[Day 7] Understanding of Large Language Models
Ever wondered how AI like ChatGPT seems to “understand” you? Meet Large Language Models—the brain behind the magic, trained on billions of words to write, chat, translate, and think like us.
![[Day 7] Understanding of Large Language Models](https://storage.ghost.io/c/55/e8/55e827ca-bf8d-4eee-bdb4-ee48e49a011a/content/images/size/w2000/2025/03/_--visual-selection--8-.svg)
Before jumping into the Large Language Models (LLMs), let's start with the basics.
What are Language Models?
A language model is an artificial intelligence (AI) system designed to understand, generate, and work with human language. It's like a super-smart assistant that can predict what comes next in a sentence, respond to questions, translate languages, or even write stories—all by learning patterns in text data.
How Does a Language Model Work?
- Learning Patterns:
- A language model reads and learns from a huge amount of text (books, articles, websites, etc.).
- It analyzes how words and sentences are structured to understand context, grammar, and meaning.
- Prediction:
- The main goal is to predict the next word in a sentence. For example:
- Input: "The cat is on the"
- Output: "mat."
- The main goal is to predict the next word in a sentence. For example:
- Training:
- The model is trained using machine learning on massive datasets. It adjusts internal "parameters" (like settings) to improve its predictions and responses.
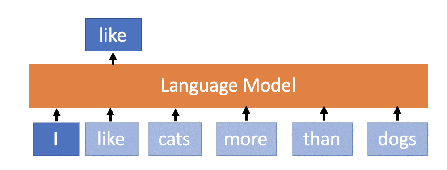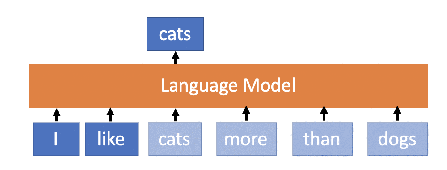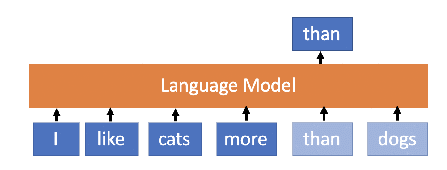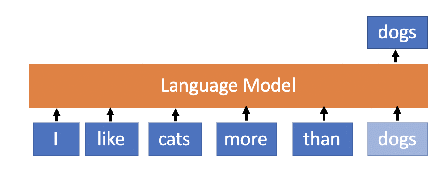
Examples of Language Models (Basic text models)
- BERT: For understanding sentence meaning and context.
- RoBERTa: Enhanced version of BERT.
- ELMo: Contextual word embeddings.
- GPT-2: Early generative language model.
Large Language Models
a) About LLMs
A Large Language Model (LLM) is an advanced AI system designed to process, understand, and generate human language, distinguished by its massive scale in terms of parameters (billions or more) and training data.
The term "Large" emphasizes two meanings:
1. The model was trained on an extensive amount of data, often measured in petabytes, enabling it to generalize well and perform a wide range of tasks effectively.
- It refers to 'Parameter count'. It's about a high parameter count, which determines the model's capacity and skill level. Parameters are adjustable values in a model that define how it processes input data, directly influencing its ability to learn and perform tasks effectively.
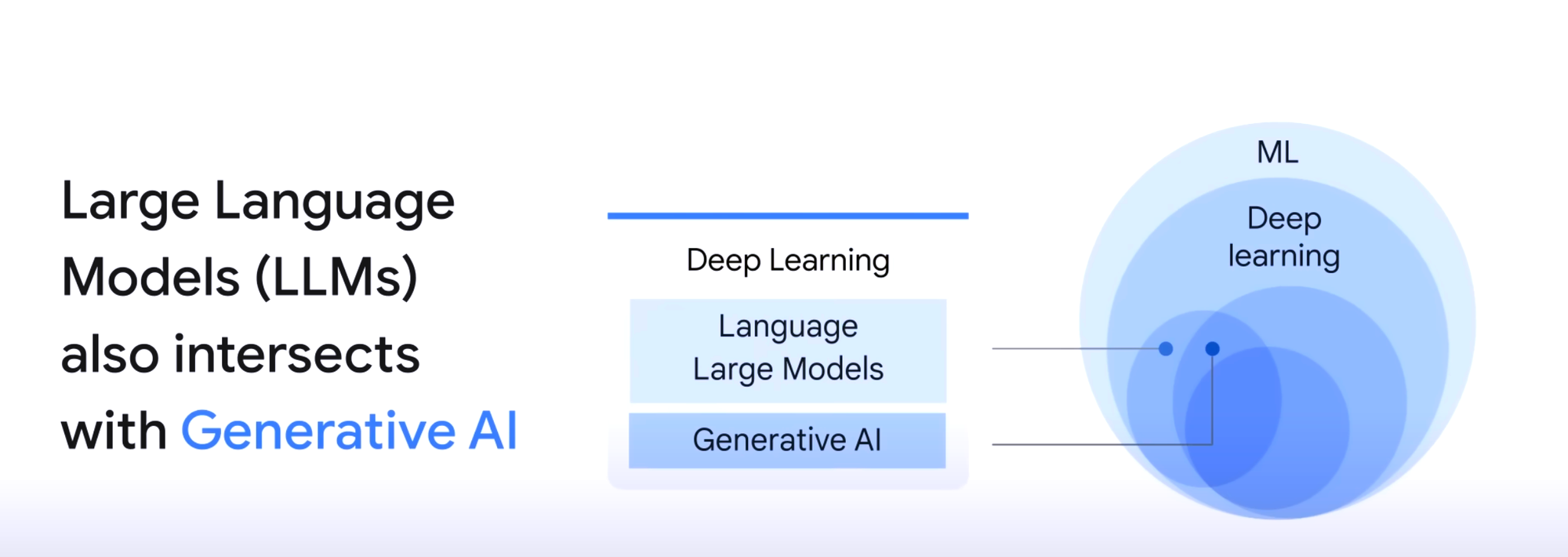
LLMs and Generative AI intersect, and both are part of the field of deep learning.
LLMs are initially trained on vast datasets to solve general language tasks such as text classification, question answering, document summarization, and text generation. This training helps the model understand language patterns, relationships, and context across a broad range of topics.
Once trained, these general-purpose models can be adapted to specific needs through a process called fine-tuning. Fine-tuning involves training the model further on domain-specific or task-specific data, refining its capabilities to perform better in specialized areas.
If you have a dog and you train it to sit, eat, run, and follow general commands, this is called "Training." However, if you want the dog to perform specialized tasks, like being a police dog, a guide dog, or a hunting dog, you need to provide additional, specific training tailored to those roles. This specialized training is what we call "Fine-Tuning. LLMs work the same way.
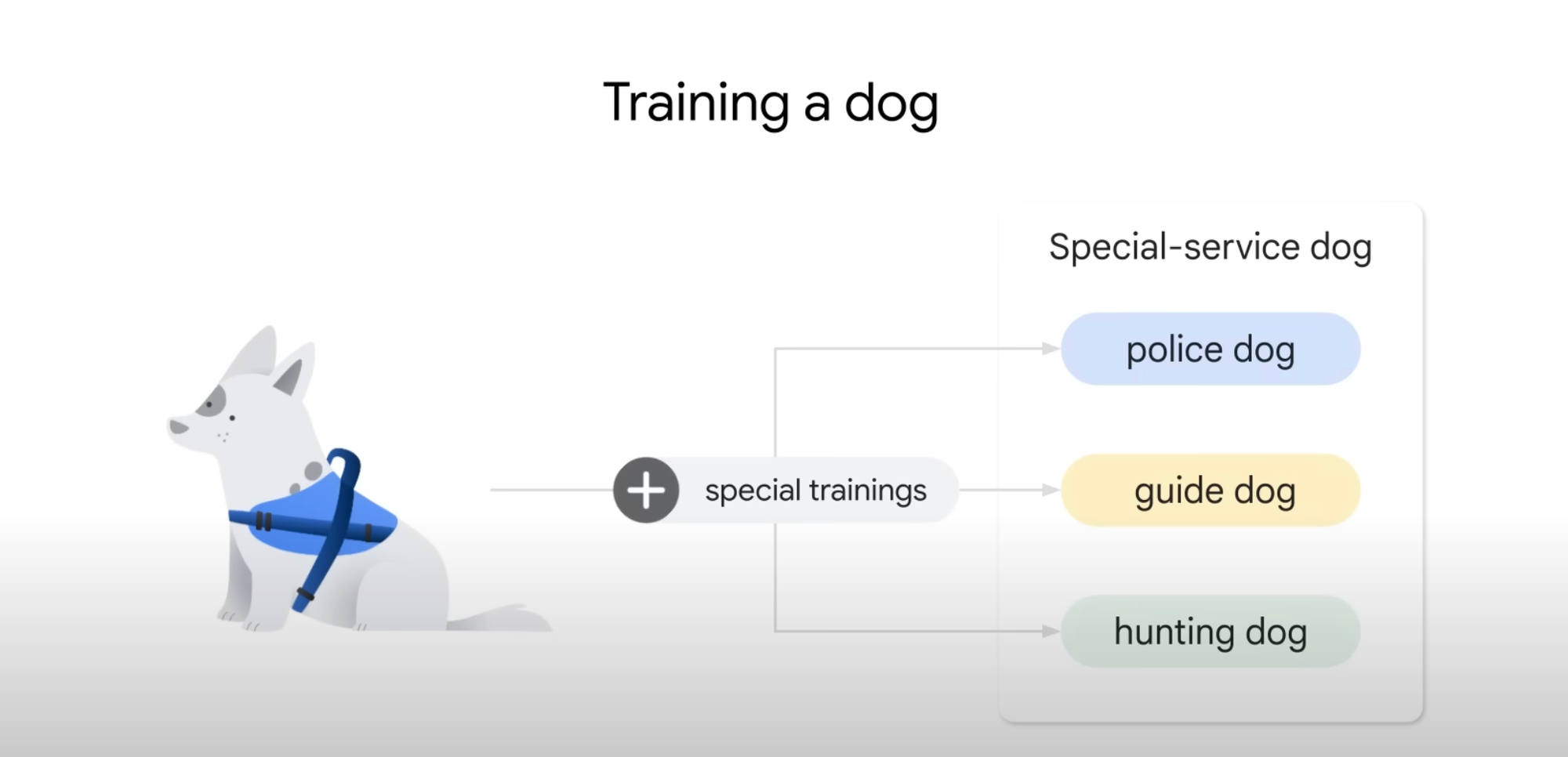
For example:
- A general LLM can be fine-tuned with medical texts to become proficient in diagnosing symptoms or explaining complex medical terms.
- Similarly, fine-tuning with legal documents can enable the model to assist with legal research or drafting contracts.
You can use GPT-4 as a base model and fine-tune it to answer specific queries from your customers. By integrating OpenAI's APIs and leveraging your company's datasets (e.g., product FAQs, customer service logs, or knowledge base), the fine-tuned model can provide precise and context-aware responses tailored to your business.
- A retail company can fine-tune GPT-4 to assist customers with product recommendations, order tracking, and return policies based on historical customer interactions.
- A financial institution can fine-tune GPT-4 to answer client-specific questions about investment options, credit limits, or loan eligibility.
Fine-tuning allows the LLM to leverage its foundational language understanding while focusing on the unique requirements of a particular field or task.
Here is the list of the top 5 LLMs:
- GPT-4 (OpenAI) - Not free; paid access via OpenAI API or ChatGPT Plus.
- LLaMA 2 (Meta) - Free for research and commercial use (under specific licensing terms).
- Claude (Anthropic) - Limited free access with usage caps; full access requires payment.
- PaLM 2 (Google) - Not free; accessible via Google Cloud's Vertex AI platform.
- Bloom (BigScience) - Free and open-source for research and commercial use.
GPT-4, Claude, and PaLM 2 are 'Pre-trained' plug-and-play models accessible via APIs. You can use their pre-trained capabilities directly and adapt them for specific tasks through prompt engineering or fine-tuning with your data. They require minimal setup, as the providers handle infrastructure, making integration seamless for businesses.
What does training a model look like? See the below picture. The 140 GB file on the right-hand side represents the LLaMa LLM with 270 billion parameters. It was trained on 10 TB of internet data using 6,000 GPUs over 12 days, costing approximately $2 million.

b) Performance of LLMs
The performance of language models improves with more data and more parameters, as both enable the model to capture complex patterns and generalize effectively.
- More Training Data:
- Adding more diverse and high-quality training data helps the model learn better patterns, relationships, and nuances in language.
- This leads to improved generalization, allowing the model to perform better on unseen tasks or datasets.
- Example: Training on additional domain-specific data can enhance a model's performance in that domain.
- More Parameters: Increasing parameters (e.g., billions or trillions of weights in the model) allows the model to capture more complex patterns and relationships in the data.
For the best results, a balance between model size (parameters) and the amount of high-quality training data is essential. Adding more parameters without sufficient data leads to Overfitting (we will discuss about this later), while more data with insufficient parameters can result in underutilization. Both factors must scale together for optimal performance.
What makes a LLM great?
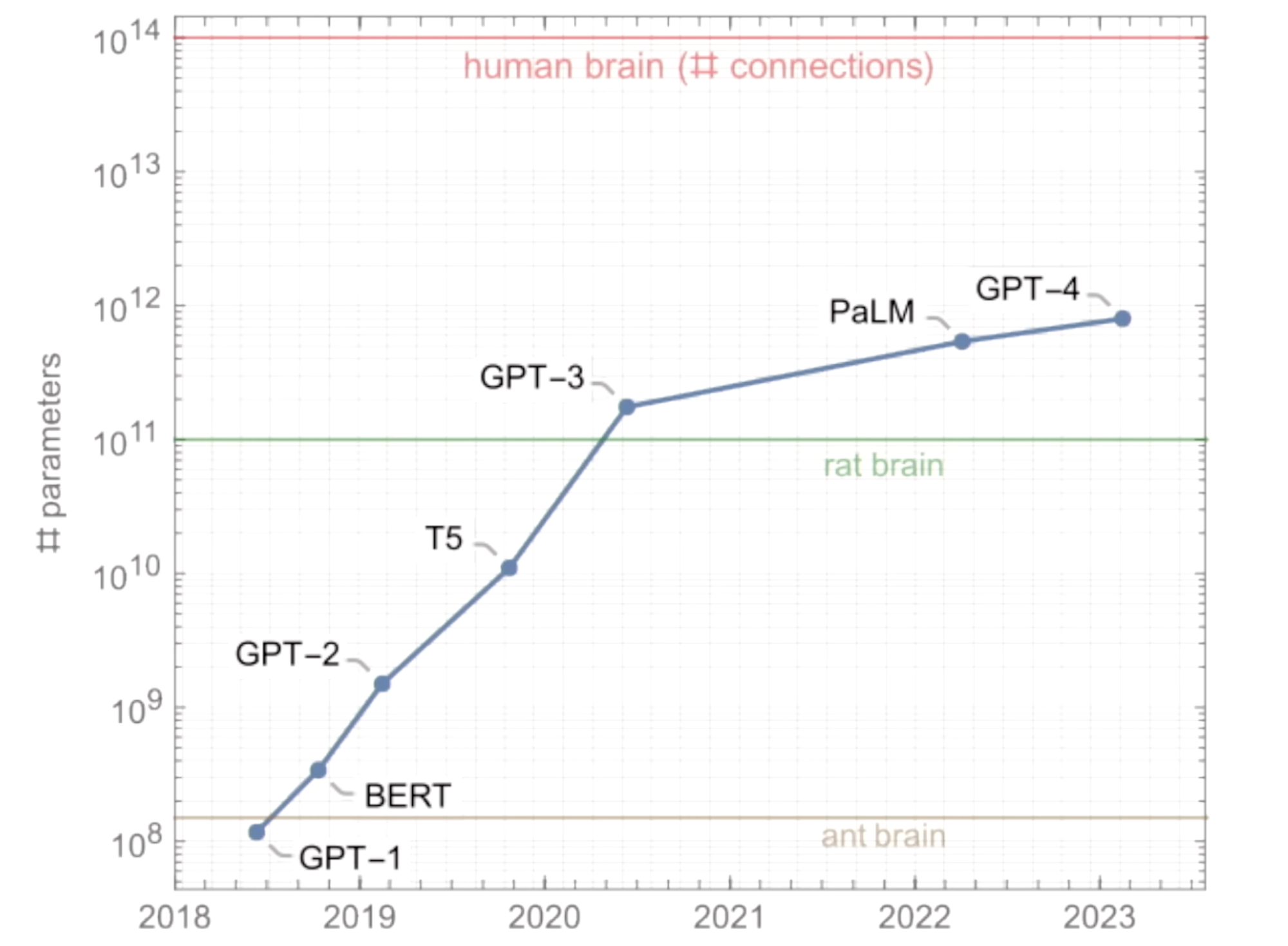
When GPT1 (2018) or GPT2 (2019) came, they were not amazing and but GPT3 was big success and it was amazing too. Why? Because it was bigger in size (here size means it mighted be trained on more data and have more pameters. See the gap:
- GPT-1: 117 million parameters
- GPT-2: 1.5 billion parameters
- GPT-3: 175 billion parameters
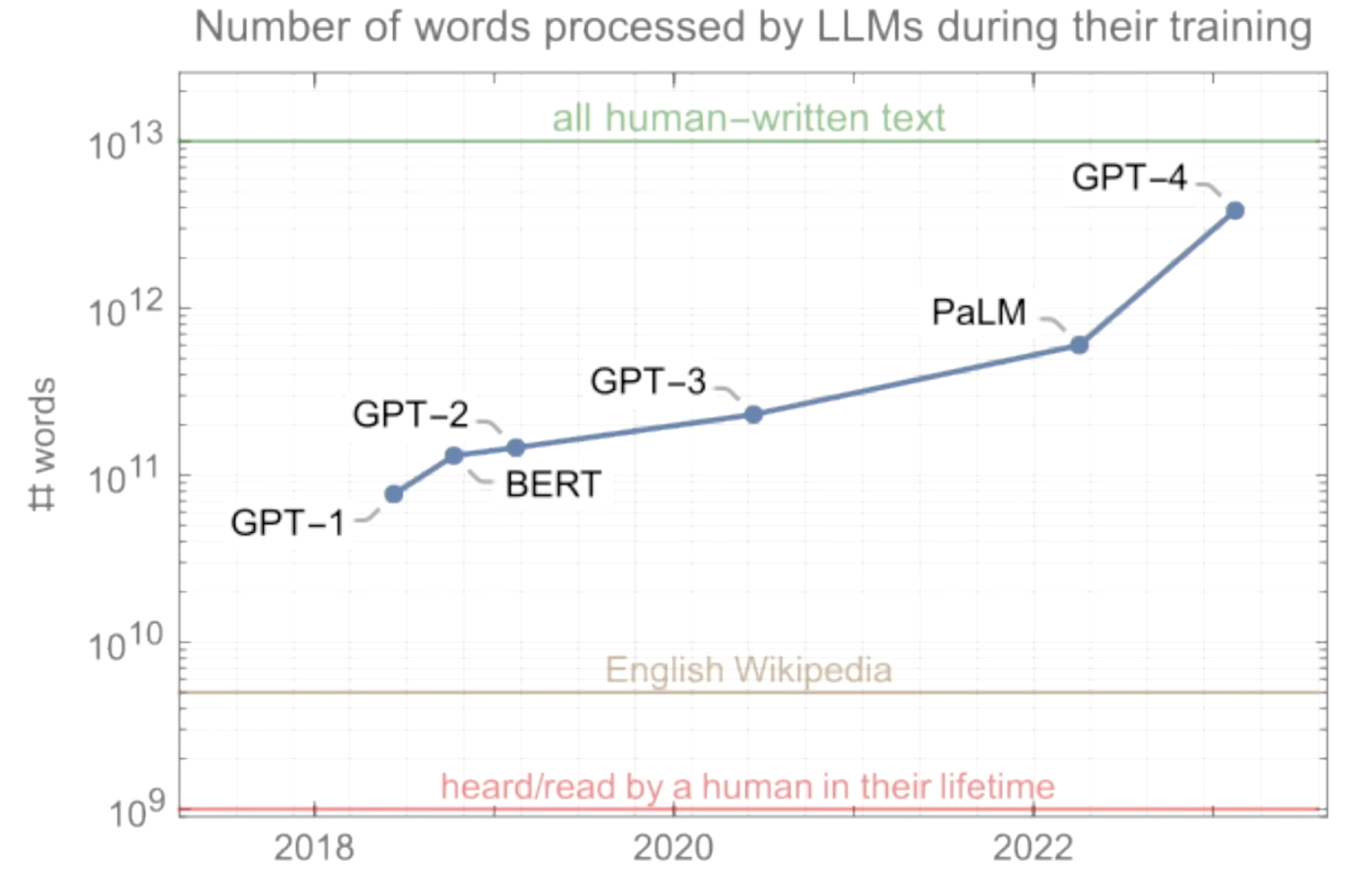
The below graph depicts the number of words processed by various Large Language Models (LLMs) during their training over time. It shows how the amount of data (measured in words) used to train models like GPT-1, GPT-2, GPT-3, PaLM, and GPT-4 has grown significantly. Key milestones include:
- GPT-1 to GPT-4: A sharp increase in the scale of training data.
- Benchmarks: Comparisons are made with "all human-written text," "English Wikipedia," and "words heard/read by a human in their lifetime."
- Trend: Reflects the exponential growth in computational capacity and data usage for advancing AI.
Till now you must have understood that for a better model, a balance between model size (parameters) and the amount of high-quality training data is essential.
But, what are Parameters, and how to Visualize it?
In Large Language Models (LLMs), parameters are like tiny switches or knobs that the model uses to learn patterns and make decisions. These parameters are adjusted during training to help the model understand relationships between words, sentences, and ideas.
The concept of parameters in LLMs can be loosely related to the way the Turing machine works in "The Imitation Game" movie, as both involve the idea of solving complex problems by tuning components systematically.

In the Movie:
- The Turing machine (Christopher) was designed to crack the German Enigma code. It worked by testing millions of possible combinations to find the correct encryption settings for messages.
- The machine had mechanical dials (its "parameters") that could be adjusted to try different combinations.
- By systematically tuning these dials and using logic (like recognizing common words in intercepted messages), the machine eventually cracked the code.
In LLMs:
- Parameters are like the dials on Turing's machine. Instead of breaking codes, they are adjusted during training to recognize patterns in text (e.g., grammar, meaning, relationships). Parameters in LLMs are adjusted using backpropagation during training.
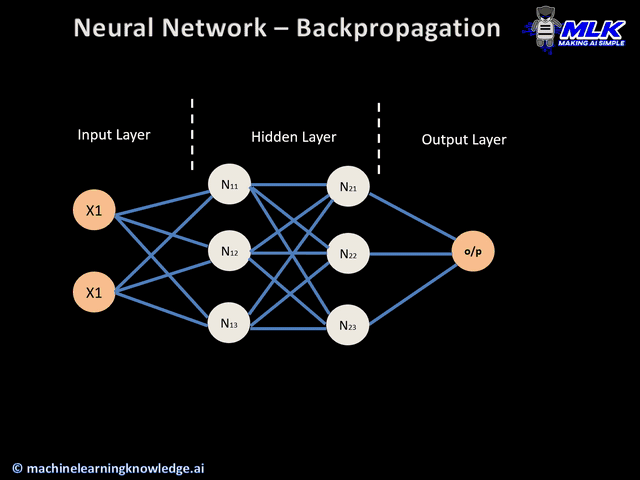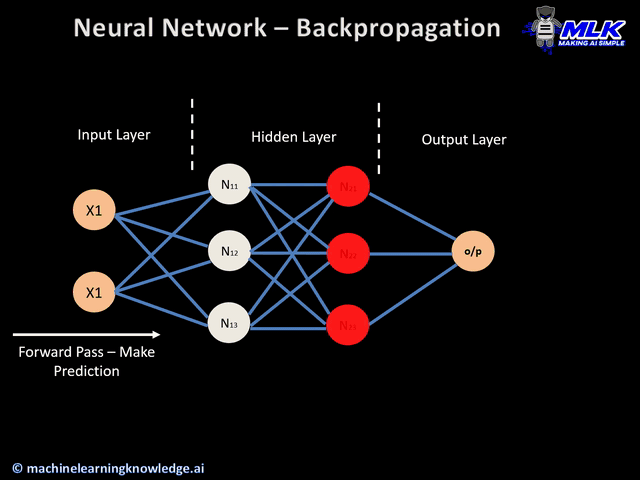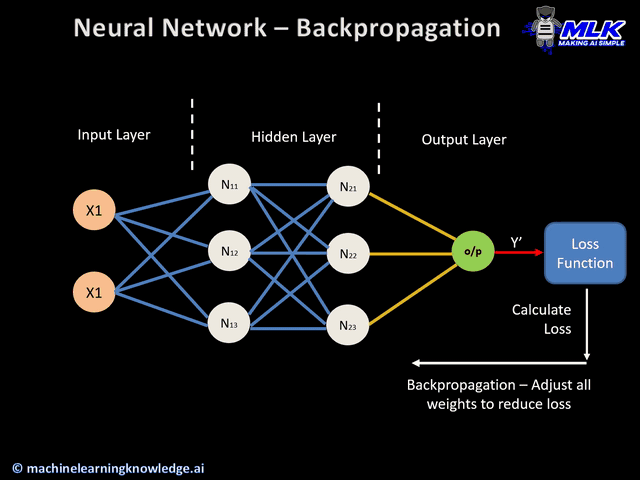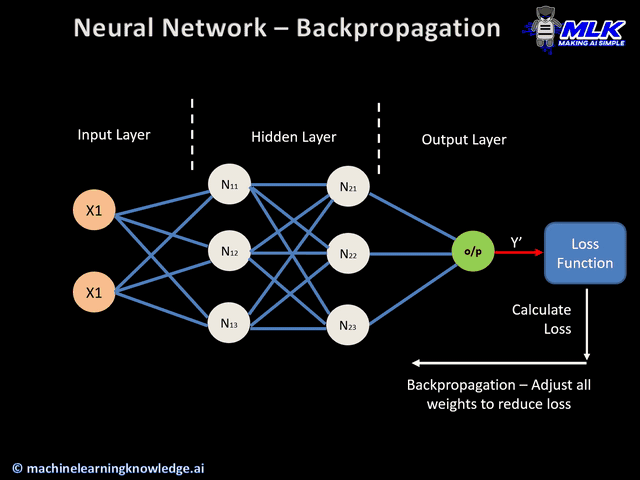
LLMs improve by increasing the number of parameters, allowing them to fine-tune their understanding of data more effectively.
Turing machine used mechanical "parameters" to solve one specific problem (breaking codes), while LLMs use billions of mathematical parameters to understand and generate human-like text across many domains. Both are brilliant demonstrations of scaling problem-solving through systematic tuning!
Fun Fact: Turing-NLG is also a language model by Microsoft, launched in February 2020, with 17 billion parameters. It was among the largest models at the time, designed for text generation and understanding tasks.
Lets talk about types of LLMs in the next session.
For a better understanding of LLMs please refer below vidoes:
- Large Language Models explained briefly
2. Introduction to large language models
- favorite
The last one is my favorite 😊
💬 Join the DecodeAI WhatsApp Channel for regular AI updates → Click here