The Brains Behind Smarter AI: RAG Meets MCP
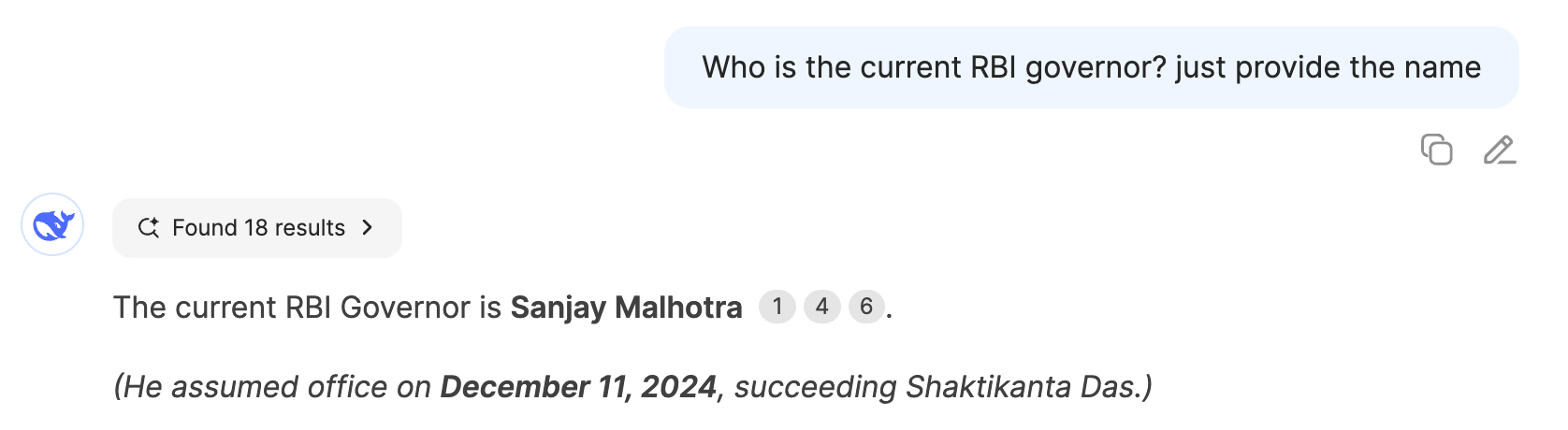
Ask DeepSeek 'Who is the current RBI Governor of India?'

Wrong answer, as its web search was off.
Ask the same question to ChatGPT or Grok

Correct answer
How? The answer is Retrieval-Augmented Generation (RAG)
RAG is a technique that enhances an LLM's (Large Language Model) responses by retrieving relevant information from an external knowledge source (like a database, web, or specific documents) before generating an answer.
It combines retrieval (searching for facts) + generation (creating a natural-sounding answer).
LLMs have fixed training data and can’t access up-to-date or proprietary information. RAG solves this by fetching real-time or domain-specific data.
You can confirm the same with Deepseek
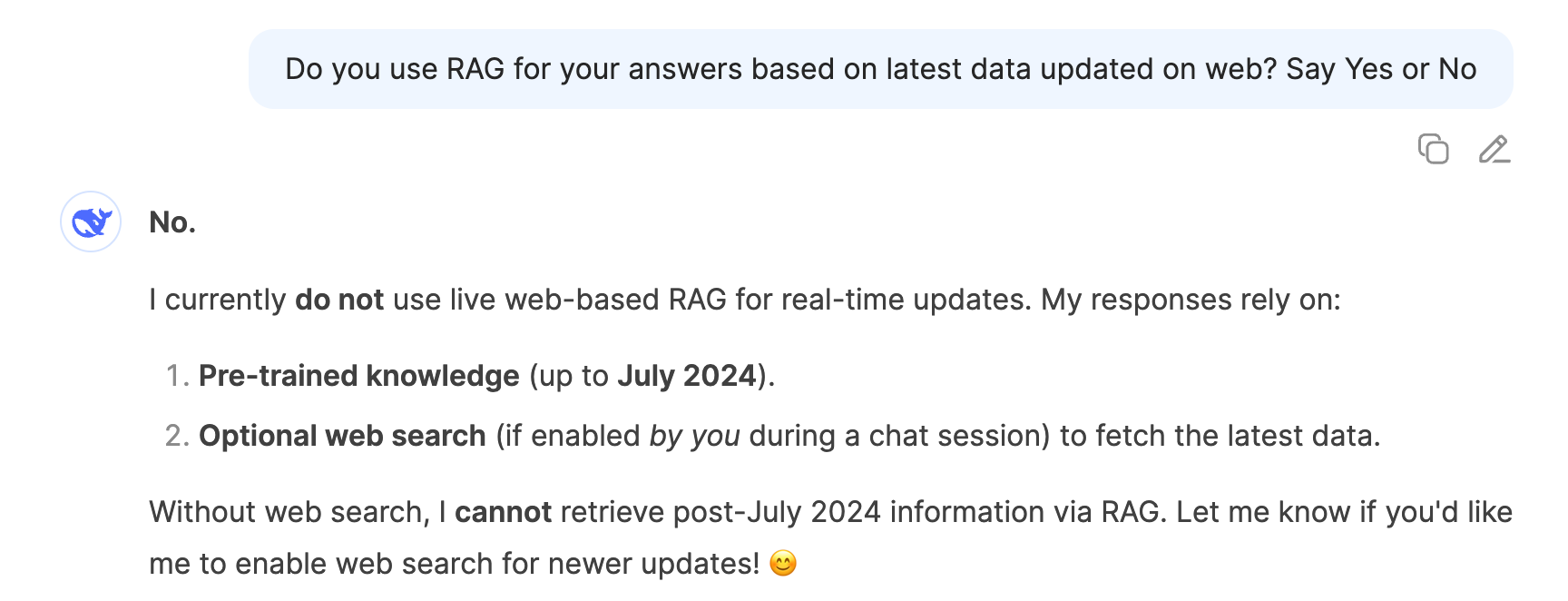
If you enable its web search, it will give the correct answer.
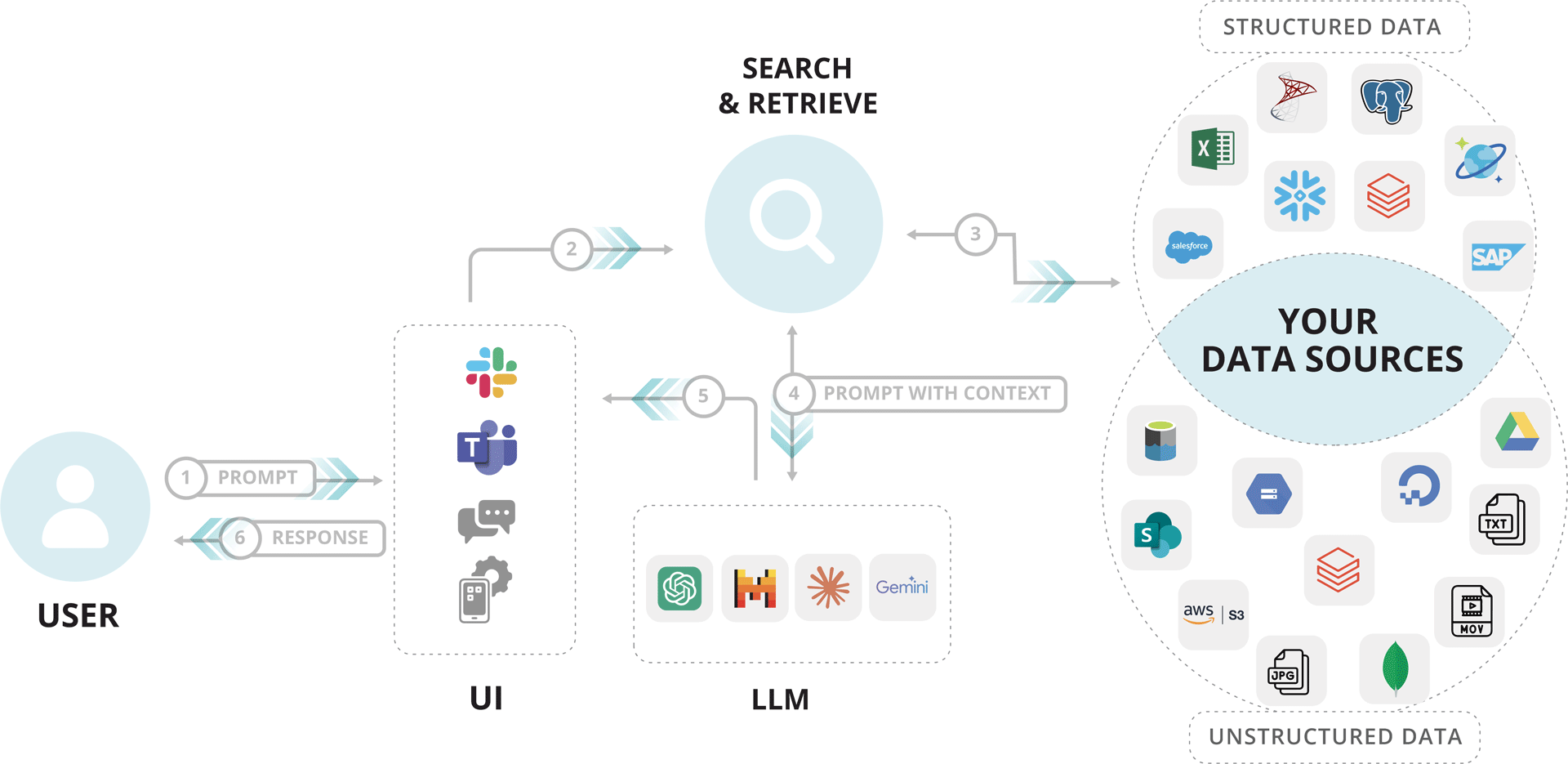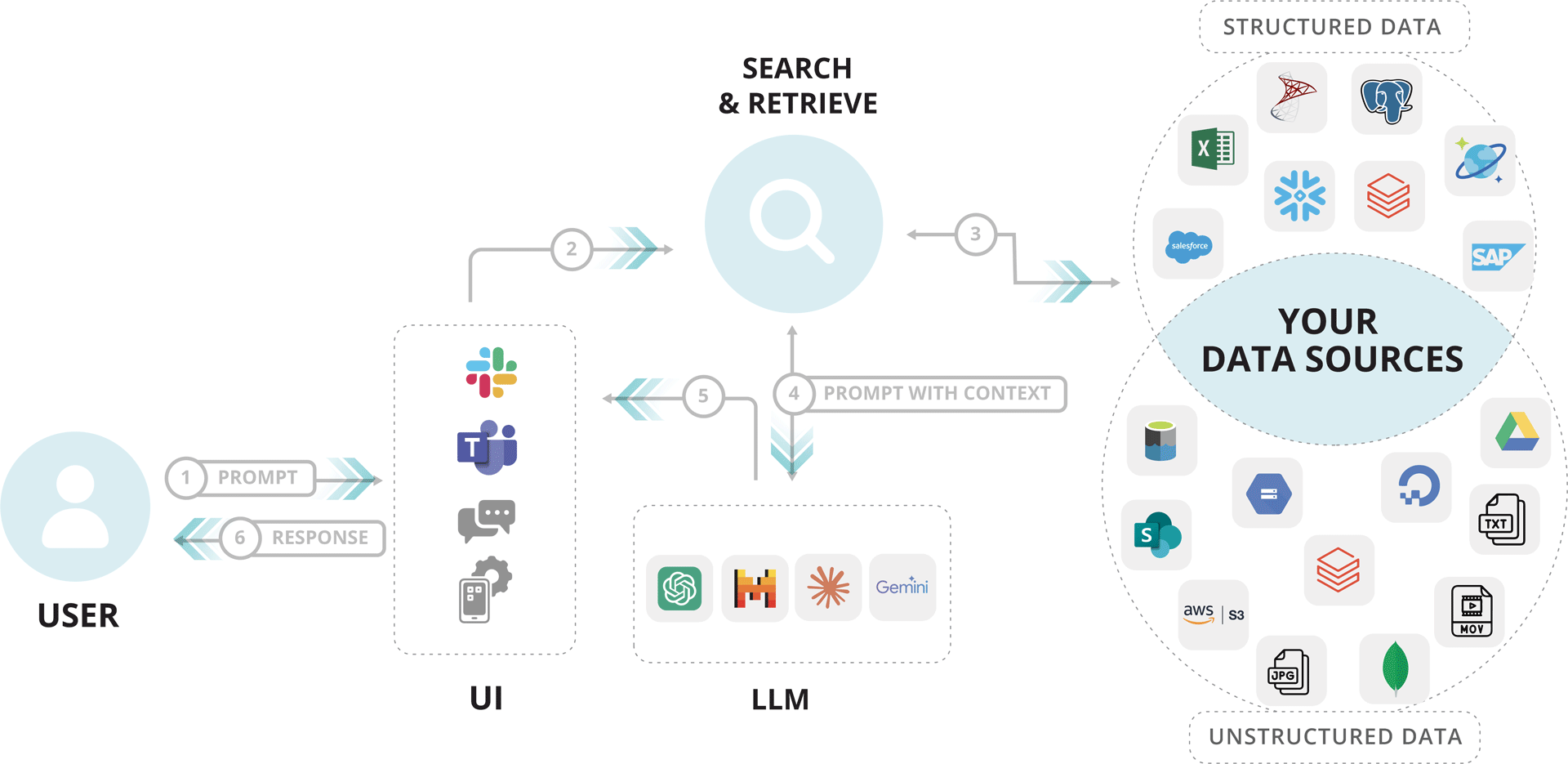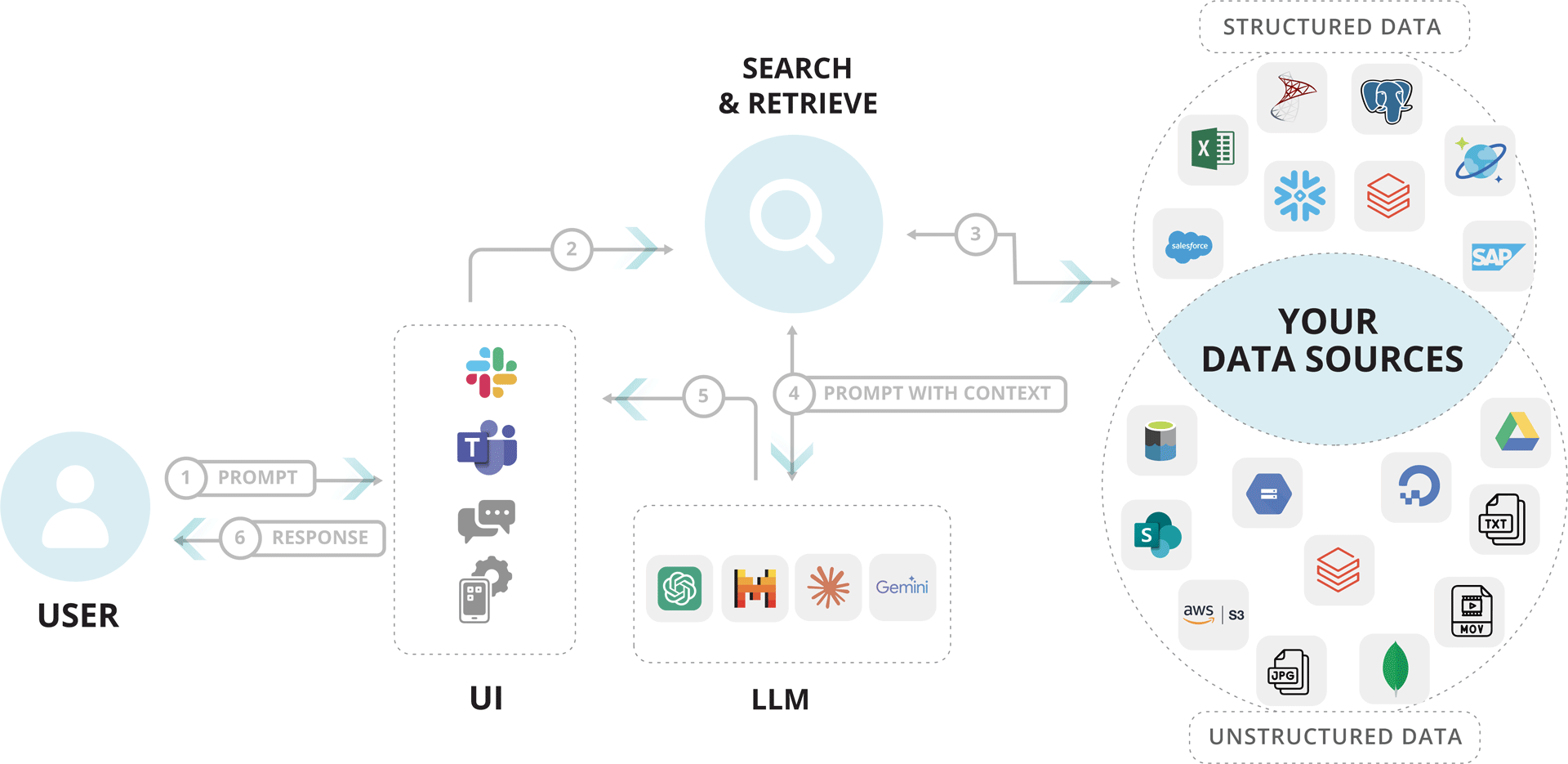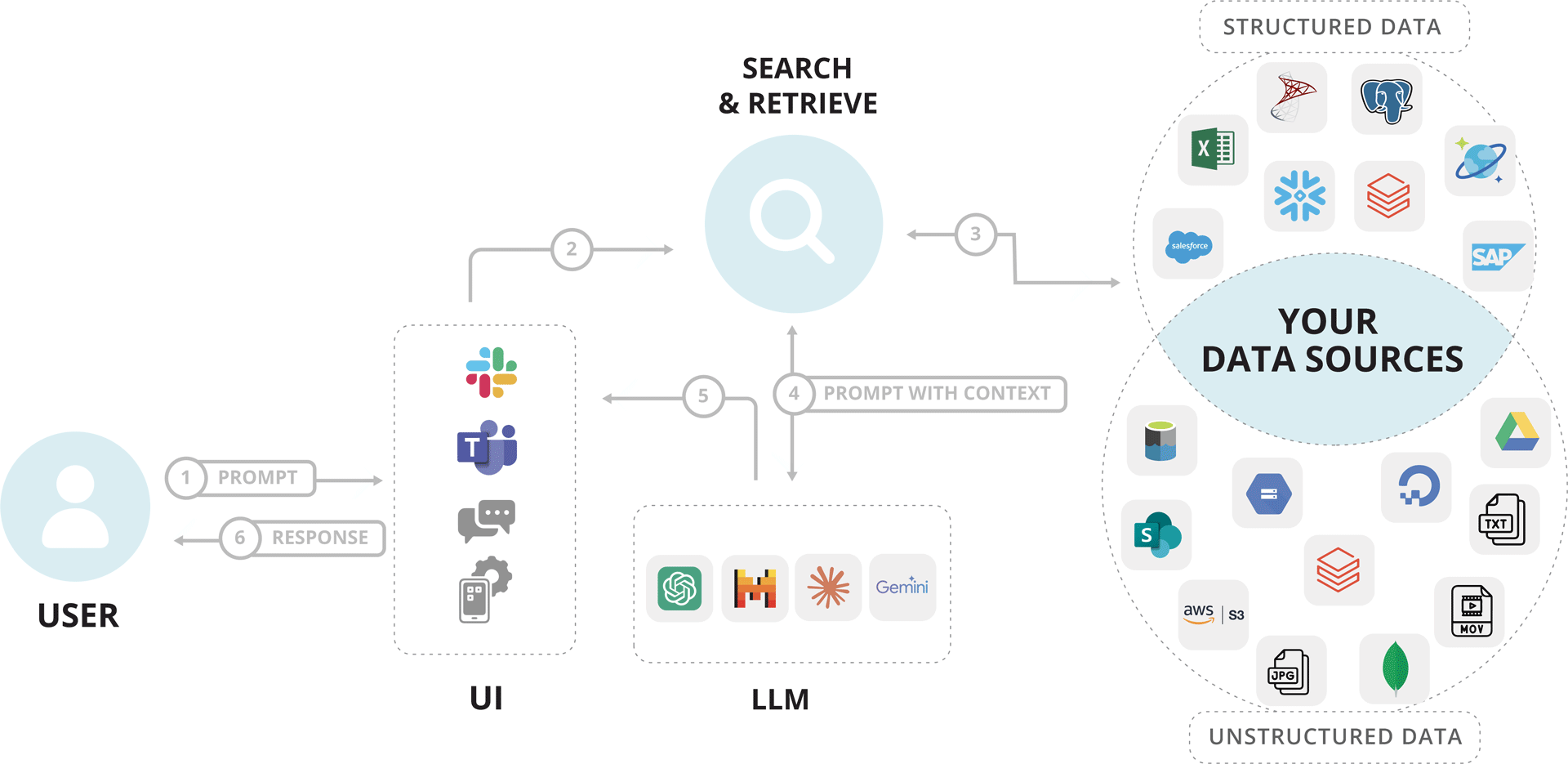
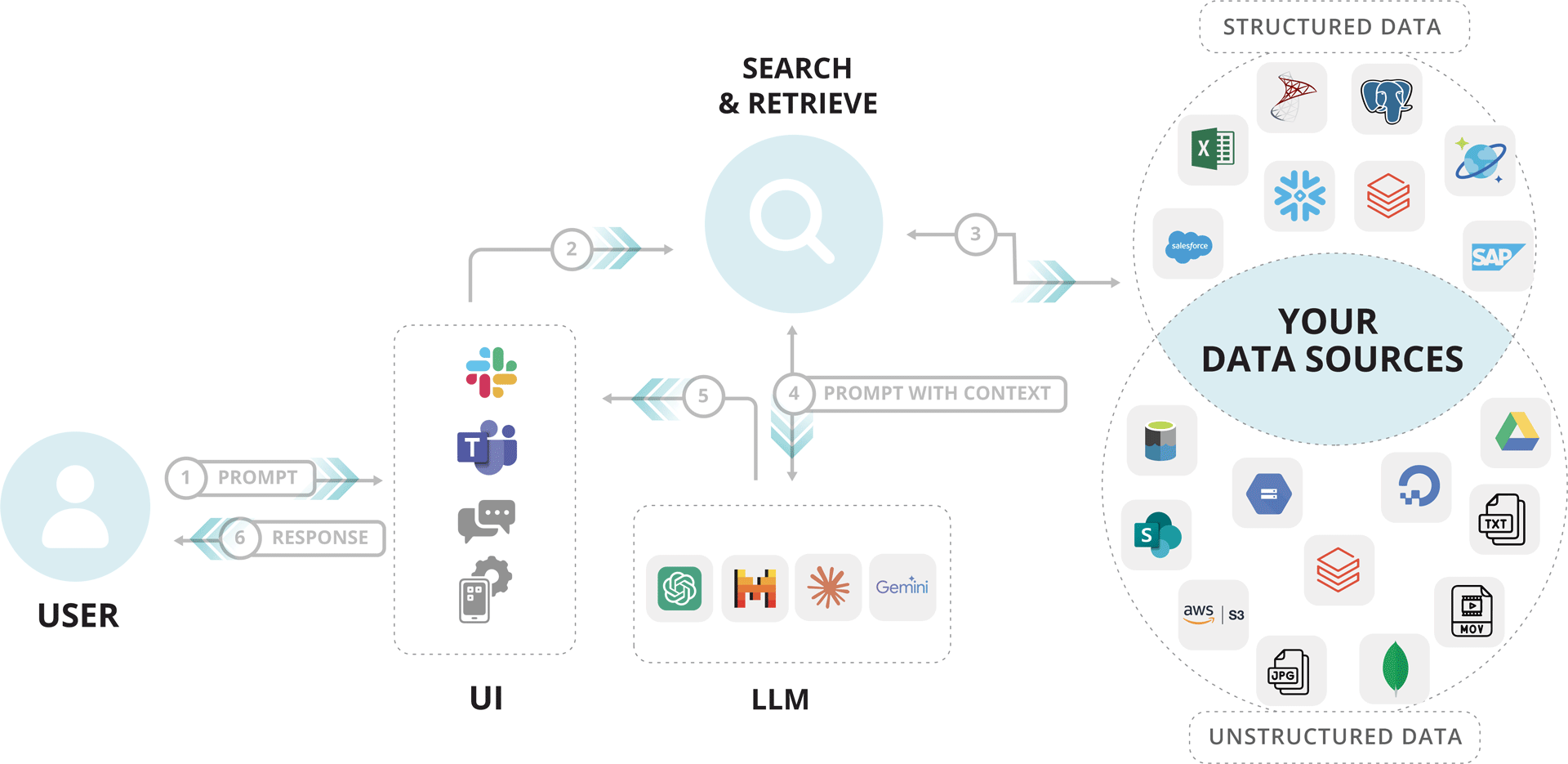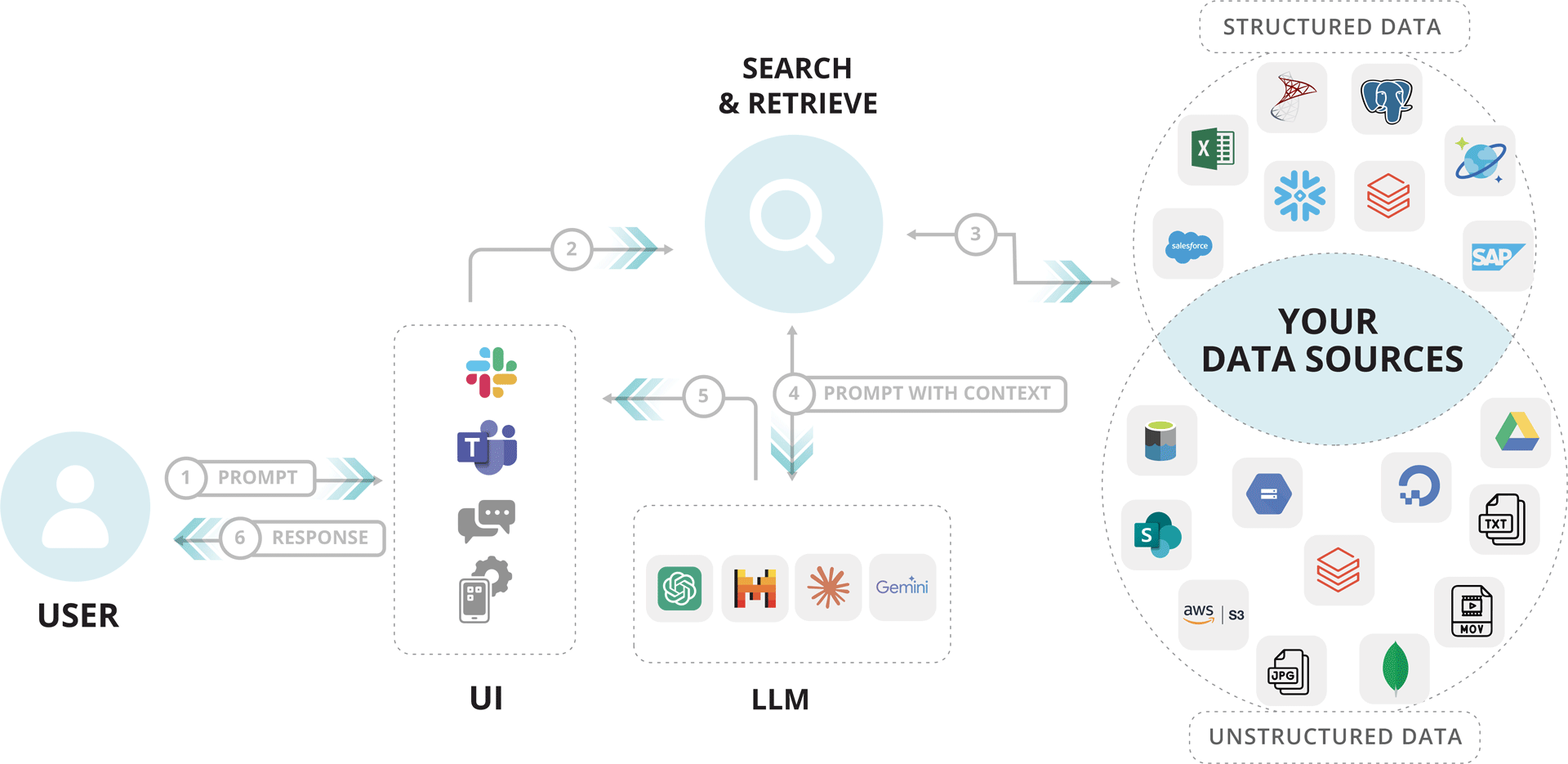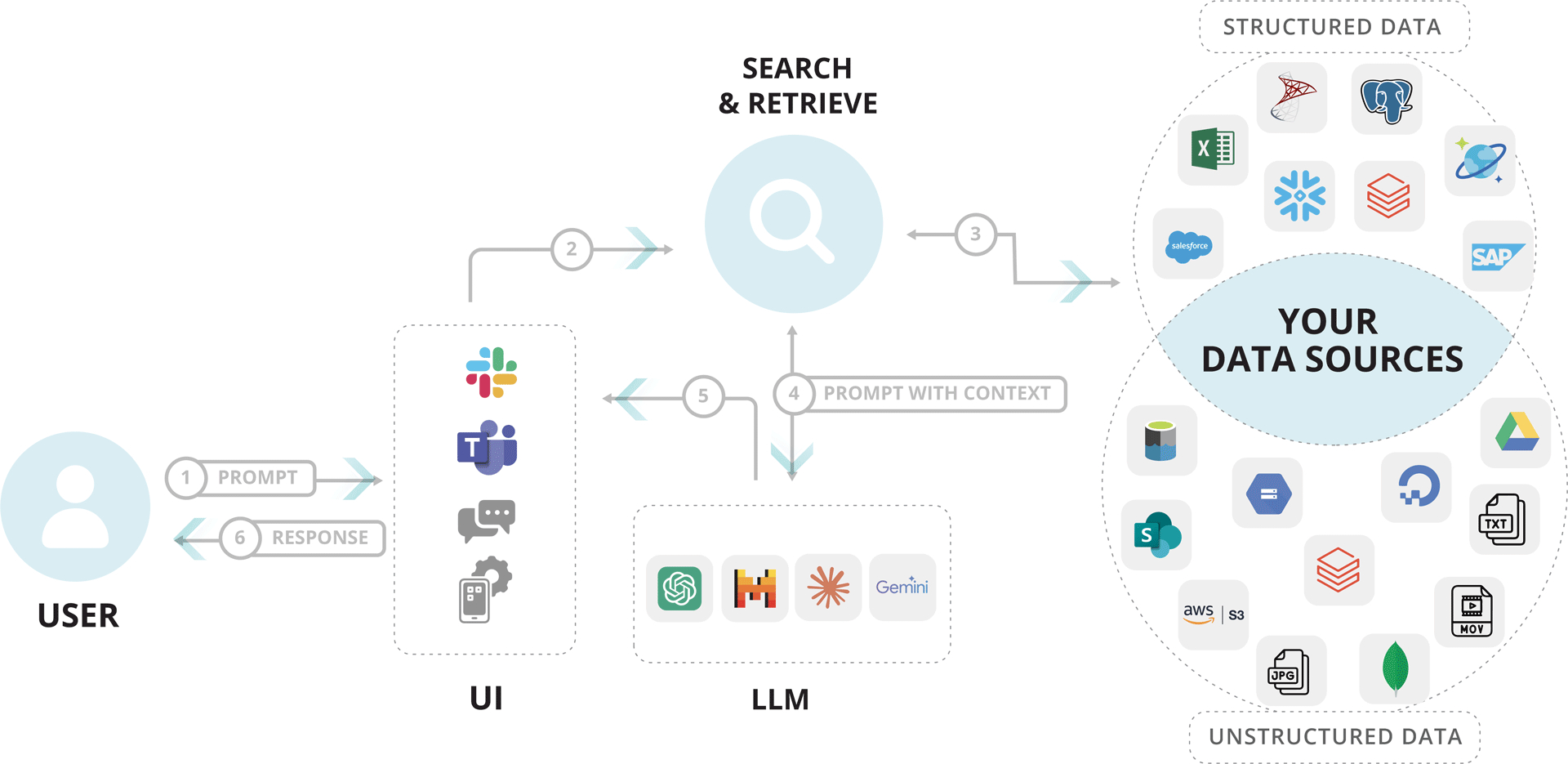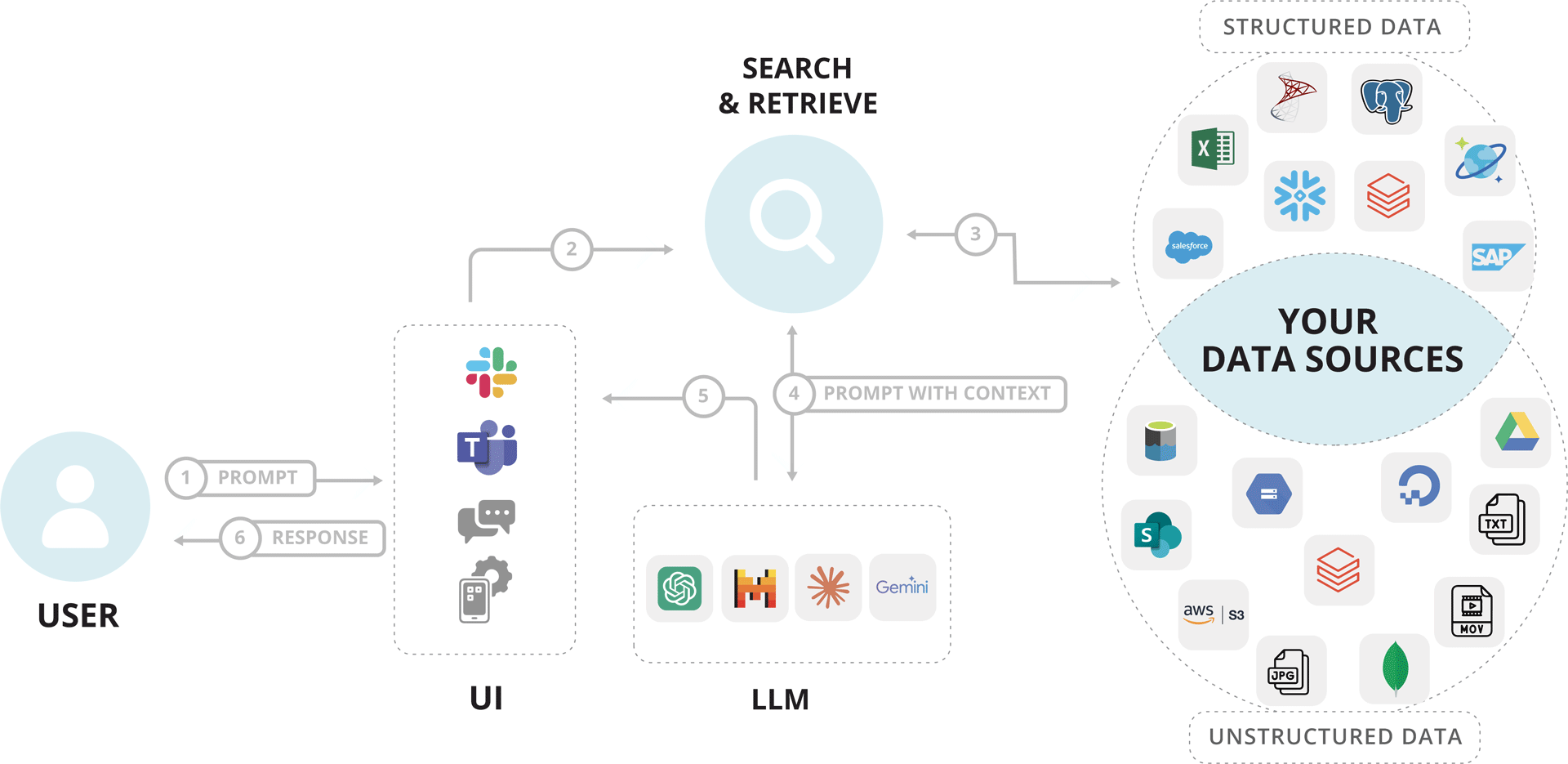
RAG = Search & Retrieve
- Pulls chunks of knowledge from static/unstructured sources (PDFs, websites, documents).
- Works best with textual info and semantic search.
- Mostly read-only and stateless (you ask, it fetches).
Use case:
“Search my company docs for HR leave policy.”
If your HR manual is uploaded as a PDF/doc, RAG can search & quote.
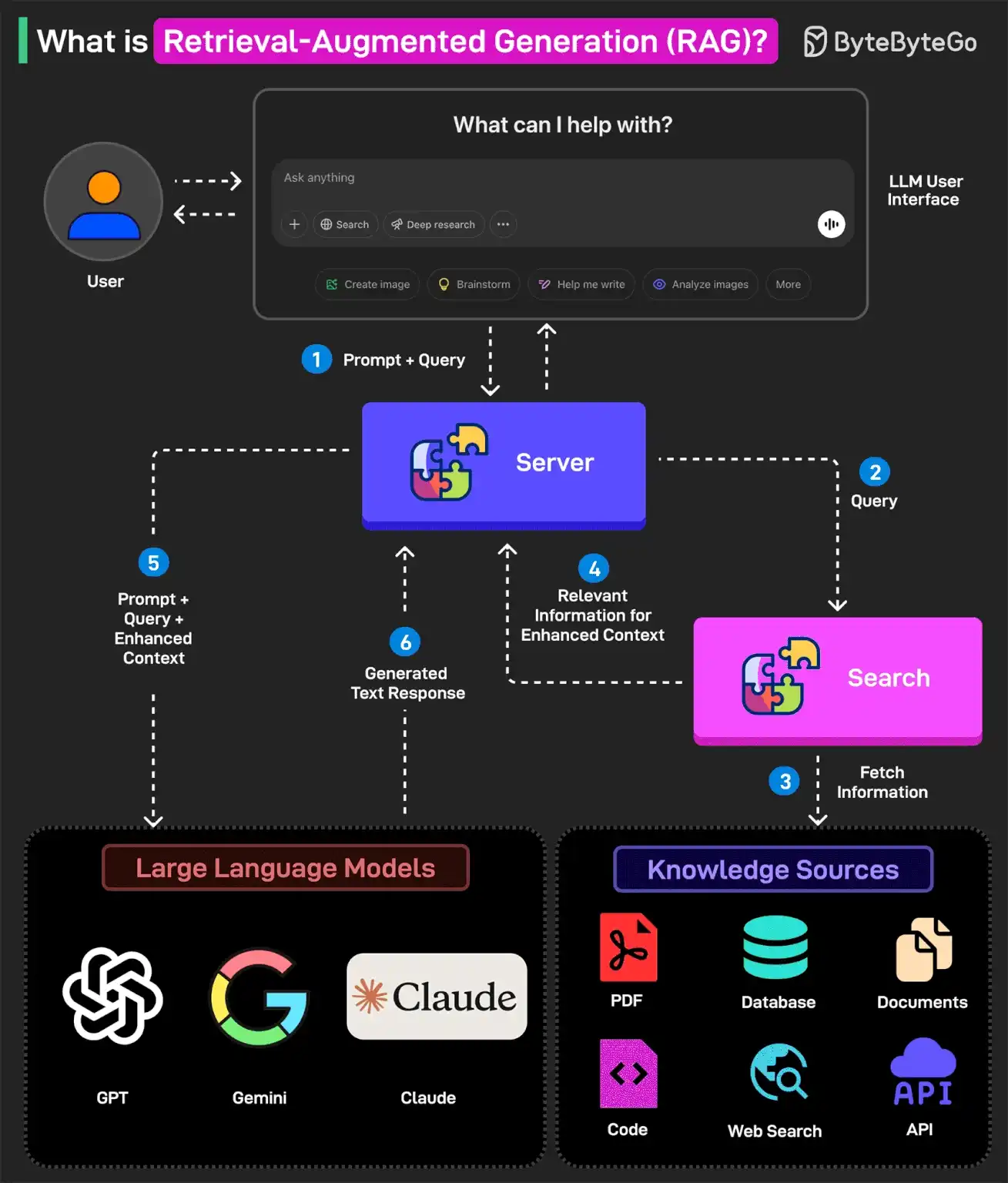
The Process:
- User Prompt: → User asks a question via the LLM interface.
- Query Sent to Search Module:→ The server extracts the core query from the prompt.
- Information Retrieved:→ Search module fetches data from external sources like PDFs, APIs, databases, web etc.
- Context Returned:→ Relevant documents or snippets are returned to the server.
- Enhanced Prompt to LLM:→ Server combines original prompt + retrieved data = enhanced input.
- LLM Generates Response:→ Model (GPT, Claude, Gemini) uses both to generate a better, context-rich answer.
🔍 Common External Sources Used in RAG:
| Source Type | Examples |
|---|---|
| 🌐 Web Search | Bing, Google, Brave API, Perplexity |
| 📄 Documents | PDFs, Word files, HTML, Markdown |
| 🗂️ Knowledge Base | Notion, Confluence, SharePoint |
| 🛢️ Databases | PostgreSQL, MySQL (read-only access) |
| 🧠 Vector DBs | Pinecone, Weaviate, FAISS, Chroma |
| 🧬 APIs | Custom REST APIs (e.g., weather, finance) |
| 👩💻 Codebase | GitHub, Bitbucket repos |
Note: To use Notion, Confluence, or any private data with RAG, you must manually prepare and store it in a Vector DB first.
Now, let's go ahead and ask Claude or any other LLM,
"How many pending leaves do I have currently in my company?"
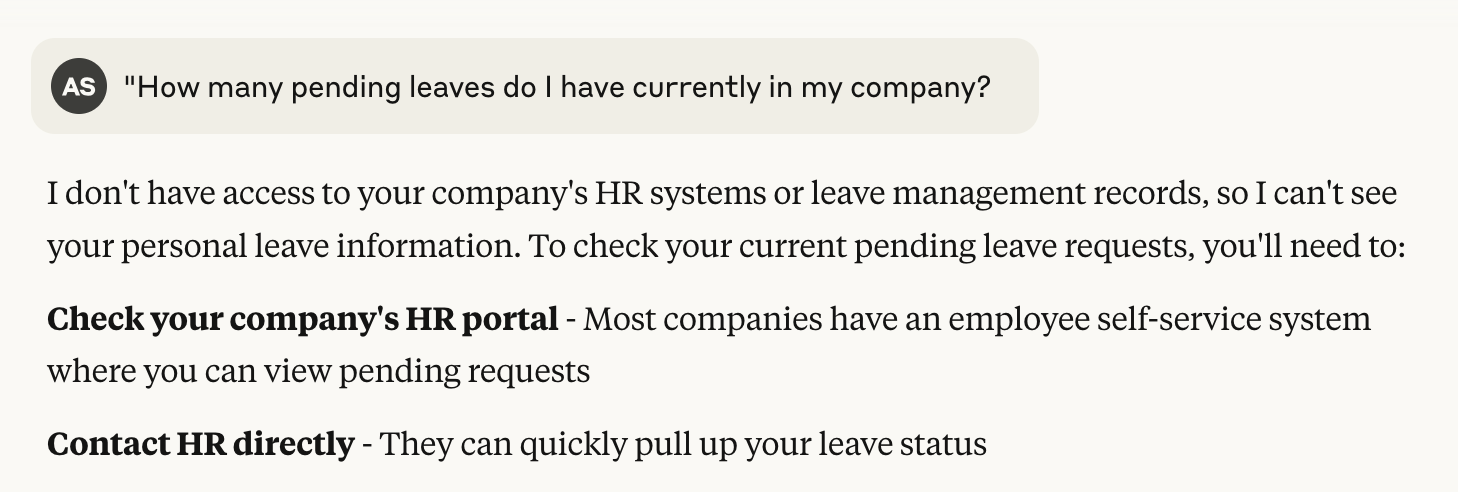
That's when MCP comes in
🔌 What is Model Context Protocol (MCP)?
Model Context Protocol (MCP) is a new open standard introduced by Anthropic that connect directly to real-world tools custom integration code each time. It works like a universal adapter, enabling AI to fetch, read, and even act on live data securely and efficiently. Because it's open-source, anyone can build or plug in their own MCP server, making it easy to extend AI capabilities in a plug-and-play way across any system or organization.
In their official document, they have defined MCP as USB-C port.
How does it work?
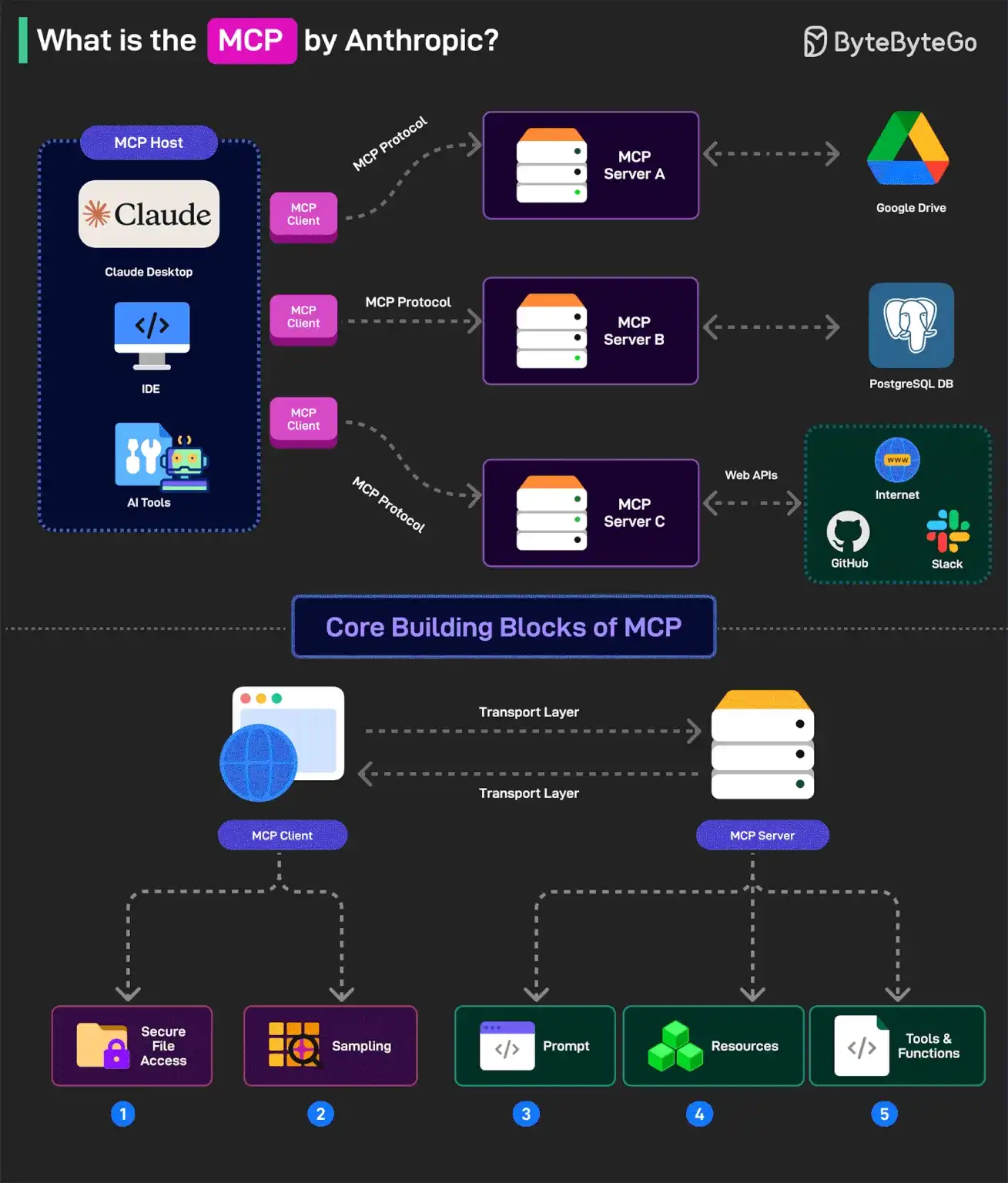
- MCP Host Setup: Claude Desktop acts as the MCP Host. It runs an MCP Client inside, which can communicate with multiple external MCP Servers.
- Connecting to MCP Servers: The MCP Client connects to various MCP Servers (like Google Drive, PostgreSQL, or GitHub) using the MCP protocol.
- Triggering via Prompts: When you ask something like “Get me the latest file,” Claude sends a structured request to the right MCP Server.
- Data Retrieval: The MCP Server fetches the real-time data from the connected tool and returns it to Claude for generating a response.
🟡 As of now, only Claude (Anthropic) officially supports Model Context Protocol (MCP) natively.
| LLM Platform | MCP Support | Details |
|---|---|---|
| Claude (Anthropic) | ✅ Yes (Desktop version) | Full MCP support. Can connect to Notion, Drive, APIs, etc. via MCP servers. |
| Grok (xAI / Elon Musk) | ❌ No | Focused on X (Twitter) data. No known support for MCP or external tools. |
| Perplexity AI | ❌ No | Uses live web search and retrieval, but does not support MCP or external tool connections. |
| ChatGPT (OpenAI) | ❌ No | Uses internal tools like RAG, code interpreter, browsing — but not MCP. |
| Gemini (Google) | ❌ No | Similar to ChatGPT; no current support for the MCP standard. |
Real world use case:
Suppose you want an LLM like Claude to answer questions not just based on its training data or the web, but also using your company’s internal knowledge—like project PRDs, business strategies stored in Notion, or HR policies from your HR tool. By connecting these tools via an MCP server, the LLM can securely access and respond with accurate, real-time answers from your actual company data.
Nutshell
RAG, or Retrieval-Augmented Generation, allows an LLM to pull in up-to-date information from external sources like the web, public databases, or other live data to answer questions about recent events or topics beyond its training data cutoff. This way, the LLM can provide current information even if it wasn't originally trained on it.
MCP, or Model Context Protocol, is about connecting the LLM to specific, private, and often real-time data sources within an organization. This means you can integrate the LLM with internal tools like Notion or other proprietary databases, so it can fetch and use the most current internal data without needing to go through a public source.
(MCP is action + access + integration, RAG is mostly read-only).