'AI Engineering' Summary
Building Applications with Foundation Models.

In 2025:
> Enterprises spent $37 billion on generative AI alone—a staggering 3.2x increase from 2024.
> 88% of organizations now use AI in at least one business function (McKinsey Global Survey 2025).
> Globally, private AI investment hit record highs, with generative AI attracting billions and adoption surging to where roughly one in six people worldwide use gen AI tools. The global AI software market is projected to reach hundreds of billions by the end of the decade, driven by foundation models whose training costs now exceed hundreds of millions for frontier systems.
This explosive growth marks the era of AI Engineering—a paradigm shift from traditional machine learning's model-centric focus to building robust, production-grade systems around powerful off-the-shelf foundation models. Chip Huyen's AI Engineering captures this transformation perfectly. Here's a comprehensive, standalone deep-dive that distills every major concept, pattern, and strategy from the book—no need to read the original to master modern AI building.

Chapter 1: The Shift to AI Engineering and the Power of Scale
Traditional ML engineering revolved around training custom models from scratch on labeled data—think collecting thousands of resumes to train a named entity recognizer with spaCy.
Today, AI engineering leverages foundation models (like GPT-4, Llama, or Claude) via APIs or open weights. The focus shifts to data-and-context-centric design: prompting, retrieval, orchestration, and reliability engineering for non-deterministic outputs.
Scale defines everything. Larger models (now in the trillions of parameters for frontier ones) unlock emergent capabilities—abilities like code generation that arise unexpectedly from next-token prediction.
The modern AI stack includes:
- Infrastructure (GPUs, serving)
- Model development (finetuning, quantization): Mix proprietary (Claude 4.6 Opus, Gemini 3.1 Pro) + open (Llama 4 Maverick, DeepSeek V3.2, Mistral 3).
- Application layer : Prompting → Advanced RAG → Multi-agents → Feedback flywheel + UI.
Real Production Example: DoorDash's dasher support chatbot (deployed 2025–2026) — in-house RAG + LLM guardrails + LLM-as-judge → automates responses, slashes resolution time. They route simple queries to cheaper models, complex to reasoning-heavy ones like Claude.
Chapter 2: How Foundation Models Really Work
LLMs process tokens—subword units from text turned into integers via tokenization.
![The Road to LLM: What is a Tokenizer? [Day 3] – Bilel KLED](https://kbilel.com/wp-content/uploads/2024/12/image.png)
AI Model Training occurs in phases:
- Pre-training (the "Shoggoth"): Massive unsupervised next-token prediction on internet data → learns patterns but no alignment.
- Supervised Finetuning (SFT): Instruction-response pairs teach assistant behavior.
- Preference Alignment (RLHF/DPO): Rankings make outputs helpful, harmless, honest.
Full transformer block flow with token embeddings + attention + output logits:
![3] Journey of a single token through the LLM Architecture | Mayank Pratap Singh ML Blogs](https://raw.githubusercontent.com/Mayankpratapsingh022/blog-site/refs/heads/master/public/images/blog/LLM_arc.gif)
2026 Top Models:
- Claude 4.5 Sonnet — Ethical, hybrid reasoning, 1M token context.
- Gemini 2.5 Pro — Multimodal (text+video+audio), sparse MoE, "thinking model".
- Grok 4.1 — Unfiltered, real-time knowledge, strong math/coding.
- Llama 4 — Open, MoE architecture (Scout/Maverick variants).
- Mistral Large 3 — Portable, efficient on edge.

Chapters 3–4: Evaluation – From Vibes to Production Reliability
Evaluating AI systems (especially large language models like GPT, Claude, Gemini, or Llama in 2026) is much harder than traditional apps or old-school ML models. Here's a simple, step-by-step explanation of why it's tricky and how people actually do it in the real world — plus one perfect GIF to show the core idea.
Why Is Evaluating AI So Hard?
- No single "correct" answer
- Old ML: "Is this photo a cat?" → Yes/No → easy accuracy score.
- Modern AI: "Summarize this 10-page report" or "Explain quantum computing like I'm 12" → many good ways to answer. No exact match possible. It's open-ended → we call this "vibes-based" if we just eyeball it.
- Models cheat by memorizing (data contamination)
- Many popular tests (like MMLU = multiple-choice questions about school subjects) are all over the internet.
- Big models read almost the entire internet during training → they sometimes just remember the answers instead of truly understanding. → Scores look amazing (90%+), but it's fake intelligence — like a student who memorized the exam questions.
- Hallucinations hide easily
- The AI can confidently say wrong things that sound right. Hard to catch automatically.
How Do Real Teams Evaluate AI in 2026?
Method 1: Exact Match (only for simple stuff)
- Works when there's one right answer: math problems, multiple-choice, code that passes tests.
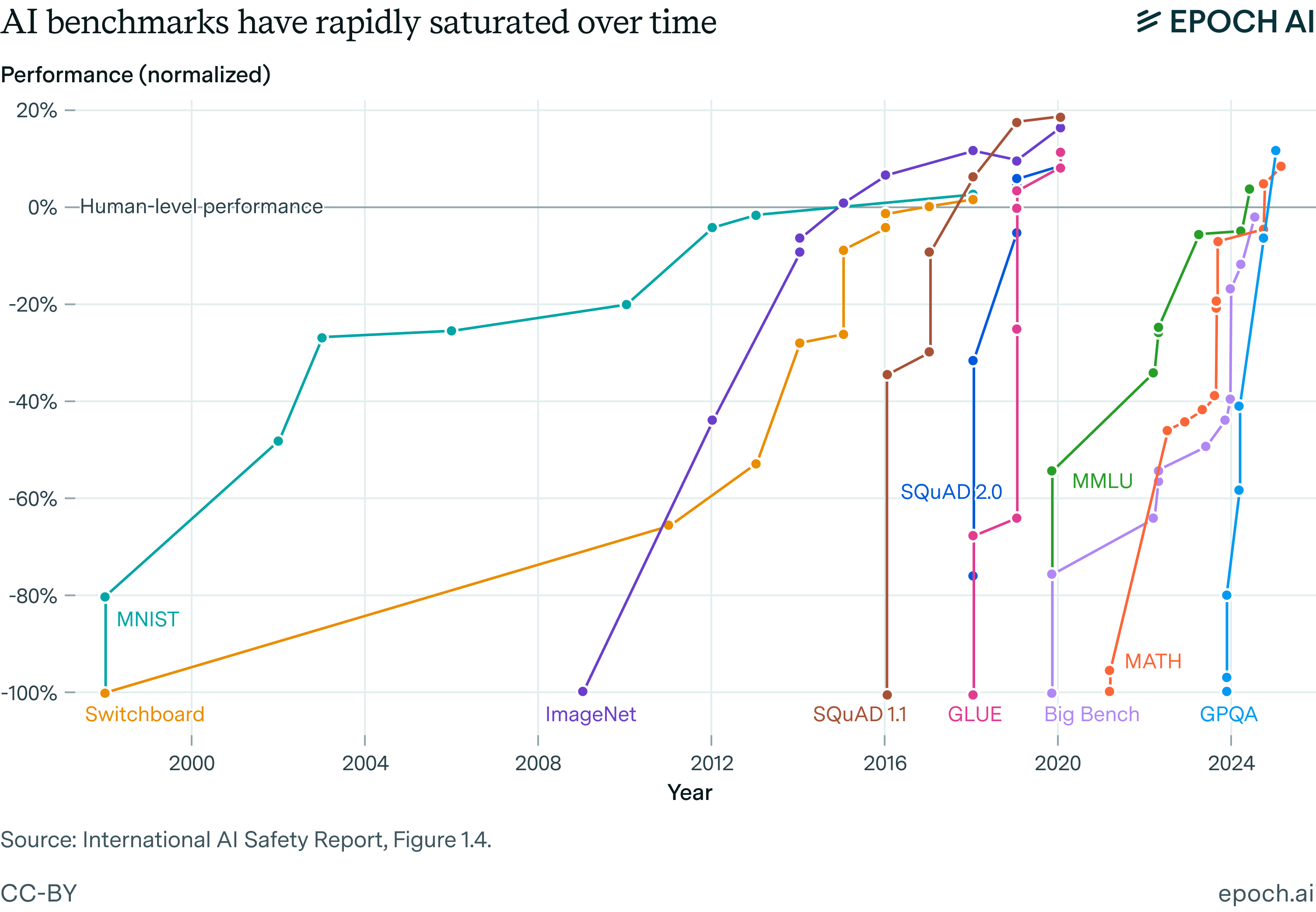
- Example: GPQA Diamond benchmark → super-hard science questions humans get ~30–40% right. Gemini models now score ~94% → real progress (not just memorization).
Method 2: AI as a Judge (most popular today)
- Use a strong model (like Claude 4.6 or GPT-5 level) to grade weaker ones.
- You give it a clear rubric (scoring guide):
- Is it helpful? (1–5)
- Is it faithful / no hallucination? (Did it stick to facts or make stuff up?)
- Is it polite / safe?
- Super simple prompt example: "Here is the user's question, the provided facts, and the AI's answer. Rate faithfulness 1–10. Only use information from the facts."
Method 3: Holistic Pipeline Check (for full RAG systems)
When you build a real product (chatbot that searches company docs), check 3 things:
- Context precision → Did we find the right documents? (aim >95% recall@10 = top 10 results include the good stuff)
- Faithfulness → Did the answer only use the retrieved info? (no made-up facts)
- Answer relevance → Did it actually solve the user's question?

Example: LinkedIn customer support chat → They use RAG (search internal knowledge + knowledge graph). → Evaluation → AI judge + some human checks → 28.6% faster ticket resolution. → They track: Did the answer fix the issue? Was it polite? No hallucinations about company policy?
Chapter 5: Prompt Engineering – Production-Grade Mastery (Simple 2026 Explanation)
Prompt engineering is basically how you talk to the AI so it gives you the best, most reliable answers — especially in real apps where mistakes cost money or time.
Anatomy of a Good Prompt (Breakdown – Super Simple)
A strong prompt usually has a few parts:
- System prompt (the "persona/role") Tells the AI who it is. Example: "You are a senior software engineer with 10+ years of experience in backend APIs. Always respond in valid JSON only."
- Few-shot examples (5–10 good ones) Show-don't-tell. Give 5–10 real input → perfect output pairs so the AI learns the pattern. This is huge in 2026 — zero-shot (no examples) often fails on tricky formats; few-shot jumps accuracy from 60–70% to 95%+.
Advanced Techniques in 2026:
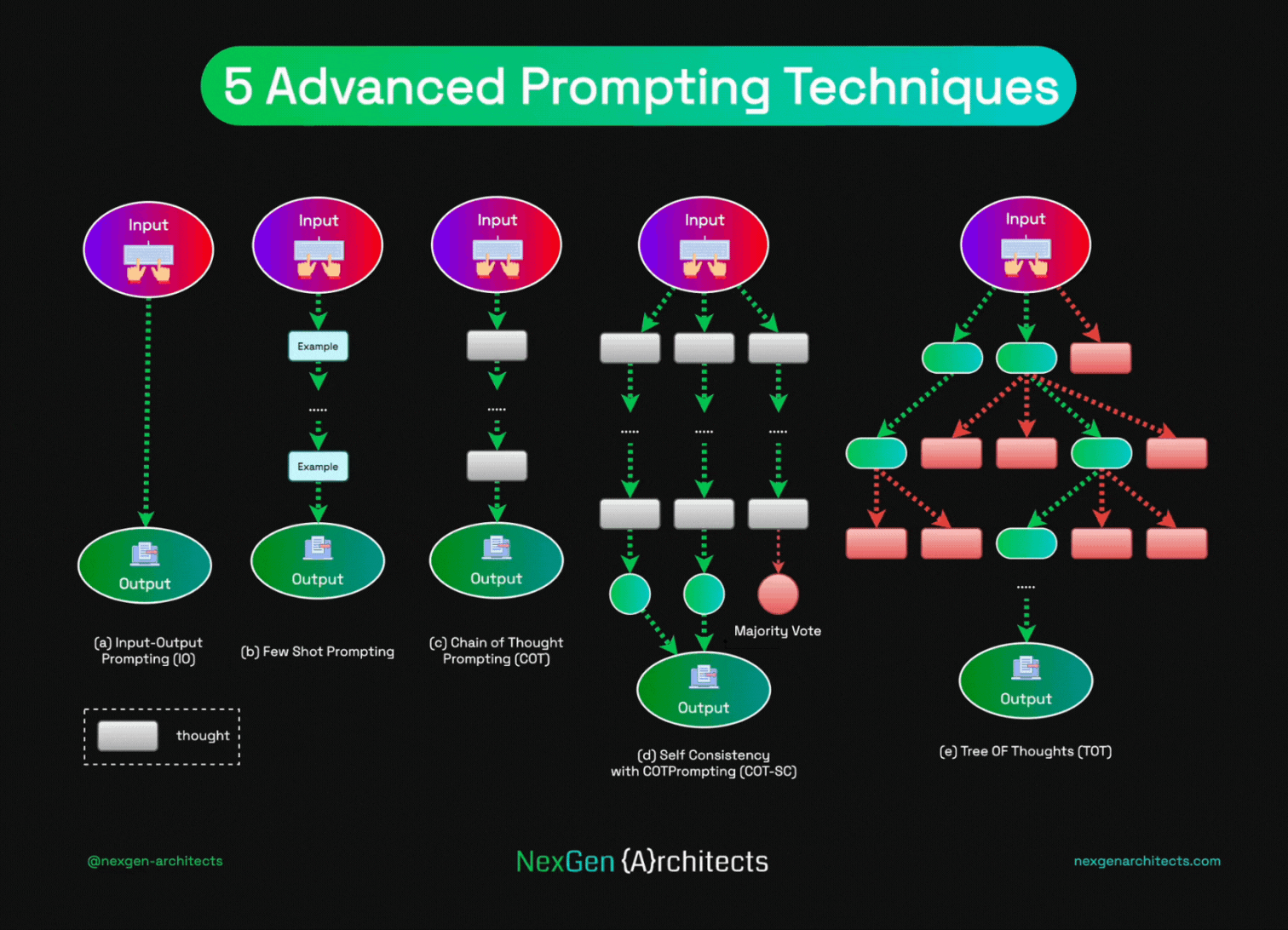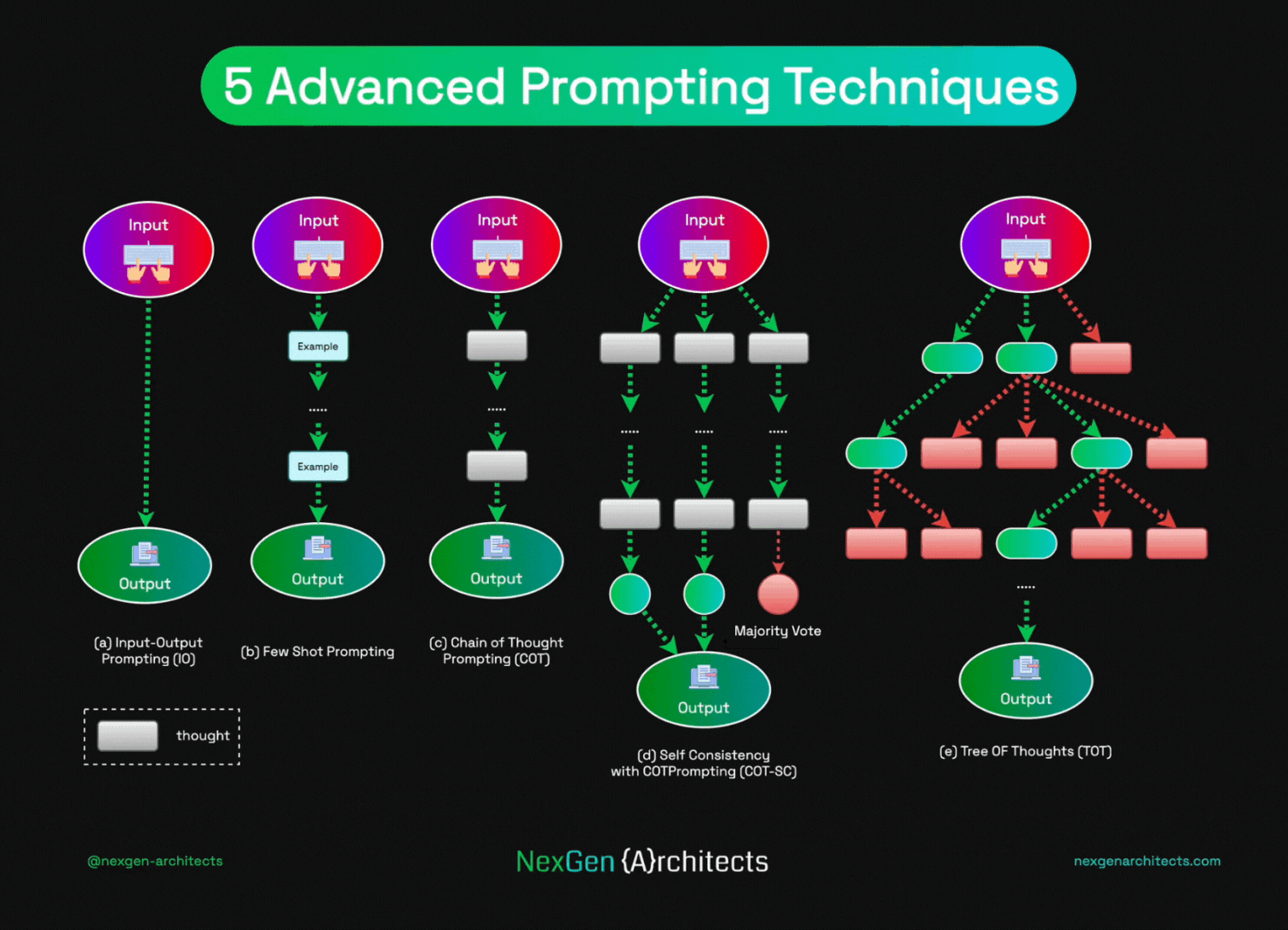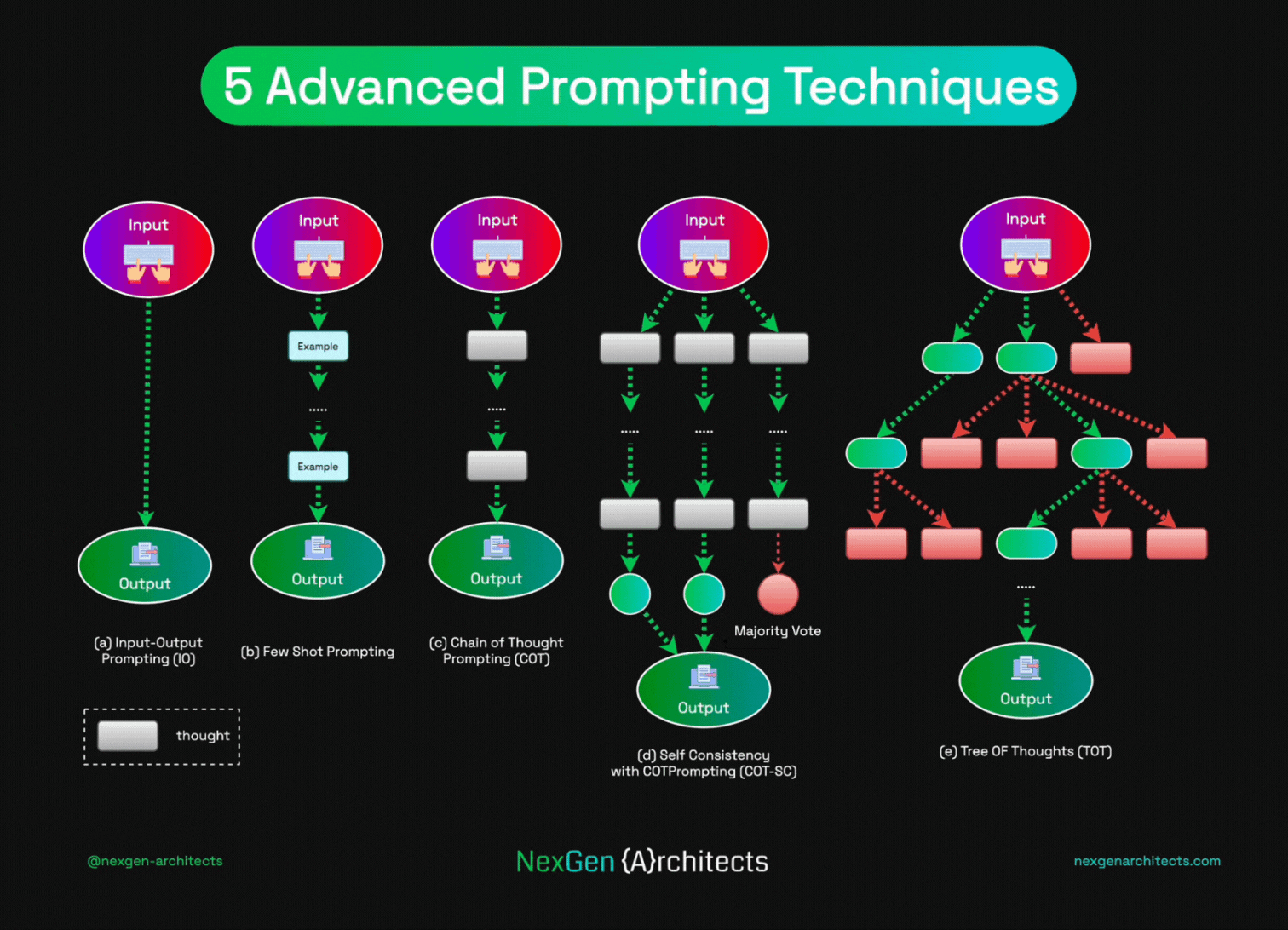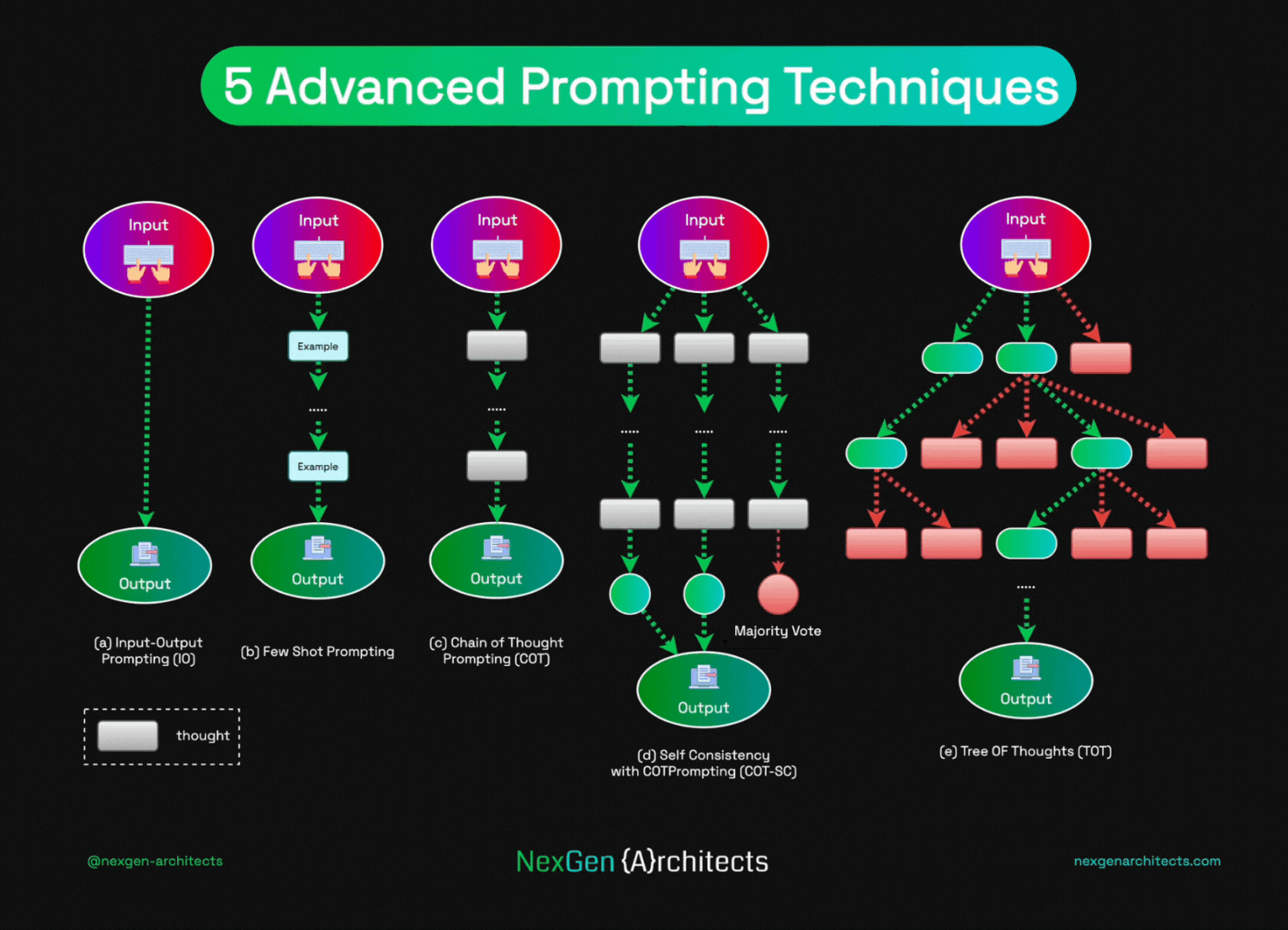
1. Chain-of-Thought (CoT) + Self-Reflection
Tell the AI: "Think step-by-step before answering."
This makes it write out reasoning first → huge boost on math, logic, coding (30–50% better on hard problems with models like Gemini 3.1 Pro or Claude 4.6).
Self-reflection = ask it to check its own answer afterward ("Is this correct? Fix if wrong").
![3] Prompt Engineering: Mastering Chain-of-Thought, HyDE, and Step-Back Techniques | Mayank Pratap Singh ML Blogs](https://blogs.mayankpratapsingh.in/images/blog/chain-of-thought/7.gif)
2. Self-Consistency
Ask the same question 8–16 times (with slight rephrasing or temperature).
Take the most common answer (majority vote).
Great for math/reasoning — reduces random errors.
Real-World Example: Banking API JSON Extraction
Problem: You have messy customer messages like:
"Send 5000 to account 12345678 please" or "Transfer ₹10,000 INR from savings to credit card ending 4567"
You need perfect JSON every time:
JSON
{"action": "transfer", "amount": 10000, "currency": "INR", "from": "savings", "to": "credit_card", "last4": "4567"}
Solutions:
Zero-shot (just "Extract to JSON"): → 60–75% success, misses formats, hallucinates fields.
Few-shot (give 5–10 perfect messy → JSON examples in prompt): → Mistral-7B or Llama-4-8B hits 98%+ even on weird edge cases (typos, mixed languages, abbreviations).
Many Indian fintechs (Paytm-like apps, Razorpay internal tools) do exactly this in 2026 — few-shot + delimiters + strict schema validation.

Chapter 6: RAG & Agents – Grounding Knowledge & Autonomy
RAG and Agents are the two biggest ways companies make AI actually useful and trustworthy in real products in 2026 — instead of just hallucinating or being stuck with old knowledge.
What is RAG?
RAG = Retrieval-Augmented Generation
= "Look up real facts first, then answer using them."
Why needed?
- LLMs like Grok 4.1 or Claude 4.6 have knowledge cutoffs and can confidently make up stuff (hallucinations).
- RAG fixes this by searching your own documents/company data before answering.
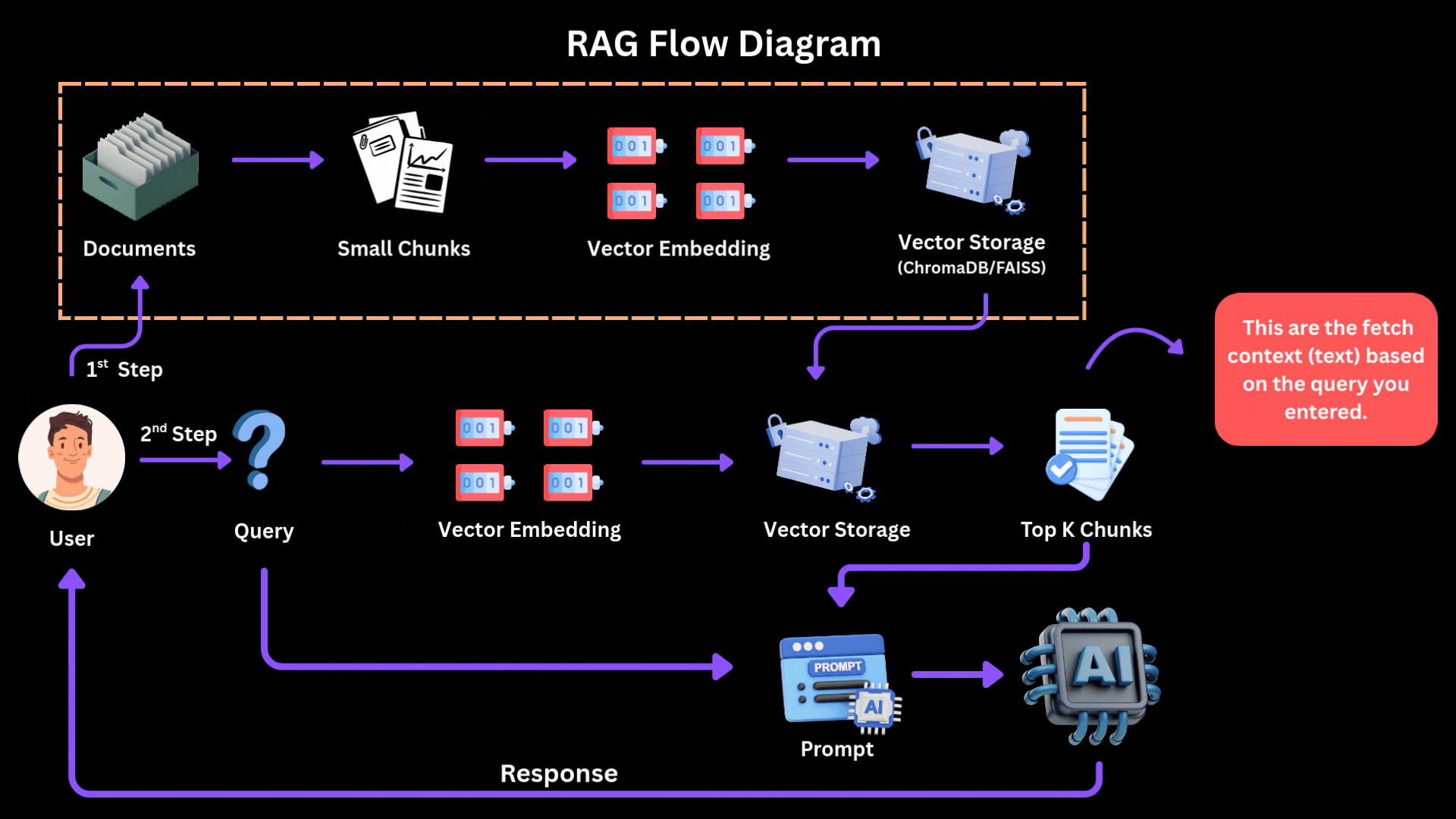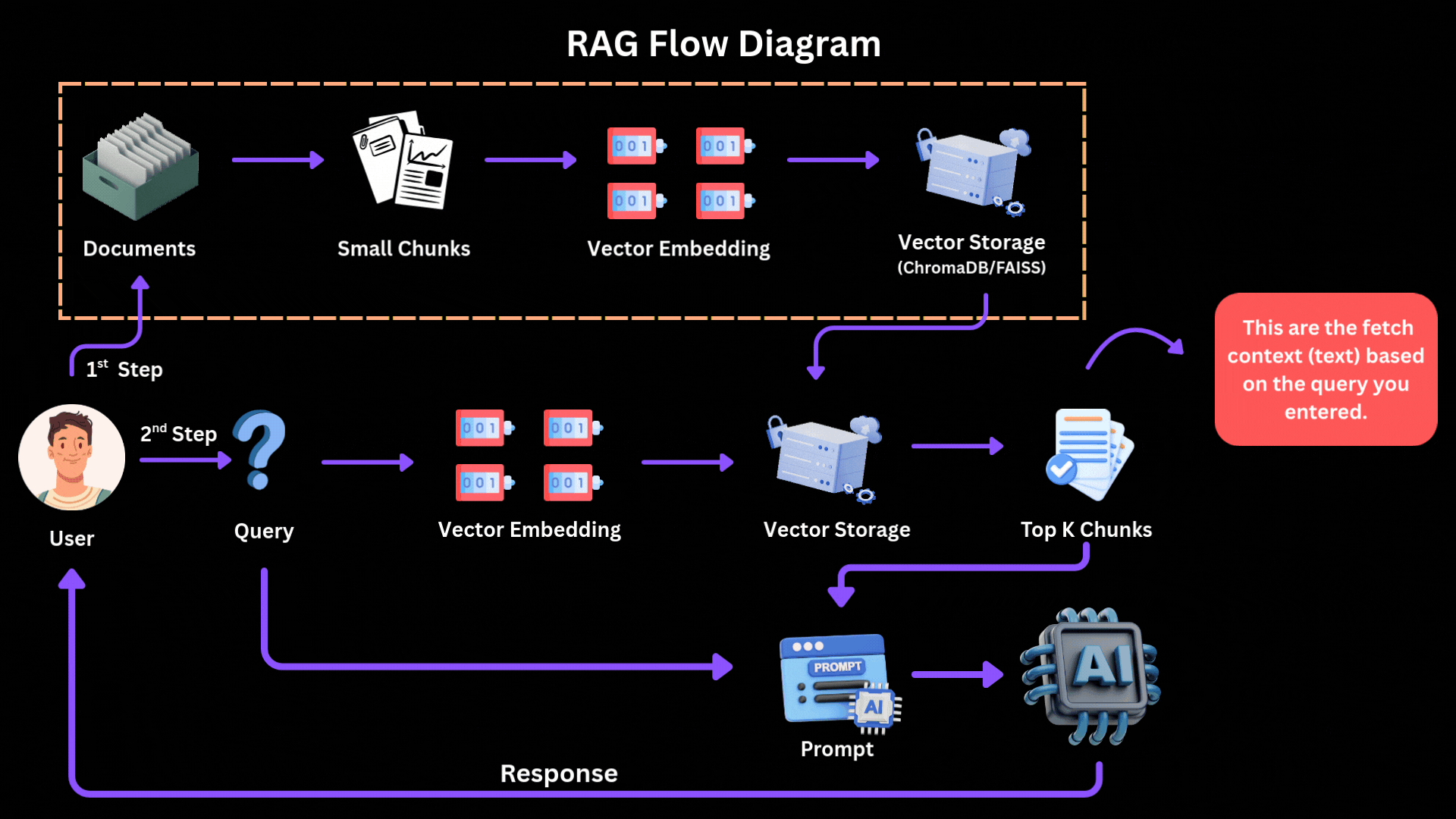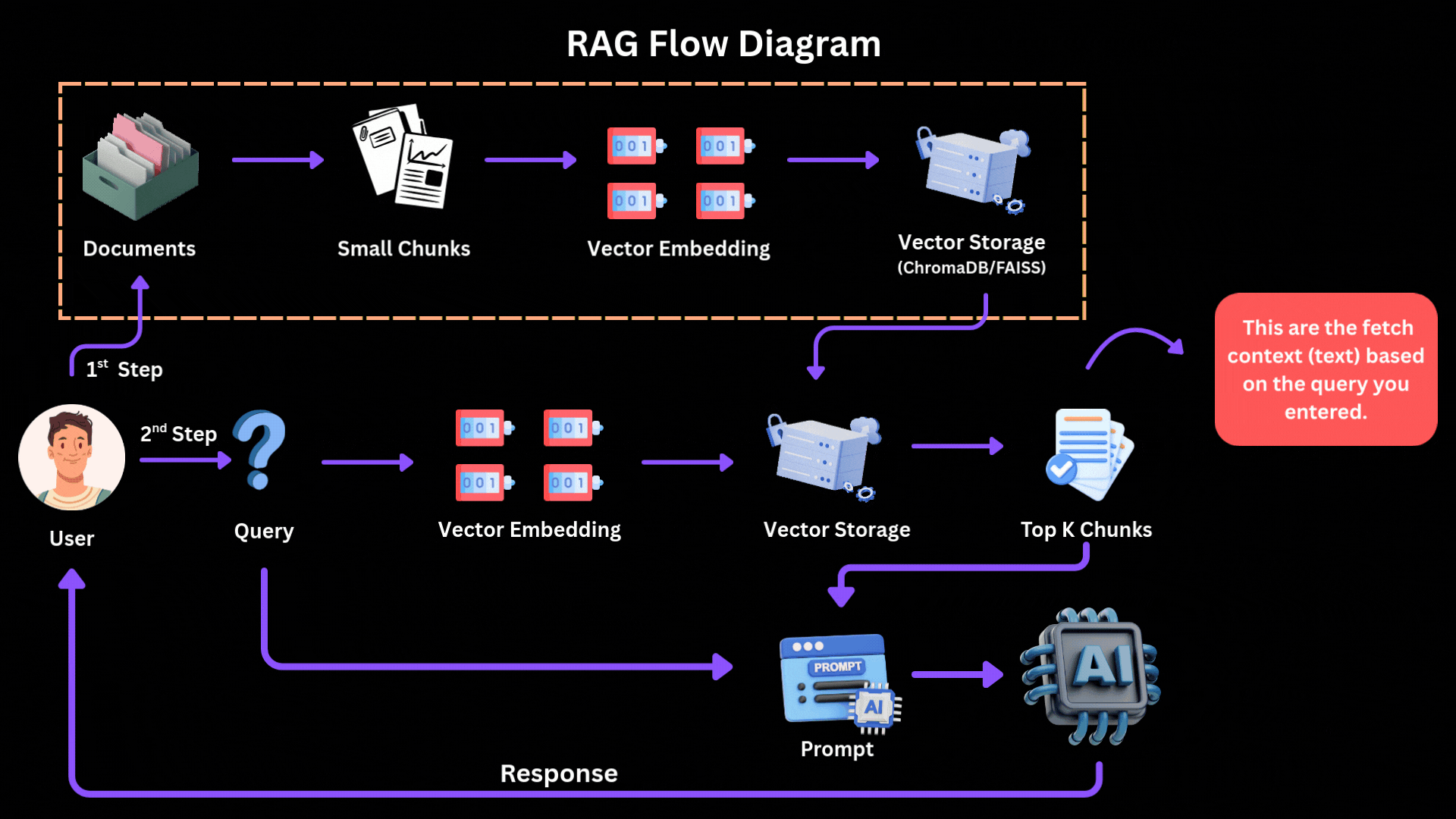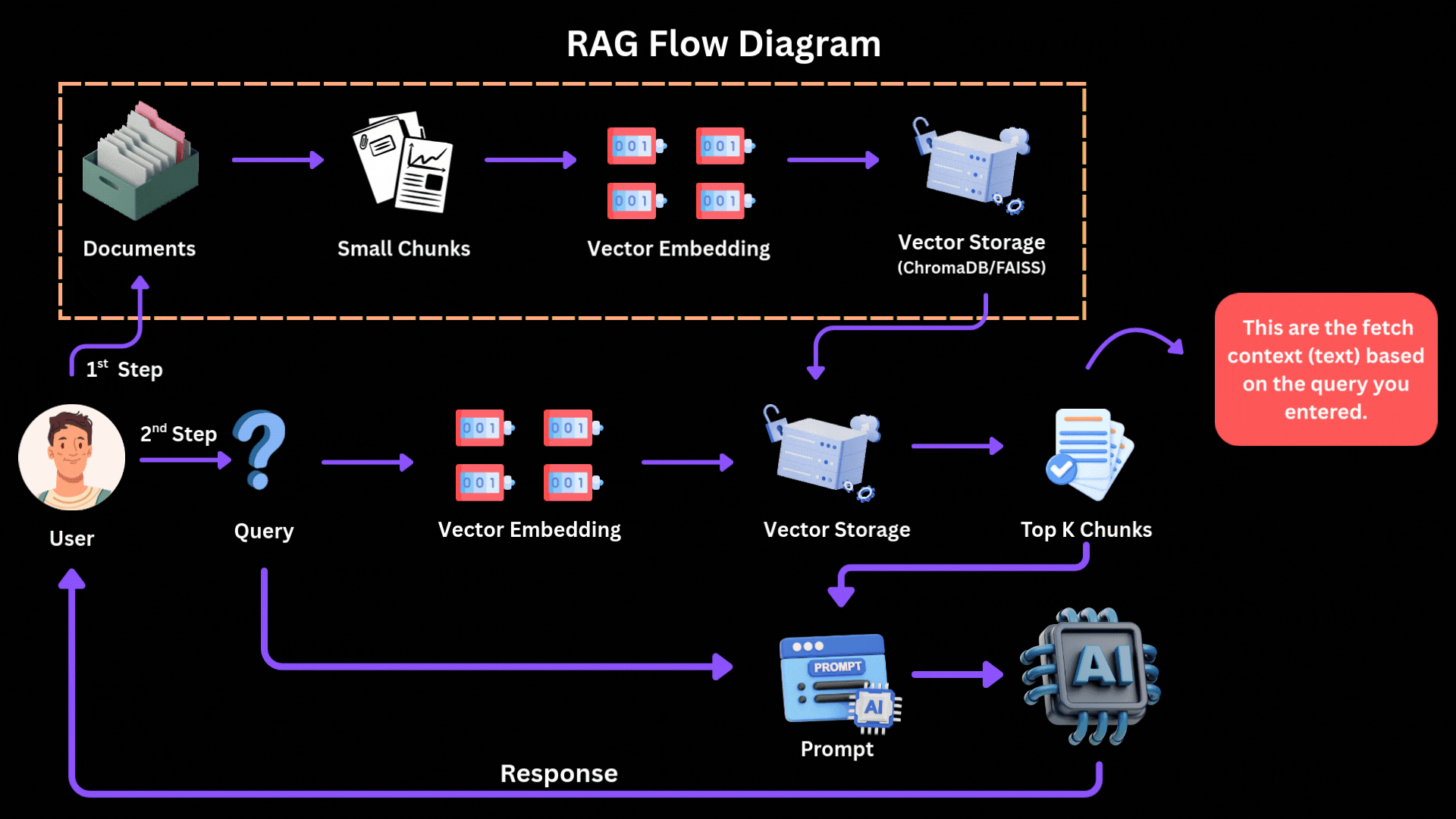
How the 2026 Production RAG Pipeline Works

- Chunking — Break big PDFs/docs into small pieces (200–512 tokens). Use semantic chunking (group by meaning) + fixed size.
- Embed — Turn each chunk into a vector (number array) using good embedders like Mistral embeddings or OpenAI text-embedding-3-large.
- Store in Vector DB — Save vectors in Pinecone, Weaviate, Chroma, or Elasticsearch.
- Hybrid Search — When user asks question:
- Convert question to vector → find similar chunks (semantic search).
- Also do keyword search (BM25) for exact matches.
- Combine both.
- Reranker — Take top 50 results → use a smart reranker (Cohere Rerank or BGE-reranker) to pick the true best 5–10.
- Generation — Stuff those best chunks into prompt → ask LLM (Claude/Gemini/Mistral) to answer grounded in them only.
[You see files go in, get vectorized, query comes, smart search finds relevant pieces, LLM generates grounded answer.]
Real-World Examples Everyone Uses in 2026
- Wealth management firms (like Indian ones – Zerodha, Groww internal tools) → Advisor asks: "Best mutual fund for 35-year-old moderate risk?" → RAG pulls latest SEBI regs, fund performance data, client profile → grounded recommendation.
- Hospital networks / clinical decision support → Doctor queries patient history + latest guidelines. → RAG → 30% fewer misdiagnoses (real stat from 2025–2026 deployments) because it sticks to verified medical knowledge.
What are Agents? (Super Simple)
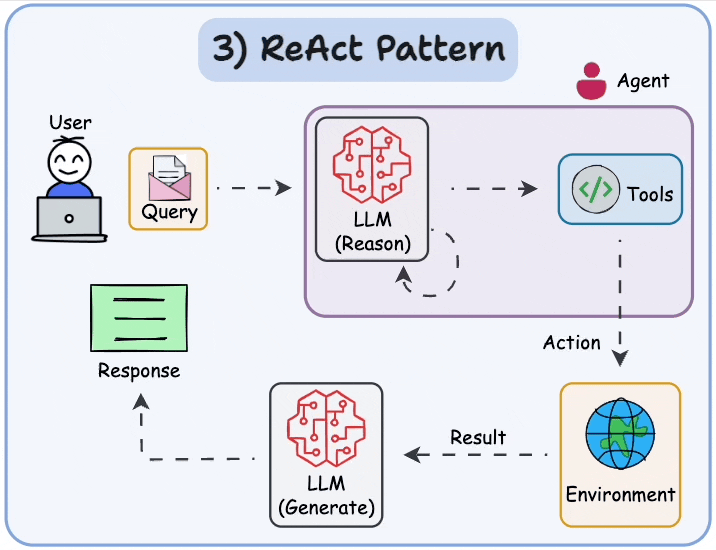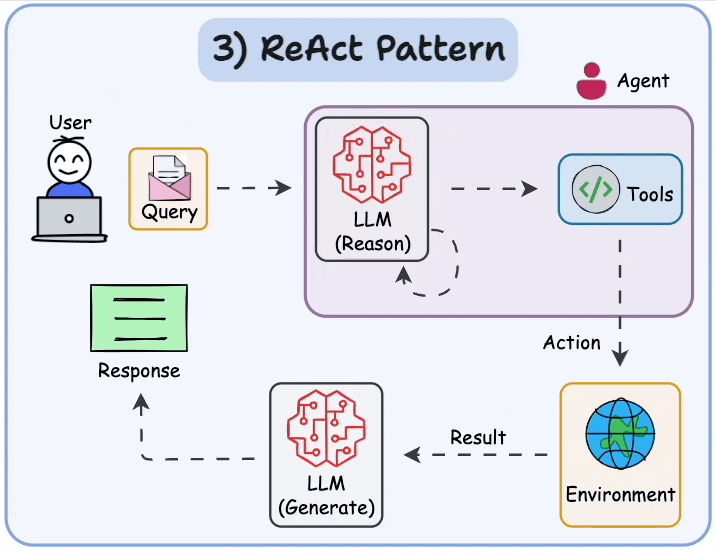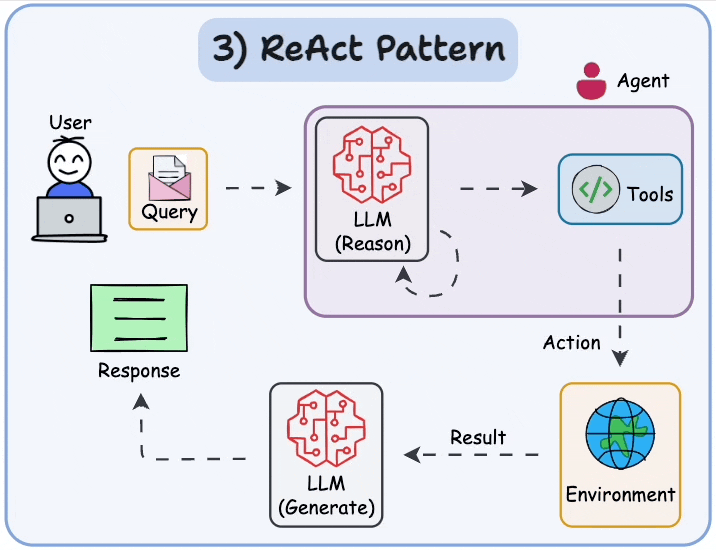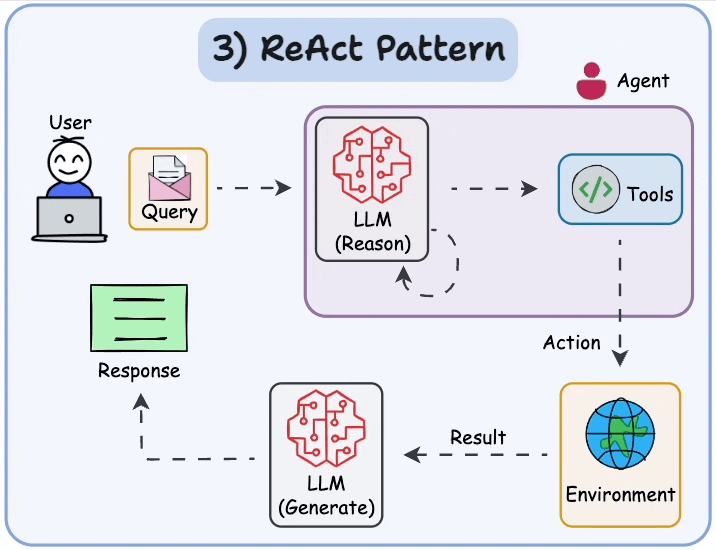
Agents = AI that can think, use tools, and loop until done — instead of one-shot answers.
Most common pattern: ReAct (Reason + Act)
- Reason (think): "What should I do next?"
- Act (use tool): Call calculator, search web, check calendar, run code, etc.
- Observe (see result): Get output from tool.
- Repeat until good answer → then give final response.
Frameworks people actually use
- LangGraph → Builds stateful loops/graphs (very popular for complex agents).
- LlamaIndex → Great for RAG grounding + agents.
- CrewAI → Easy multi-agent teams (one researches, one writes, one reviews).
Real-World Example:
Travel booking bot (like MakeMyTrip / Cleartrip internal agent) → User: "Book flight to Goa next weekend." → Agent:
- Reason: Need dates, budget?
- Act: Check user calendar (tool).
- Observe: Free Sat-Sun.
- Act: Call flight API.
- Observe: Prices.
- Ask user: "Morning or evening?" → loop again → finally books.
Quick start roadmap:
Start with simple RAG (LlamaIndex + Chroma + Mistral-7B) for your side project/company docs. Add agentic loop (LangGraph) only when you need tools (APIs, search). Test faithfulness hard — hallucinations kill trust.
Chapter 7: Finetuning – Efficient Specialization
Finetuning means taking a big pre-trained model (like Llama 4, Mistral 3, or Grok 4.1) and teaching it to be better at your specific job — without starting from scratch.
In 2026, almost no one does full finetuning anymore (updating every single parameter) because it's super expensive in GPU memory and time. Instead, we use efficient methods like LoRA and QLoRA — tiny changes that give almost the same results but cost 10–100x less.
The Process:
- Use RAG for new facts/knowledge (e.g., latest company policies).
- Finetune for style, format, behavior — things like:
- Always answer in strict JSON
- Speak like a polite Indian customer support agent
- Follow your company's legal tone
- Never say certain risky things
Finetuning changes the model's "personality" and reliability on your domain.
The Big Idea: PEFT (Parameter-Efficient Finetuning)
PEFT = Train only a tiny fraction of parameters (<1%) instead of the whole model.
a) LoRA (Low-Rank Adaptation) — The king in 2026
- Freeze the big model (don't touch its billions of weights).
- Add small "adapter" layers (A and B matrices) to certain spots (like attention/feed-forward layers).
- Train only those tiny adapters → ΔW = A × B (low-rank math).
- Result: You train ~0.1–1% of params → huge memory & speed win.
- After training: Merge adapters back into base model (or keep separate for switching tasks).
Here's a clear visual comparing full finetuning vs LoRA — full updates everything (huge cost), LoRA adds tiny plugins (fast & cheap):
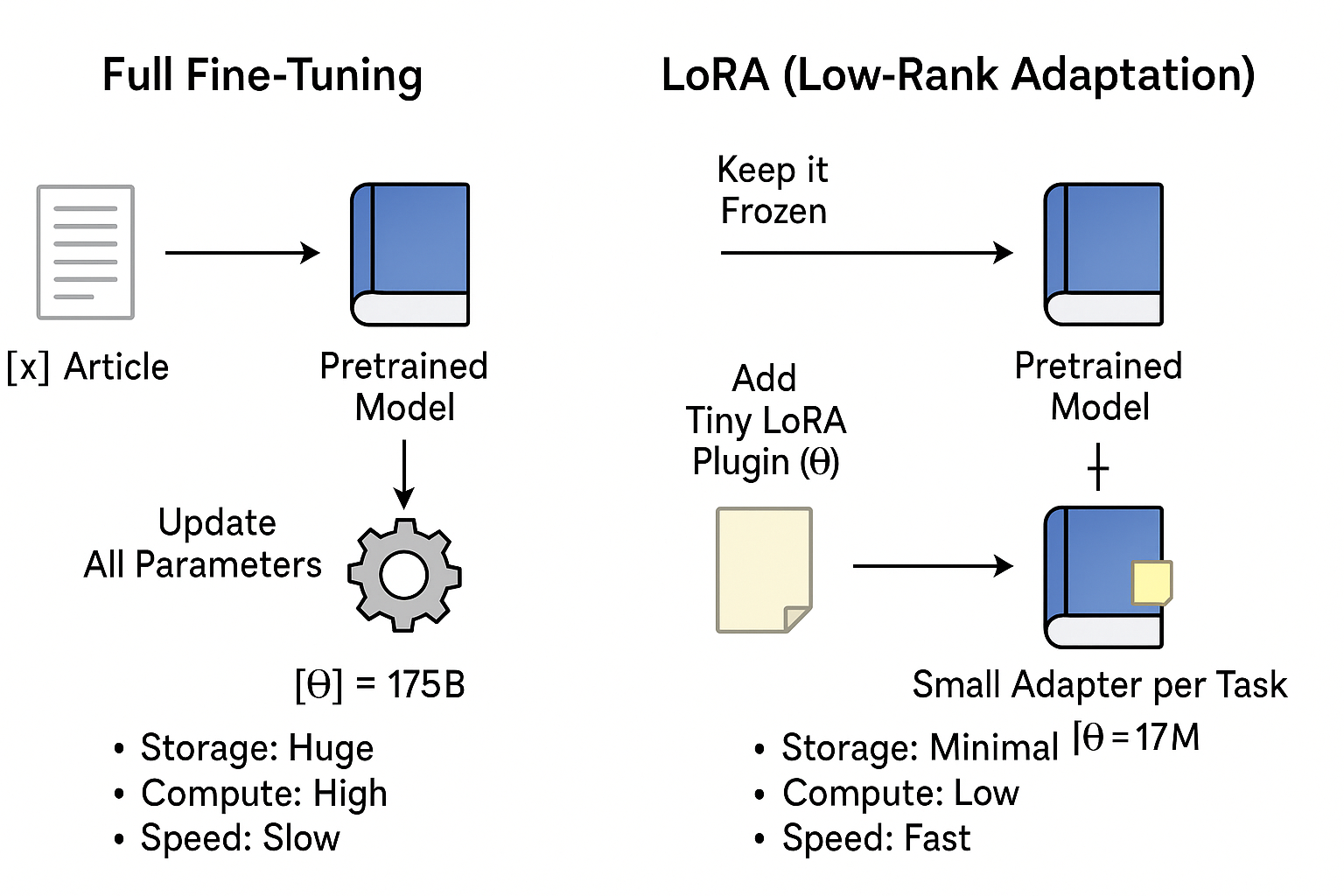
LoRA math flow (frozen weights + low-rank A/B adapters added during training, merged after):
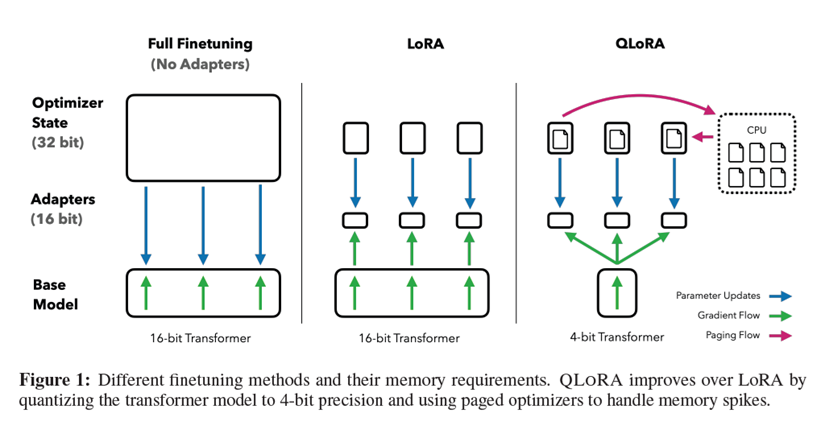
b) QLoRA = LoRA + 4-bit quantization
- Quantize base model to 4-bit (NF4/AWQ) → fits 70B model on single A100/H200 or even consumer RTX 4090.
- Use paged optimizers → no memory spikes during training.
- Train LoRA adapters on top → same quality as full 16-bit but 70–90% less VRAM.
Memory comparison (full vs LoRA vs QLoRA) — QLoRA wins for low-resource setups:
Data for Finetuning (Quality Beats Quantity)
- Need instruction format pairs: {"instruction": "Extract invoice details", "input": "Invoice #123...", "output": perfect JSON}
- 500–5,000 high-quality examples > 50,000 noisy ones (LIMA research still holds).
- Use synthetic data: Ask Claude 4.6 / Gemini 3.1 to generate 1,000 variations from 10 good seeds → filter bad ones.
Real-World Examples in 2026
- Banking/Fintech (e.g., Razorpay, Paytm internal tools) → Need perfect JSON for legacy API calls. → Few-shot prompting fails on edge cases (weird currencies, typos). → Finetune Mistral-7B or Llama-4-8B with LoRA on 800 high-quality request → JSON pairs. → Result: 99.9% syntax perfect, no hallucinations on format → deploy as tiny adapter.
- Medical / Healthcare chatbots → Finetune on PubMed abstracts + doctor Q&A pairs (LoRA on BioMistral or MedLlama). → Combine with RAG for latest papers → safer, more accurate clinical suggestions.
Quick start roadmap:
Use Hugging Face PEFT library + Unsloth (2–5x faster) + QLoRA on a rented A100 (RunPod ~₹200–300/hr). Start with 500–1k examples in Alpaca/ShareGPT format. Test on 100 holdout cases — aim for >95% on your format/style. Merge adapter → serve with vLLM for speed.

Chapter 8: Dataset Engineering – The Real Heavy Lifting
If finetuning is the "coaching" part, dataset engineering is building the perfect training material first. In 2026, people realize: the dataset is harder and more important than the model itself. Bad data = bad model, no matter how fancy the architecture. Good data = even a smaller model crushes bigger ones.
This chapter is about curating, cleaning, filtering, deduplicating, and generating high-quality data for pre-training, SFT, or finetuning LLMs.
Why Dataset Engineering Matters So Much
- Raw internet data (Common Crawl) is messy: duplicates, toxic stuff, PII (personal info), low-quality spam, boilerplate.
- Training on junk makes models memorize garbage, hallucinate more, or overfit to repeats.
- Quality > Quantity: Research (like LIMA, Phi series) shows 1,000–10,000 excellent examples beat 1 million noisy ones.
- 2026 frontier datasets (Nemotron-CC, FineWeb-Edu, Dolma) are trillions of tokens but heavily curated → that's why models keep improving.
Core Steps in the Data Curation Pipeline (Simple Breakdown)
- Collection / Ingestion — Grab raw data (Common Crawl dumps, internal docs, code repos, etc.).
- Preprocessing — Extract clean text, remove HTML/JS, detect language, normalize.
- Filtering — Throw out junk:
- Heuristics (short docs, too many symbols, PII like emails/phone numbers).
- Classifier-based (use small LLM like Mistral-7B or DeBERTa to score quality, toxicity, educational value).
- Deduplication — Remove exact/near-duplicates so model doesn't over-memorize phrases.
- Tools: MinHash + LSH (Locality-Sensitive Hashing) — fast for trillions of docs.
- Blending / Bucketing — Mix sources (Wikipedia-style high quality + diverse web) in right ratios.
- Synthetic Generation (if needed) — Use strong LLM (Claude 4.6, Gemini 3.1) to create new examples.

Deduplication – The Silent Killer Fix
Duplicates waste compute and cause overfitting (model repeats exact sentences).
- Exact dedup: Easy with hashes.
- Near-duplicate (paraphrases, minor changes): Use MinHash + LSH → cluster similar docs fast.
Synthetic Data & Distillation – When Real Data Runs Out
- Self-Instruct / Synthetic: Seed with 10–50 good examples → ask strong LLM to generate 1,000+ new Synthetic ones (instructions + responses).
- Then filter: LLM judge for quality, check if code compiles, etc.
- Distillation: Teacher (big model like GPT-5 level / Claude 4.6) generates outputs on prompts → Student (smaller like Mistral-7B or Llama-4-8B) learns from them.
- Cheaper, faster, transfers knowledge without huge raw data.

Distillation Process

Example: Proprietary language "SuperCode" (your company's internal DSL) → No public data exists. → Write 10–20 manual examples. → Feed to Claude 4.6 → generate 2,000 variations. → Filter: Run compiler on synthetic code → keep only ones that compile + pass tests. → Result: High-quality 1k–5k dataset → finetune Mistral-7B → specialized coder.
Quick start roadmap: Start small. Use tools like Hugging Face Datasets + Unsloth for loading/cleaning. Dedup with datasketch MinHashLSH. Generate synthetic with Grok/Claude API. Always run quality checks (perplexity, diversity metrics, manual spot-check). Quality dataset + QLoRA = killer combo.
Chapter 9: Inference Optimization – Serving at Scale
Inference is the part where your trained/finetuned model actually runs in production — answering real user queries, fast and cheap.
In 2026, the biggest bottlenecks aren't compute power anymore — it's memory bandwidth (moving huge model weights from VRAM to the GPU cores takes longer than doing the math) and KV cache management (storing past attention for long conversations).
The goal: Serve thousands of users at once, with low latency (<1–2 sec first token), low cost (₹0.1–1 per 1M tokens), and high throughput (tokens/sec).
Key Bottlenecks in 2026
- Memory Wall — Models like Llama 4 70B need ~140 GB in FP16 → even quantized, moving 70–140 GB around every second is slow.
- KV Cache Explosion — For long chats (10k+ tokens context), KV cache grows linearly → eats VRAM fast, limits concurrency.
- Prefill vs Decode — First token (prefill) reads whole prompt (slow), then decode (one token at a time) is autoregressive (can be fast but wastes compute if not batched).
Main Optimization Techniques:
1. Quantization — Shrink numbers from 16-bit → 8-bit → 4-bit (or even 2-bit in research)
- FP16 → INT8/AWQ/GPTQ → 2× smaller model, ~2× faster, almost no quality drop.
- QLoRA/4-bit → 70B fits in 35–50 GB VRAM (single H200/A100).
- 2026 sweet spot: AWQ or GPTQ-Int4 for most production.

2. KV Cache Management – The Real Hero
- Reuse past key/value vectors instead of recomputing attention every token.
- PagedAttention (vLLM invention, now standard) — Treat KV cache like OS virtual memory: page it out to CPU if needed, swap back → massive concurrency boost (5–20× more users per GPU).
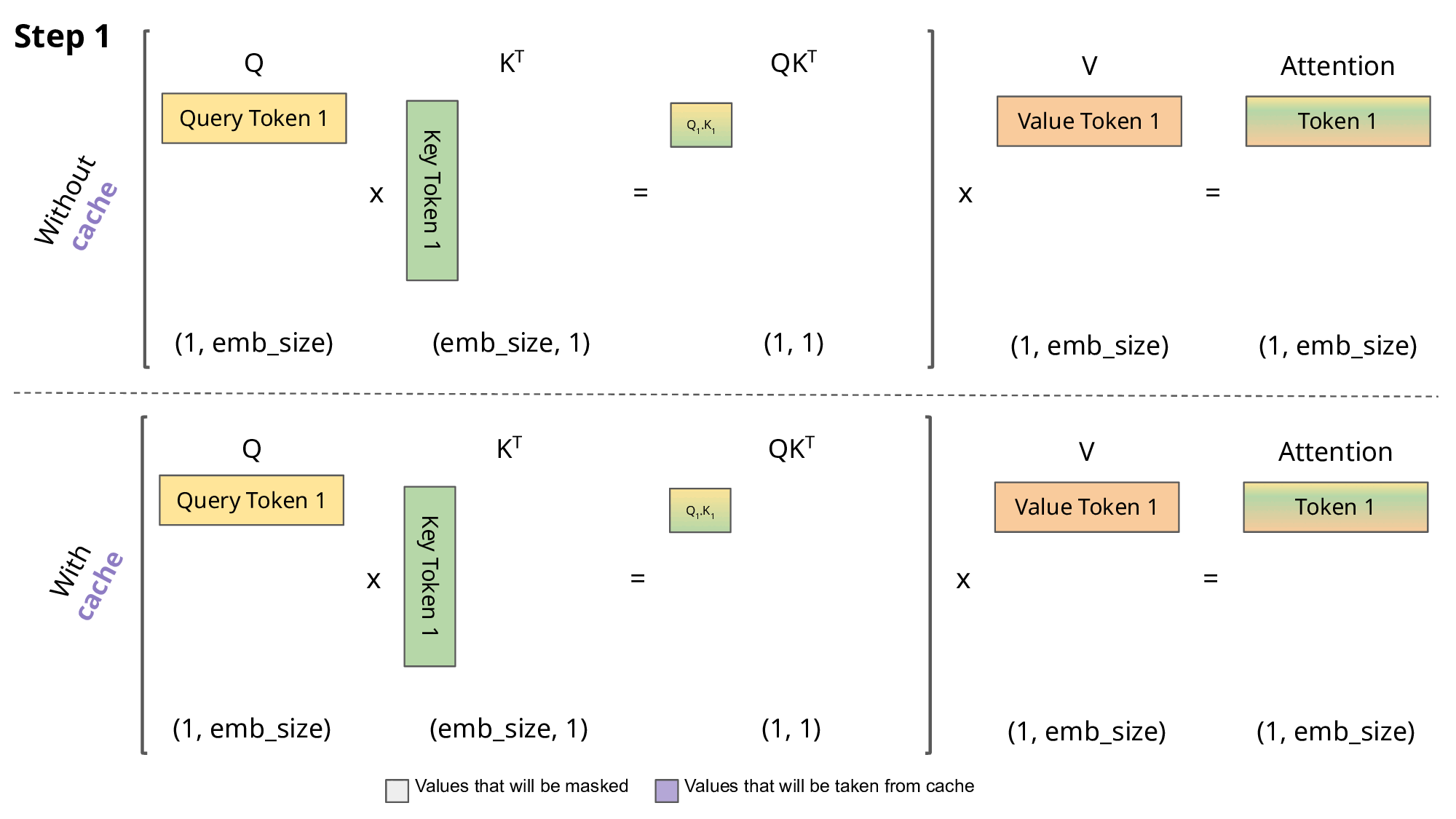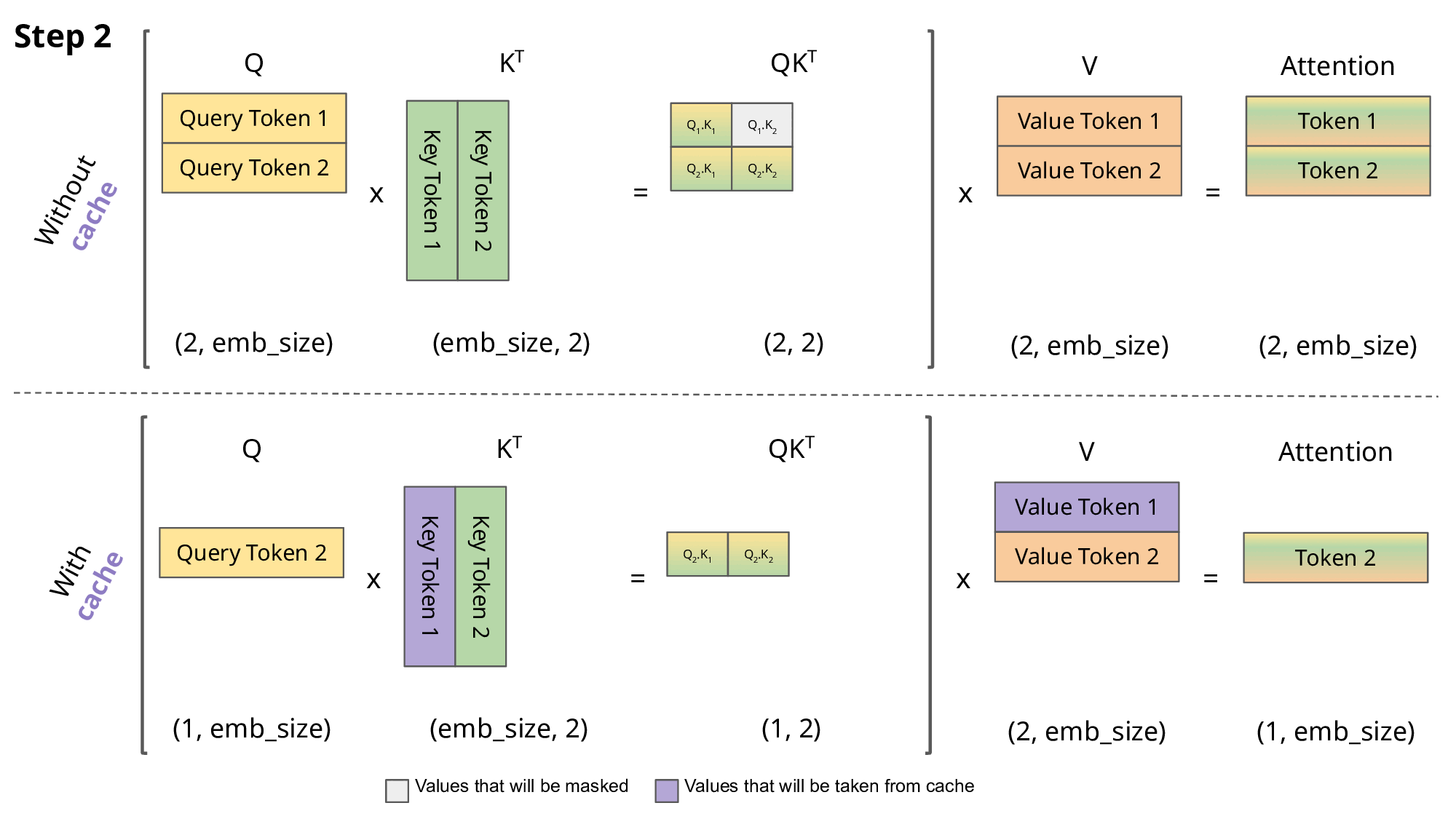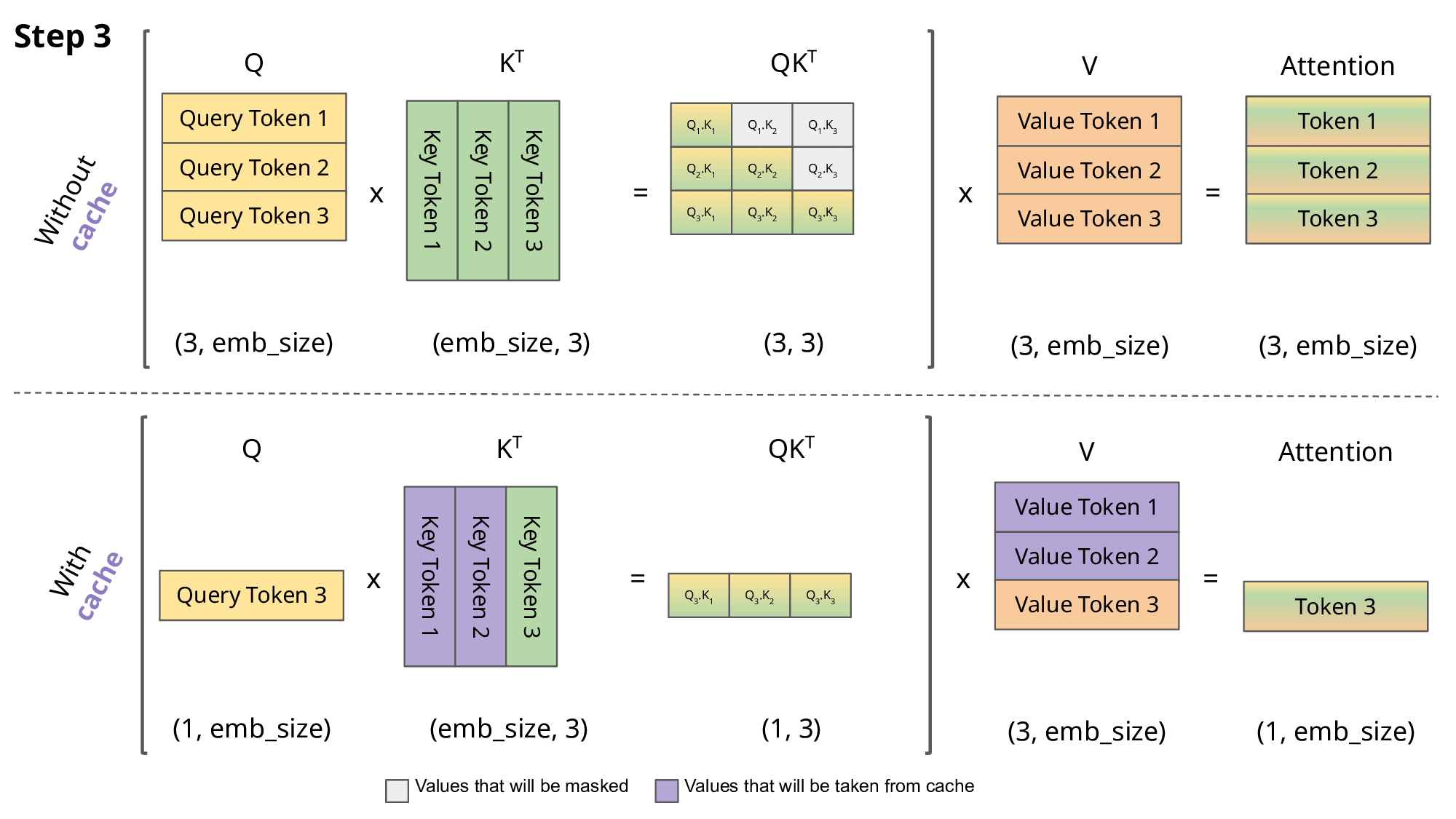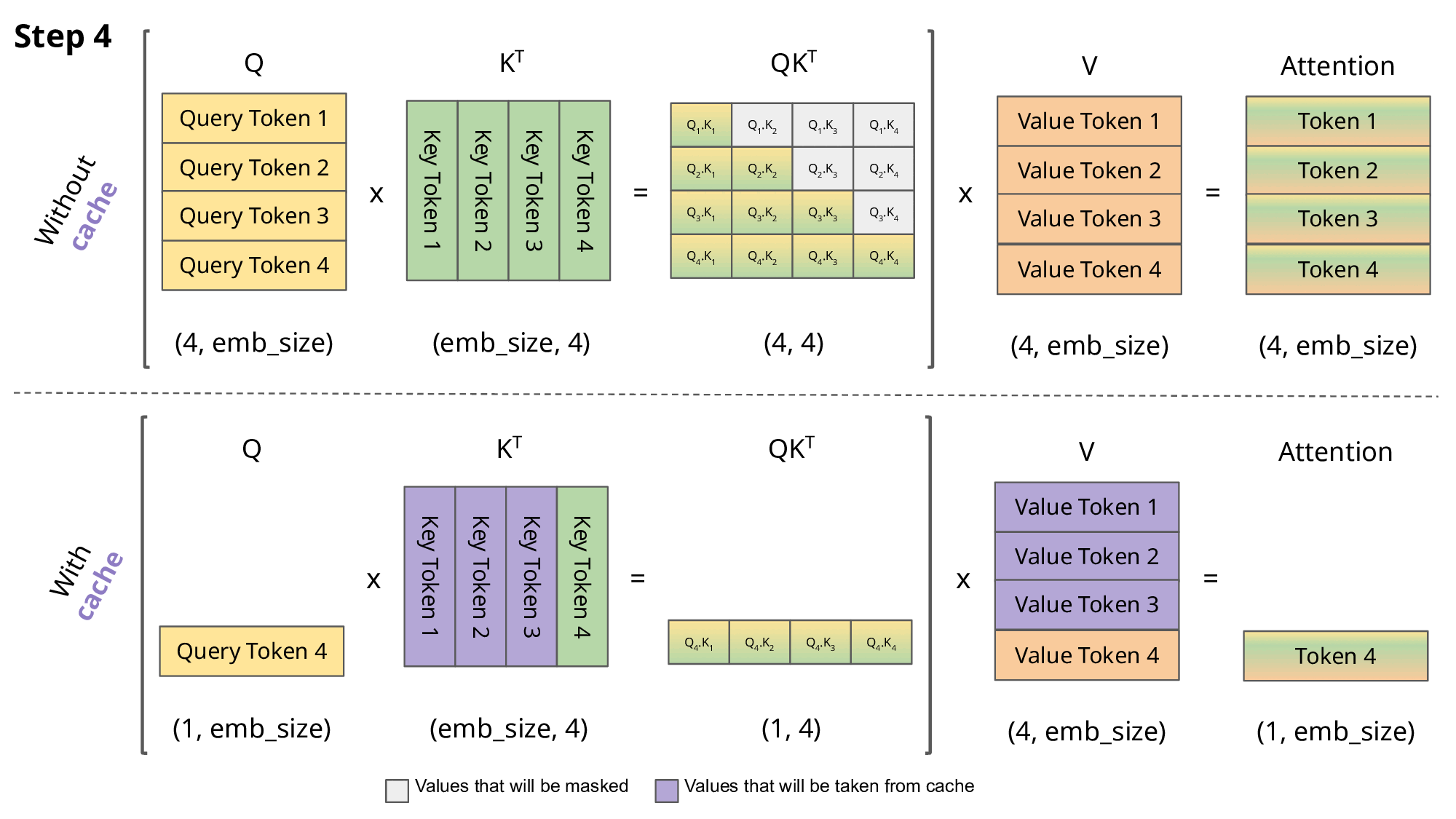
3. Continuous / Dynamic Batching
- Don't wait for fixed batch size.
- Add new requests mid-generation → process many users together → read weights once, use on many prompts.
- vLLM / TGI do this automatically → 5–10× throughput jump.

4. Speculative Decoding
- Small "draft" model guesses 4–8 tokens ahead super fast.
- Big model verifies in parallel (one forward pass checks all).
- If correct → free speedup (2–3× tokens/sec).
- 2026 common: Medusa, Lookahead, or Eagle spec decoders on top of Llama/Mistral.
The Process:

Example: Indian startups / enterprises (Zomato, Swiggy, Paytm-like scale) → Serve Llama-4-70B or Mistral-3 with vLLM + 4-bit AWQ on RunPod/Nebius A100s. → Before: 2–3 concurrent users per GPU. → After PagedAttention + continuous batching: 20–50+ concurrent. → Cost drop: ~4–10× cheaper per query.
Chapter 10: Architecture & User Feedback – The Long Game
In 2026, no serious AI system is static. The winners build data flywheels — user interactions create better data → better data improves the model/RAG/prompts → better outputs → more users → more data → loop forever. This is how DoorDash, LinkedIn, Notion, and Indian unicorns (Zomato, Groww, Cred) keep their AI ahead.
Core Concepts –
A) The Data Flywheel
Every time a user interacts, you collect signals
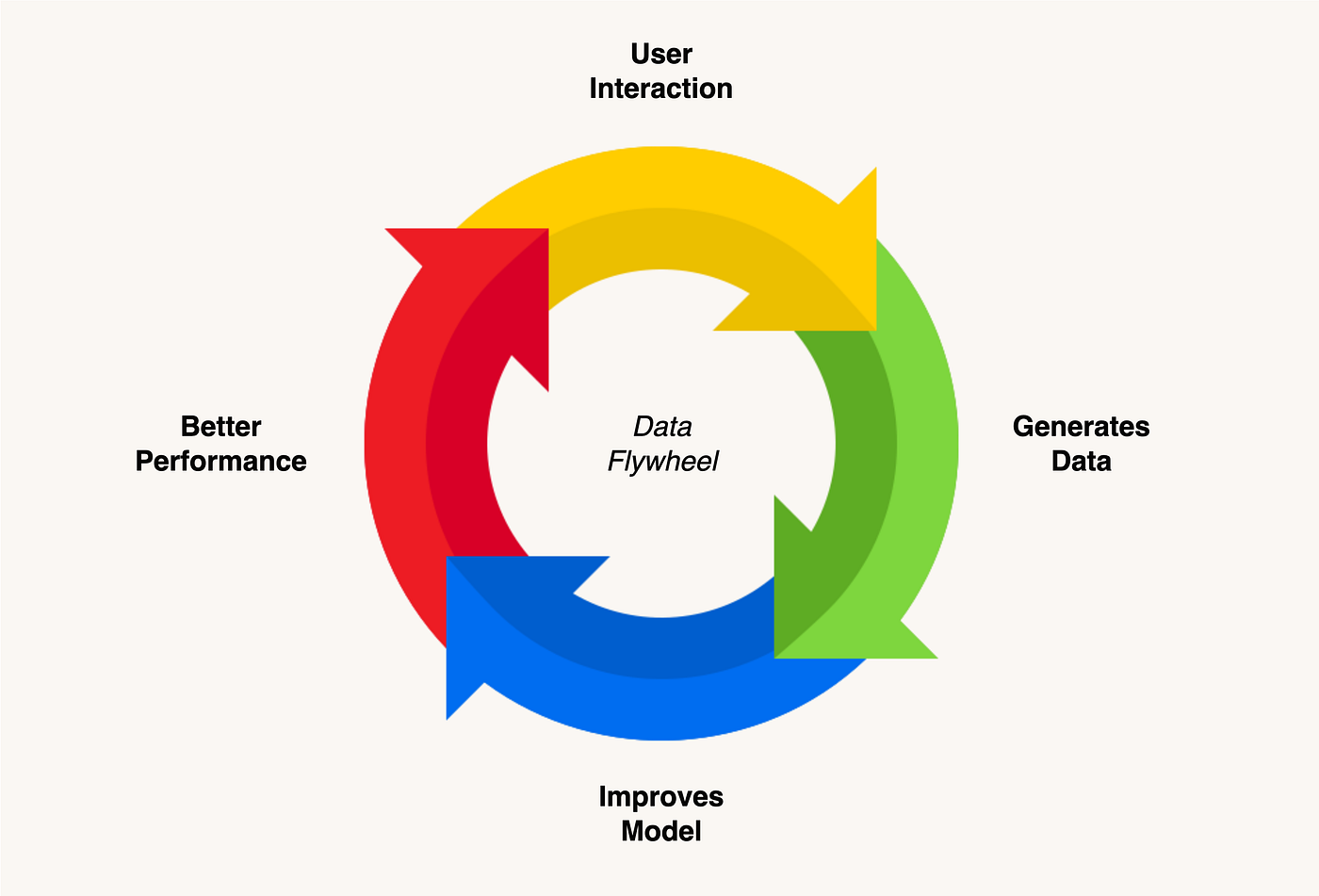
a. Implicit feedback — Did they copy the answer? Edit it? Regenerate? Abandon the chat? Stay longer?
b. Explicit feedback — Thumbs up/down, rating 1–5, "this was helpful" button. → Save good/bad examples → build "golden dataset" → use for:
- Evaluating new model versions
- Finetuning adapters
- Improving RAG retrieval (better chunking, reranking)
- Refining prompts
B) Gateway / Router Pattern
Never connect your app directly to one LLM API. Put a smart middle layer (gateway/router) that:Router architecture overview (query → classifier → route to different models/providers → combine response):Multi-model routing with cost/latency trade-offs (simple queries to fast/cheap, complex to reasoning-heavy):
- Classifies query difficulty (simple vs complex reasoning)
- Routes: easy → cheap/fast model (DeepSeek V3, Mistral 3, Llama-4-8B), hard → expensive/smart (Claude 4.6 Opus, Gemini 3.1 Pro)
- Fallback: If one provider is down/slow/expensive → switch automatically
- Rate-limit per user/company → prevent budget blow-up
- Log everything for later analysis
Book download link: https://oceanofpdf.com/genres/technical/pdf-epub-ai-engineering-building-applications-with-foundation-models-download/
