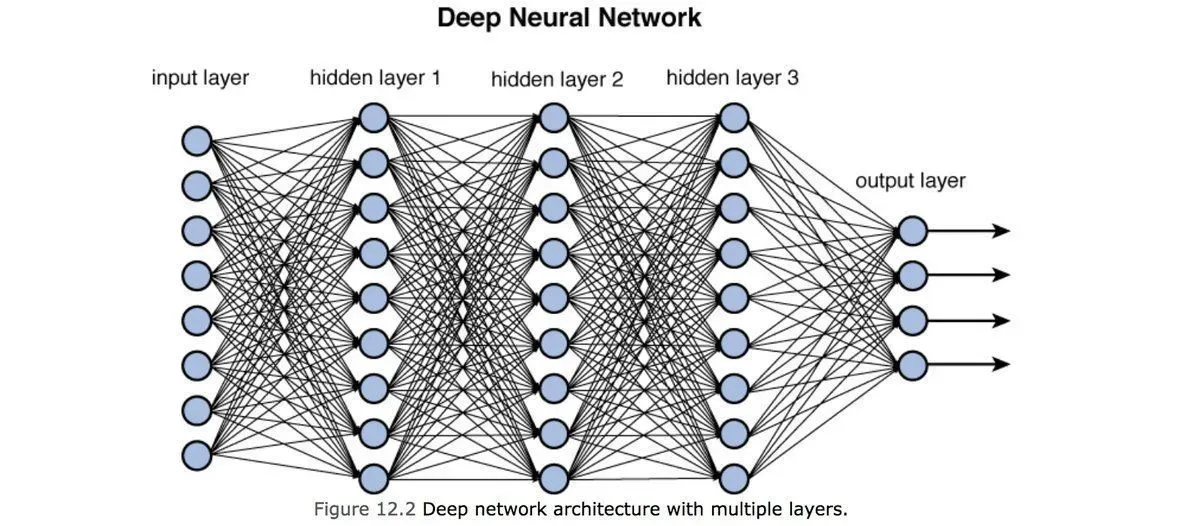
1. The Layers
- Input Layer: This is where raw data enters the network. For example, in an image recognition task, the input layer processes the pixel values of an image.
- Hidden Layers: These intermediate layers extract features by applying mathematical transformations. Each neuron in these layers processes the data it receives, learns patterns, and passes the result to the next layer.
- Output Layer: The final layer provides the output, such as a classification (e.g., "cat" or "not cat") or a prediction.
The Blackbox: Deep learning is called a "black box" because its decision-making process is opaque and hard to interpret. While we understand the mathematical operations within each layer, the complexity of the layers, high-dimensional feature representations, and non-linear transformations make it difficult to explain how or why specific predictions are made. This lack of transparency is a challenge in applications where accountability and interpretability are crucial.
2. Training the Model
Training involves:
- Forward Propagation: Data flows through the network, and predictions are made.
- Loss Calculation: The difference between predicted and actual outputs (error) is calculated using a loss function.
- Backpropagation: The error is propagated backward through the network, adjusting the weights of neurons to minimize the loss.
- Optimization: Optimizers like Adam or SGD (Stochastic Gradient Descent) update weights iteratively to improve accuracy.
This cycle continues over multiple iterations (epochs) until the model achieves an acceptable level of performance.
How does a Machine Learns (The Process)
- Learning Process
- Improvement Process
1. Learning Process
The basic components of a neural network are the input layer, hidden layers, and output layer, each made up of multiple nodes (or neurons).
How Do Nodes Work?
Each node in the network has weights and a bias associated with it. These parameters help the network decide how important each input is. The process can be broken down as follows:
- Transfer Function: The node calculates the weighted sum of the inputs and the bias using the formula:
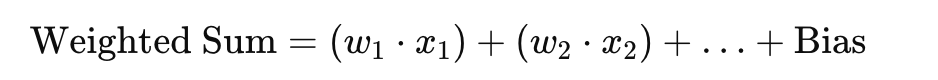
2. Activation Function: After the weighted sum is calculated, an activation function determines the node's output. For example:
- If the result is greater than 0.5, the output could be 1.
- Otherwise, it could be 0.
This mechanism ensures the network learns non-linear relationships between inputs and outputs.
Once the inputs are processed through the network to produce an output, the network evaluates how accurate the prediction was using a loss function. A common loss function is the Mean Squared Error, which measures the difference between the predicted output (Y^) and the actual output (Y).
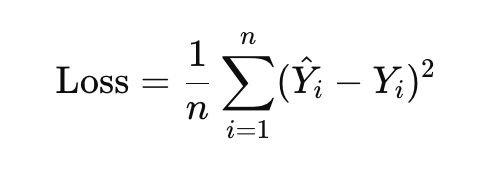
Here:
- Y^: Predicted value
- Y: Actual value
- n: Number of samples
The goal of the network is to reduce the loss, which means improving its predictions.
Let's understand it in a detailed manner.
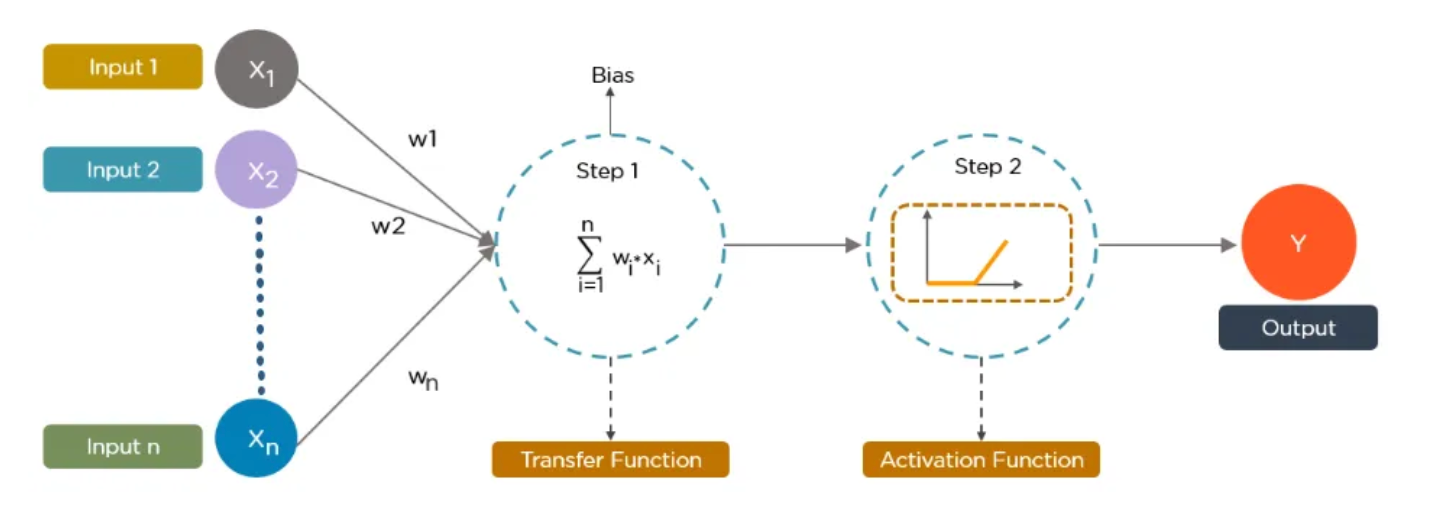
Inputs (X1, X2, ..., Xn)
These represent the data or features you are providing to the model. For example, if you’re training a neural network to predict house prices:
- X1 might be the size of the house.
- X2 could be the number of bedrooms.
- Xn represents other features like location or age of the house.
Weights (W1, W2, ..., Wn)
Each input has an associated weight. These weights are numbers that tell the neuron how important each input is. For example:
- A large weight for X1 means the size of the house is a crucial factor for predicting the price.
Step 1: Summation (∑)
The neuron adds up all the weighted inputs. This is done using the formula:
Summation = (W1 * X1) + (W2 * X2) + ... + (Wn * Xn) + Bias
- The bias is another number added to the summation to help the neuron adjust its prediction.
Transfer Function
The result of the summation is passed through a transfer function, which is usually just the summation itself in this step. Think of this as the raw calculation the neuron makes before making a decision.
Step 2: Activation Function
The output of the transfer function is passed through an activation function. This function decides whether the neuron should “activate” (send a signal forward) or stay silent. Common activation functions include:
- ReLU (Rectified Linear Unit): Outputs zero for negative values and the value itself for positive values.
- Sigmoid: Compresses the output to a range between 0 and 1.
This step introduces non-linearity, helping the neural network learn complex patterns.
Output (Y)
Finally, the result after applying the activation function is sent to the next layer (if it’s a multi-layer network) or becomes the final output (e.g., predicted price of the house).
This whole process mimics how the brain works. Each neuron processes some information and passes it forward, contributing to the decision-making of the overall network. When you connect many such neurons, they form a neural network capable of solving complex problems like image recognition, language translation, and more.
2. Improvement Process
To improve its predictions, the network adjusts its weights and biases using a process called backpropagation and gradient descent:
- Backpropagation: The network moves backward from the output layer to the input layer, calculating how much each weight and bias contributed to the error (loss).
- Gradient Descent: The weights and biases are updated in small steps in the direction that reduces the loss. Over multiple iterations, this process helps the network learn and make better predictions.
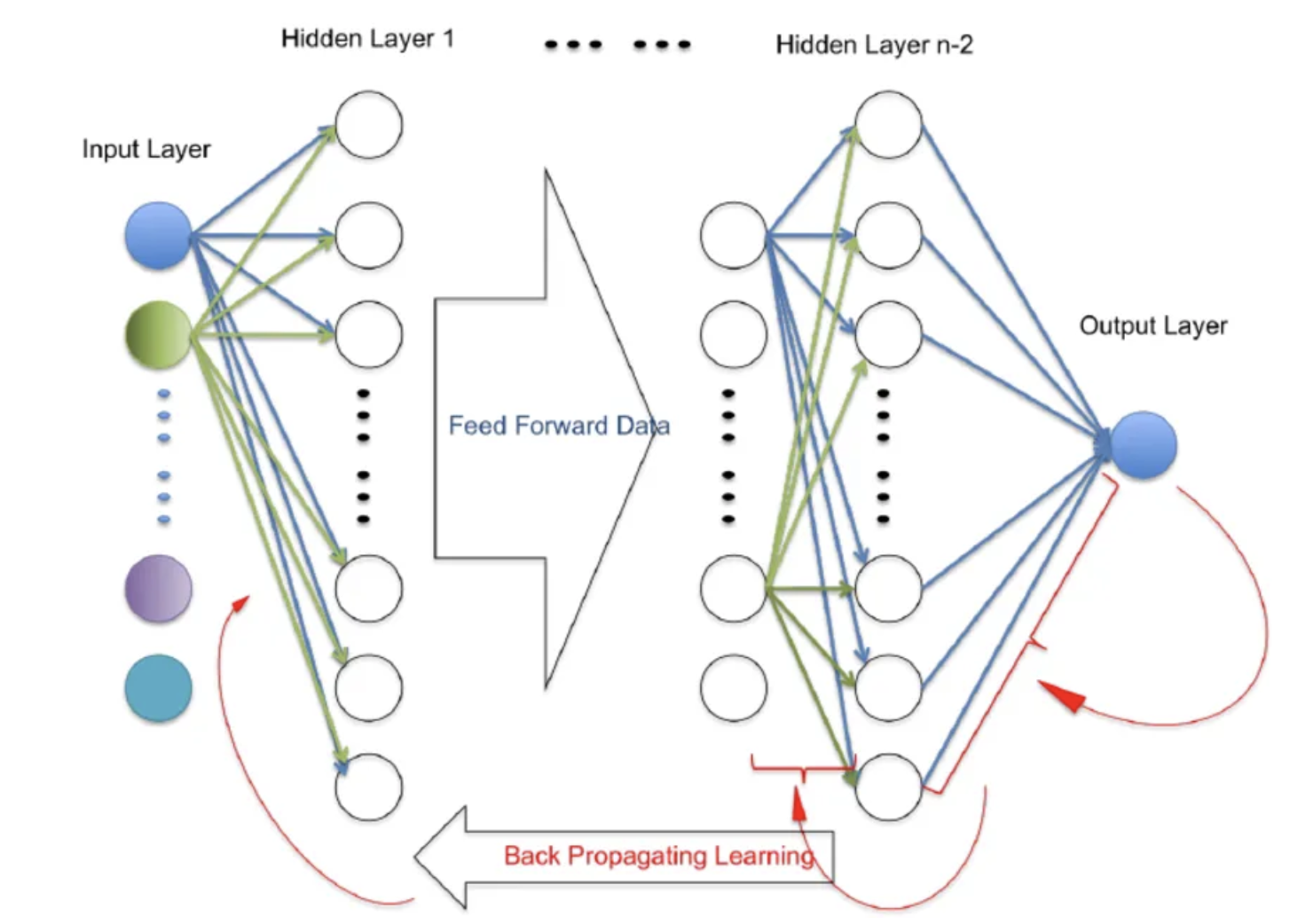
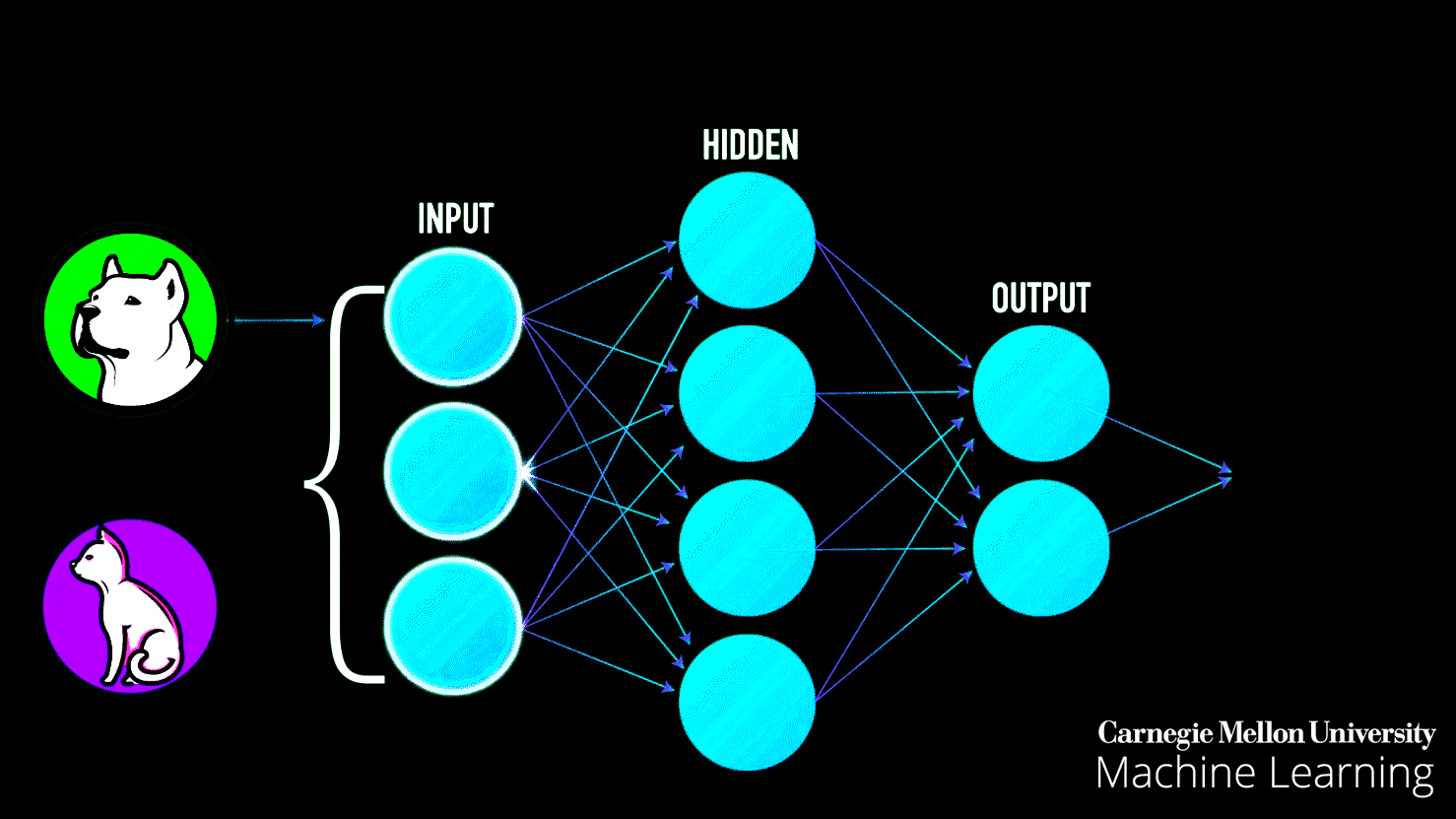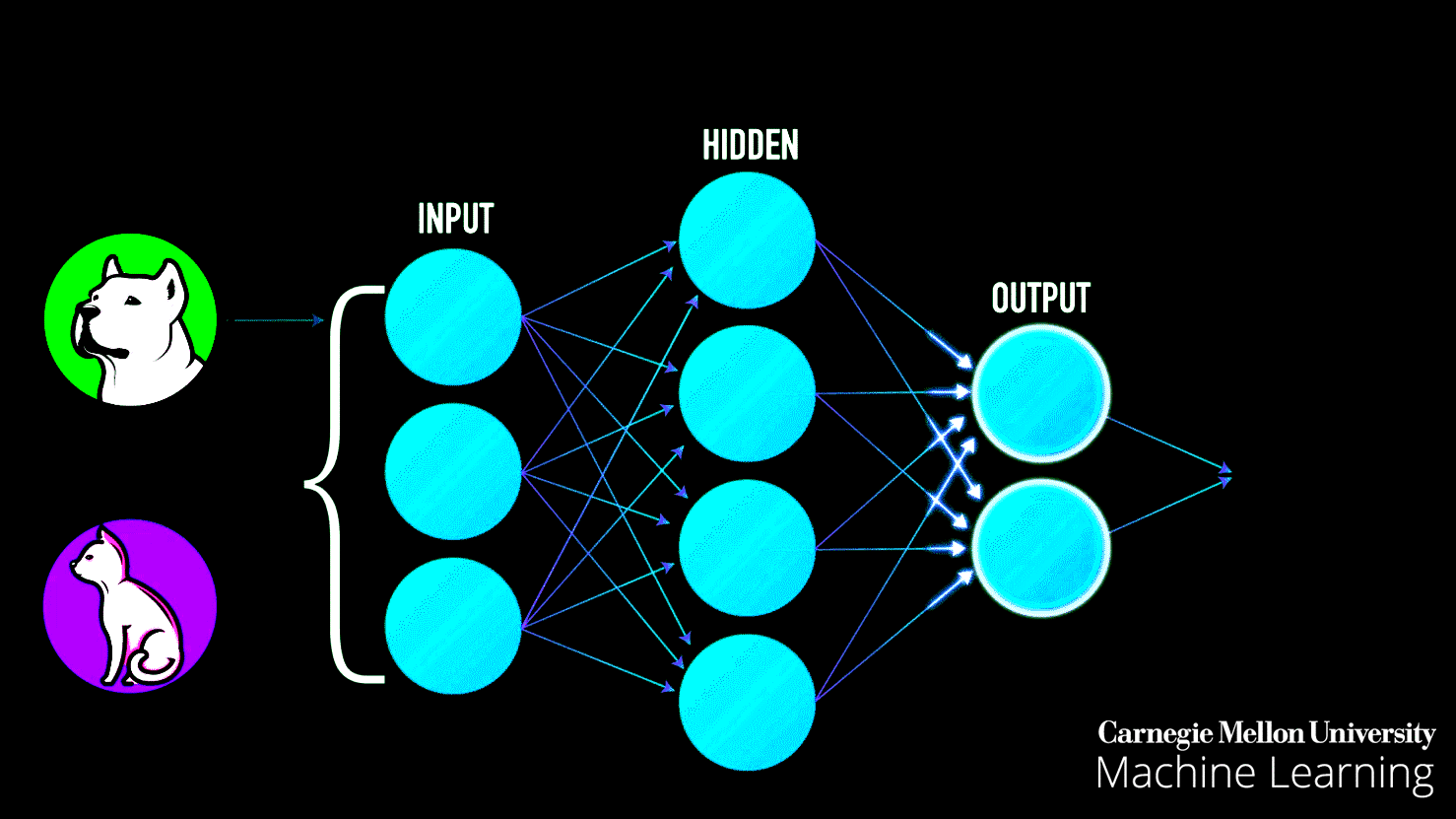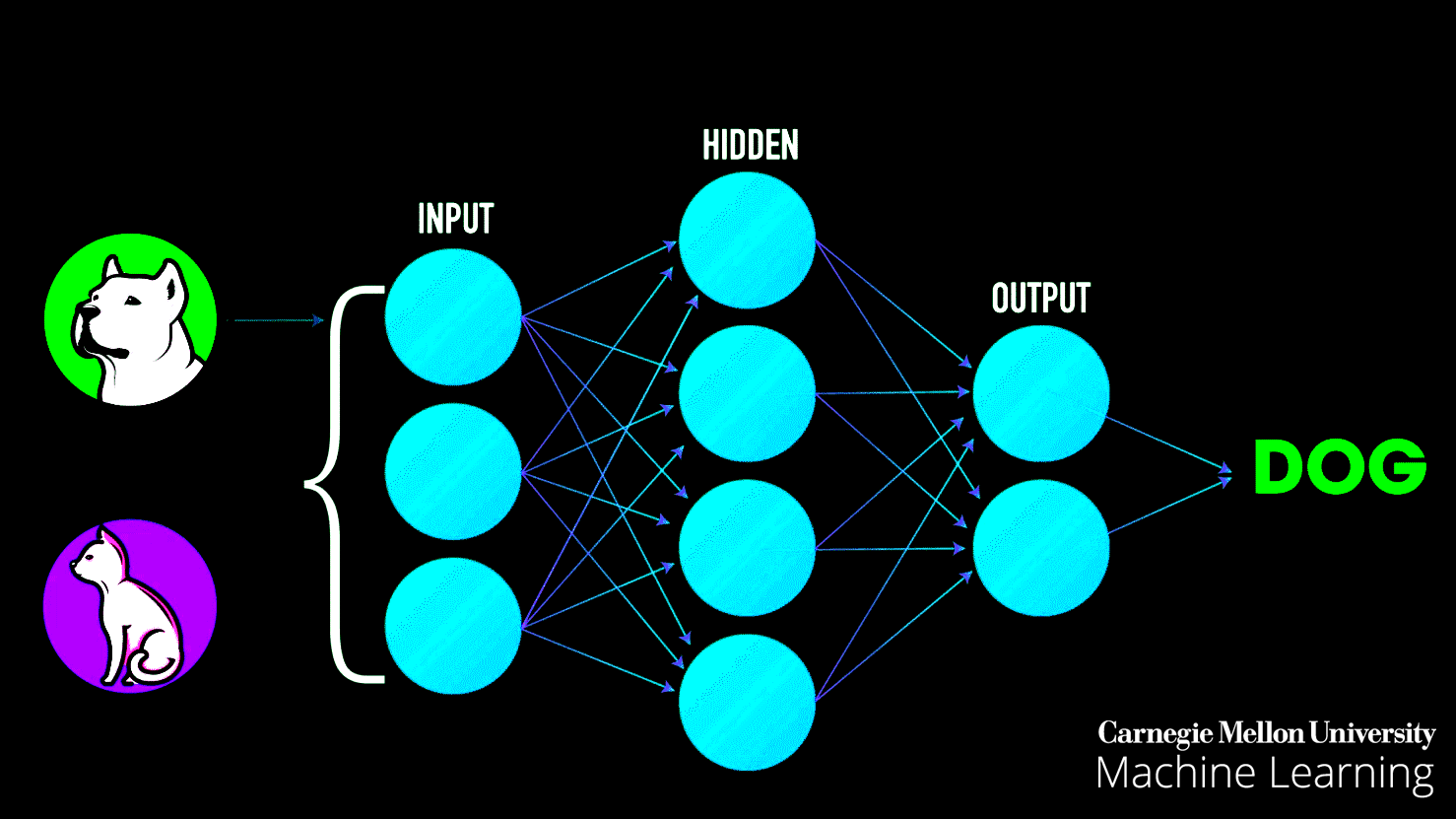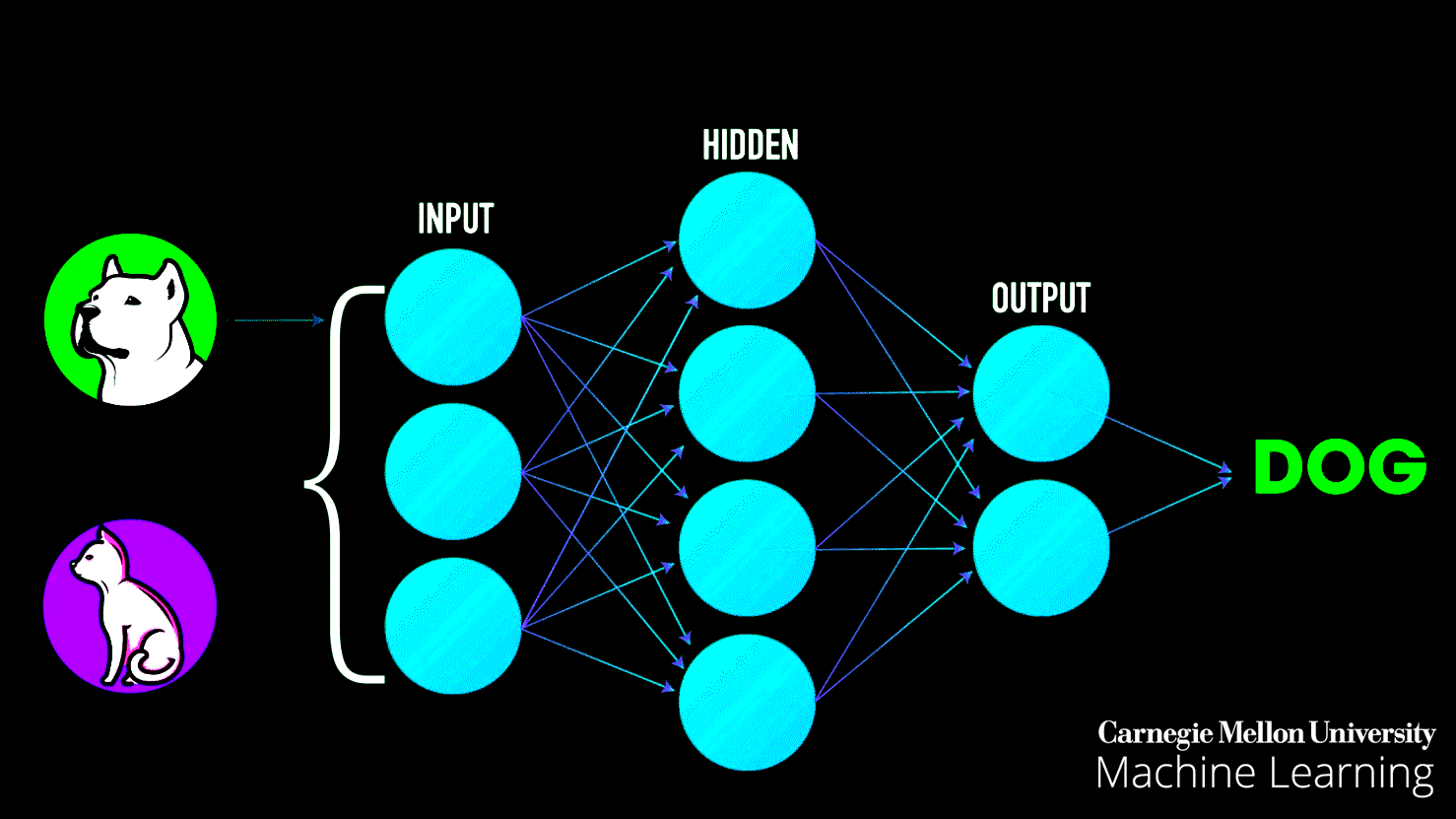
This diagram represents a neural network and how it learns using two key processes:
- Feed Forward (Data Flow):
- Data starts at the Input Layer, where features are provided.
- It moves through the Hidden Layers, where computations and pattern detection occur using weights and biases.
- Finally, it reaches the Output Layer, where predictions or classifications are made.
- Backpropagation (Learning Process):
- After the network makes a prediction, the error (difference between predicted and actual output) is calculated.
- The error is sent backward through the network (backpropagation) to adjust weights and biases, improving future predictions.
This iterative process of forward and backward flow helps the network learn and improve accuracy over time.
Types of Deep Learning Architectures
Different architectures are designed to solve specific types of problems:
1. Convolutional Neural Networks (CNNs)
- Use Case: Image and video analysis.
- How They Work: CNNs use convolutional layers to detect spatial patterns like edges, shapes, and objects.
- Example: Facial recognition systems, medical imaging, and object detection in autonomous vehicles.
2. Recurrent Neural Networks (RNNs)
- Use Case: Sequential data, such as time series, text, or audio.
- How They Work: RNNs retain memory of previous inputs, making them ideal for tasks where context matters.
- Example: Language translation, speech recognition, and stock price prediction.
3. Transformers
- Use Case: Natural Language Processing (NLP).
- How They Work: Transformers use attention mechanisms to focus on relevant parts of the input sequence, enabling efficient processing of long sequences.
- Example: ChatGPT, Google Translate, and text summarization.
4. Generative Adversarial Networks (GANs)
- Use Case: Data generation, such as creating realistic images or synthesizing new music.
- How They Work: GANs consist of two networks: a generator that creates data and a discriminator that evaluates its authenticity. The two networks improve each other through competition.
- Example: Generating deepfake videos and enhancing image resolution.
5. Autoencoders
- Use Case: Data compression and reconstruction.
- How They Work: Autoencoders reduce data into a compressed format and then reconstruct it. They are useful for noise reduction and feature extraction.
- Example: Removing noise from images or videos.
Real-World Applications
Deep learning is transforming industries in profound ways:
1. Healthcare
- Medical Imaging: Detecting tumors or diseases in X-rays and MRIs.
- Drug Discovery: Identifying potential drug candidates faster and more accurately.
- Predictive Analytics: Forecasting patient outcomes based on historical data.
2. Autonomous Vehicles
- CNNs analyze visual data from cameras and sensors to detect pedestrians, traffic signals, and other vehicles, enabling self-driving cars to navigate safely.
3. Natural Language Processing (NLP)
- Virtual assistants like Siri and Alexa use RNNs and transformers to understand and respond to user queries.
- Sentiment analysis tools help businesses gauge customer opinions from text.
4. Entertainment and E-commerce
- Recommendation systems on platforms like Netflix and Amazon analyze user behavior to suggest personalized content.
- Snapchat and Instagram filters use CNNs for face detection and enhancement.
Challenges in Deep Learning
Despite its successes, deep learning faces several challenges:
- Data Dependency: Models require vast amounts of labeled data for training.
- High Computational Costs: Training deep networks demands significant computational resources, making them expensive to deploy.
- Interpretability: Neural networks often operate as "black boxes," making it hard to understand their decision-making process.
- Overfitting: Without proper techniques, models may memorize training data rather than generalizing to new inputs.
The Future:
I recently used SORA.COM. Sora is OpenAI's advanced text-to-video generation model that utilizes deep learning techniques to create videos from textual descriptions. By leveraging transformer-based architectures, Sora can interpret and transform text prompts into dynamic visual content, enabling users to produce realistic or imaginative videos with minimal input. This technology streamlines video creation processes, making it accessible for various applications, including entertainment, education, and marketing. The result not only amazed me but also raised questions about how the world of VFX and video/filmmaking will be transformed. It truly feels like a groundbreaking creation.
Nutshell:
Deep learning is a transformative technology that mimics human cognitive processes to solve complex problems. From healthcare and autonomous vehicles to entertainment and NLP, its applications are vast and growing. While challenges like data dependency and computational costs exist, ongoing research and innovations are paving the way for more efficient, accessible, and powerful solutions.
By understanding the fundamentals of deep learning, you’re not just exploring a cutting-edge field—you’re stepping into the future of technology. Whether you’re a beginner or a tech enthusiast, deep learning offers opportunities to drive meaningful change across industries.
💬 Join the DecodeAI WhatsApp Channel for regular AI updates → Click here