[Day 6] Architectures of Generative AI
Learn how GANs, VAEs, and Transformers power generative AI—from photorealistic images to human-like text—each built for a unique creative task.
![[Day 6] Architectures of Generative AI](https://storage.ghost.io/c/55/e8/55e827ca-bf8d-4eee-bdb4-ee48e49a011a/content/images/size/w2000/2025/03/_--visual-selection--7-.svg)
Generative AI has three primary architectures—GANs, VAEs, and Transformers—because each is optimized for different tasks, capabilities, and trade-offs in generative modeling.
But why you need to know about these architectures, you ask?
GANs, VAEs, and Transformers form the backbone of generative AI, with GANs excelling at creating realistic visuals, VAEs focusing on probabilistic modeling and diverse data generation, and Transformers dominating text generation and multi-modal tasks. Staying familiar with these architectures is essential as they remain central to cutting-edge AI advancements.
Here’s why they exist, their distinctions, and why three architectures are prevalent:
1. GANs (Generative Adversarial Networks)
The key to understanding GANs lies in the word “adversarial.” Imagine it as a boxing match between two neural networks: the Generator and the Discriminator.
- The Generator creates images. At first, its attempts are awful — like randomly splashing paint on a wall.
- The Discriminator acts as a critic. It is trained on real images and decides whether the Generator’s output is real or fake.
Here’s how the process works: If the task is to create a human portrait, the Generator starts by creating blobs of color. The Discriminator immediately rejects this, recognizing it as fake. The Generator learns from this rejection and tries again, making slight improvements, like forming a basic circle for a face. The Discriminator rejects it again, and this feedback loop continues. Over time, the Generator becomes so skilled at creating realistic images that even the Discriminator struggles to tell whether they are real or fake. Eventually, the Generator produces images that are so lifelike that even humans can’t tell they’re fake.

For example, GANs can generate realistic portraits of people who don’t exist, breathtaking landscape photos, or even synthetic medical images for training AI models. The catch is that GANs are limited to what the Discriminator has been trained on. If it has only been trained on human portraits, the Generator can’t create imaginative scenes or objects outside of this scope.
Generative Adversarial Networks (GANs) are one of the most efficient ways to create photorealistic images. Unlike foundation models like diffusion models, which rely on vast amounts of data and self-supervised learning to generate flexible and imaginative content, GANs take a simpler approach. They use a mix of unsupervised and supervised learning, making them easier to set up and requiring far less data. However, GANs are more specialized, ideal for generating realistic images rather than imaginative compositions like dolphins in spacesuits
Use Cases:
- Art: Creating digital artwork or hyper-realistic images.
- Gaming: Generating lifelike 3D textures or environments.
- Healthcare: Producing synthetic medical images for AI training.
- Media: Generating deepfake videos or enhancing image quality.
- Distinct Features:
- Focuses on high-quality realism.
- No explicit density estimation; it doesn’t model probabilities directly.
- Training is challenging due to instability and mode collapse.
2. VAEs (Variational Autoencoders)
Variational Autoencoders (VAEs) are powerful tools for improving and generating data by learning its underlying patterns. VAEs excel in more focused tasks, such as enhancing image clarity or reconstructing missing parts of data, without needing extensive computing power or massive datasets.
VAEs are a type of autoencoder that compresses data into a simpler format through an encoder and then reconstructs it using a decoder.
Encoder
The Encoder is the first step in a Variational Autoencoder (VAE). It compresses the input data into a simplified, abstract representation called the latent space. The encoder identifies the key patterns or essence of the data while discarding unnecessary details. For example, if trained on landscape images, the encoder captures the shapes, colors, and textures that define a landscape. This compact representation is what allows the system to later reconstruct or modify the input.
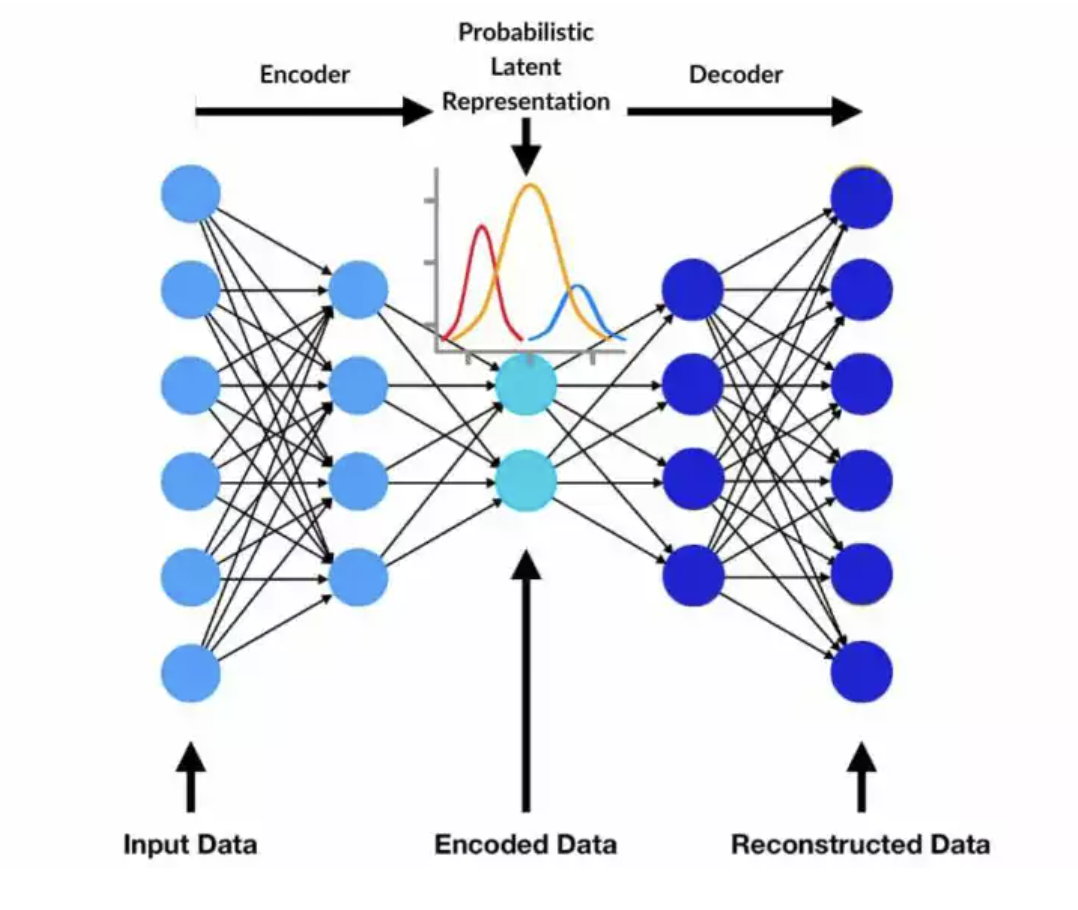
Decoder
The Decoder is the counterpart to the encoder. It takes the abstract representation from the latent space and reconstructs it back into a detailed output. This process involves filling in gaps or refining the data based on the patterns the system has learned. For instance, if the encoder has distilled the features of a mountain, the decoder uses this information to recreate the original image or generate a new variation of a mountain. The decoder ensures the final output aligns closely with the data’s learned essence.
For example, if a VAE is trained on images of cars, the encoder distills the key characteristics of a car into a latent space — a simplified, abstract representation. When given a blurry or incomplete image of a car, the decoder can reconstruct it into a sharper, more complete version based on this learned representation.

This ability to isolate the essence of an image also makes VAEs excellent for removing noise or filling in gaps. For instance, if you have a faded historical map, a VAE can restore it by identifying and enhancing key lines and patterns. Similarly, given an incomplete diagram of a mechanical part, a VAE can generate the missing sections to create a complete and accurate version.
VAEs are especially useful in:
- Restoration: Reconstructing and improving clarity in scanned documents or degraded artworks.
- Design: Generating variations of architectural layouts or industrial designs.
- Pattern completion: Filling in missing sections of scientific data, such as weather maps or molecular structures.
However, VAEs do have their limitations. They are only as good as their training data — if trained on a specific set of architectural blueprints, they cannot generate something entirely outside that scope. Unlike foundation models, VAEs are not suitable for highly imaginative tasks, such as creating an entirely new type of structure or combining unrelated concepts like a skyscraper made of vines 😄
Despite these constraints, VAEs are indispensable for tasks requiring precision and refinement. Whether restoring an old diagram, completing a damaged scientific chart, or generating variations of industrial designs, VAEs provide a reliable and efficient solution by focusing on capturing and reconstructing the essence of the data.
3. Transformers: The Backbone of Modern AI
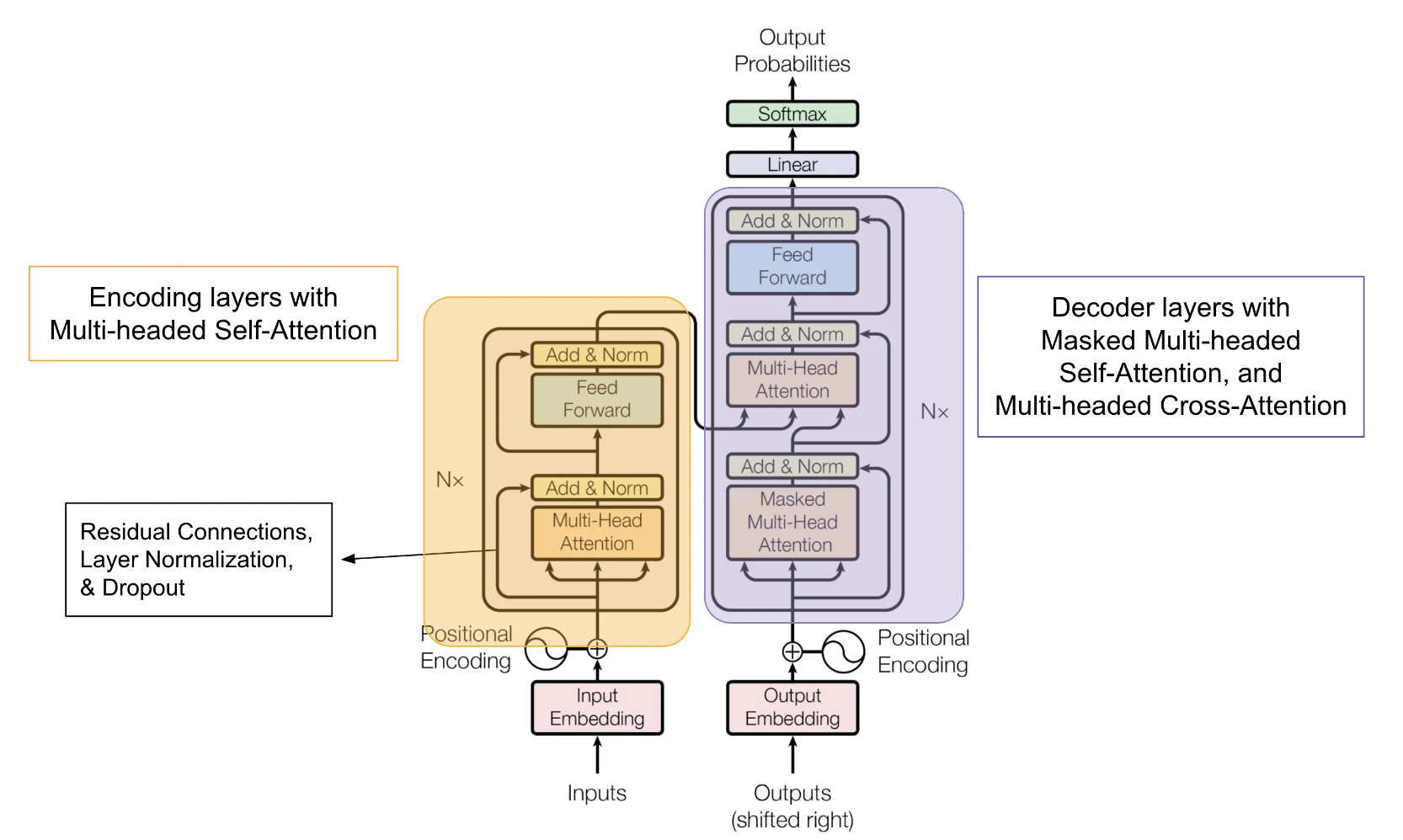
Transformers are revolutionary tools in the world of artificial intelligence, particularly for tasks involving sequences like language, images, and even music. Unlike older models that process data step by step, Transformers excel by analyzing the entire input sequence simultaneously, making them faster, more efficient, and better at understanding context.
At the core of the Transformer architecture are two key components: the encoder and the decoder. Together, they work to process and generate data, leveraging a mechanism called attention to focus on the most important parts of the input.
How Transformers Work
Transformers are designed to handle sequential data holistically. For instance, when reading a sentence, a Transformer doesn’t process one word at a time. Instead, it looks at all the words together, understanding how they relate to each other. This is done using self-attention, which allows the model to weigh the importance of different words based on their context.
For example, in the sentence “The cat sat on the mat,” the word “cat” is closely related to “sat” and “mat.” The self-attention mechanism identifies and prioritizes these relationships, enabling the Transformer to understand the meaning of the entire sentence.
Encoder and Decoder
- Encoder: The encoder processes the input data (like a sentence) and converts it into a context-rich representation. It does this using layers of self-attention and feedforward neural networks. This representation is a distilled version of the input, retaining its meaning and context.
- Decoder: The decoder takes the encoder’s representation and generates the output sequence (like a translation or summary). It uses the context from the encoder and combines it with previously generated output to ensure the result is coherent and logically sequenced.
Use Cases of Transformers
Transformers are incredibly versatile and power many of today’s advanced AI applications:
- Language Translation: Tools like Google Translate use Transformers to convert text between languages with high accuracy.
- Text Summarization: Summarizing long articles or reports into concise summaries is made efficient with Transformers.
- Text Generation: Chatbots like ChatGPT leverage Transformers to generate human-like conversations, essays, or code.
- Image Generation: Models like DALL-E use Transformers to create images from textual descriptions.
- Speech Recognition: Converting spoken language into text is another area where Transformers excel.
Fun Fact: ChatGPT is a Transformer, it stands for Generative Pre-trained Transformer
Use case: Consider a French-to-English translation task. The encoder processes the French sentence, understanding its structure and meaning. The decoder then uses this information to generate the English equivalent word by word, ensuring the grammar and semantics are accurate.
Why Three Architectures?
- Different Generative Needs: Each architecture solves unique problems:
- GANs for realism.
- VAEs for diversity and probabilistic modeling.
- Transformers for sequence generation and multi-modality.
- Task Specialization: Tasks like image generation (GANs/VAEs) and text generation (Transformers) require different approaches.
- Technological Evolution:
- GANs and VAEs emerged first for generative modeling of structured data.
- Transformers built upon these advancements, combining scalability and adaptability to expand beyond single-modality tasks.
In summary, these three architectures coexist because they cater to distinct types of generative tasks with varying priorities: realism (GANs), diversity and latent structure (VAEs), and multi-modal, sequential generation (Transformers). This diversity ensures that generative AI can address a broad range of applications effectively.
💬 Join the DecodeAI WhatsApp Channel for regular AI updates → Click here