[Day 11] Supervised Machine Learning Type 2 - Logistic Regression (with a Small Python Project)
Can AI predict if a patient has diabetes? With Logistic Regression, it can. Dive into one of ML’s simplest and smartest tools for classification.
![[Day 11] Supervised Machine Learning Type 2 - Logistic Regression (with a Small Python Project)](https://storage.ghost.io/c/55/e8/55e827ca-bf8d-4eee-bdb4-ee48e49a011a/content/images/size/w2000/2025/03/_--visual-selection--11-.svg)
What is Logistic Regression?
Logistic Regression is a widely used supervised learning algorithm for predicting categorical outcomes (often binary). It is used to model the probability of a particular class or event occurring. Unlike Linear Regression, which predicts continuous values, Logistic Regression predicts the probability that a given input belongs to a particular class.
The output of Logistic Regression is a probability that lies between 0 and 1, which is transformed into binary class predictions based on a threshold (usually 0.5).
Use Cases:
- Predicting whether an email is spam or not.
- Classifying whether a customer will buy a product or not (1 for yes, 0 for no).
- Diagnosing diseases based on patient features.
The answer would be either ‘Yes’ or ‘No’ See the graph below
Videos you must see to understand it more:
How Does Logistic Regression Work?
Logistic Function (Sigmoid Curve):
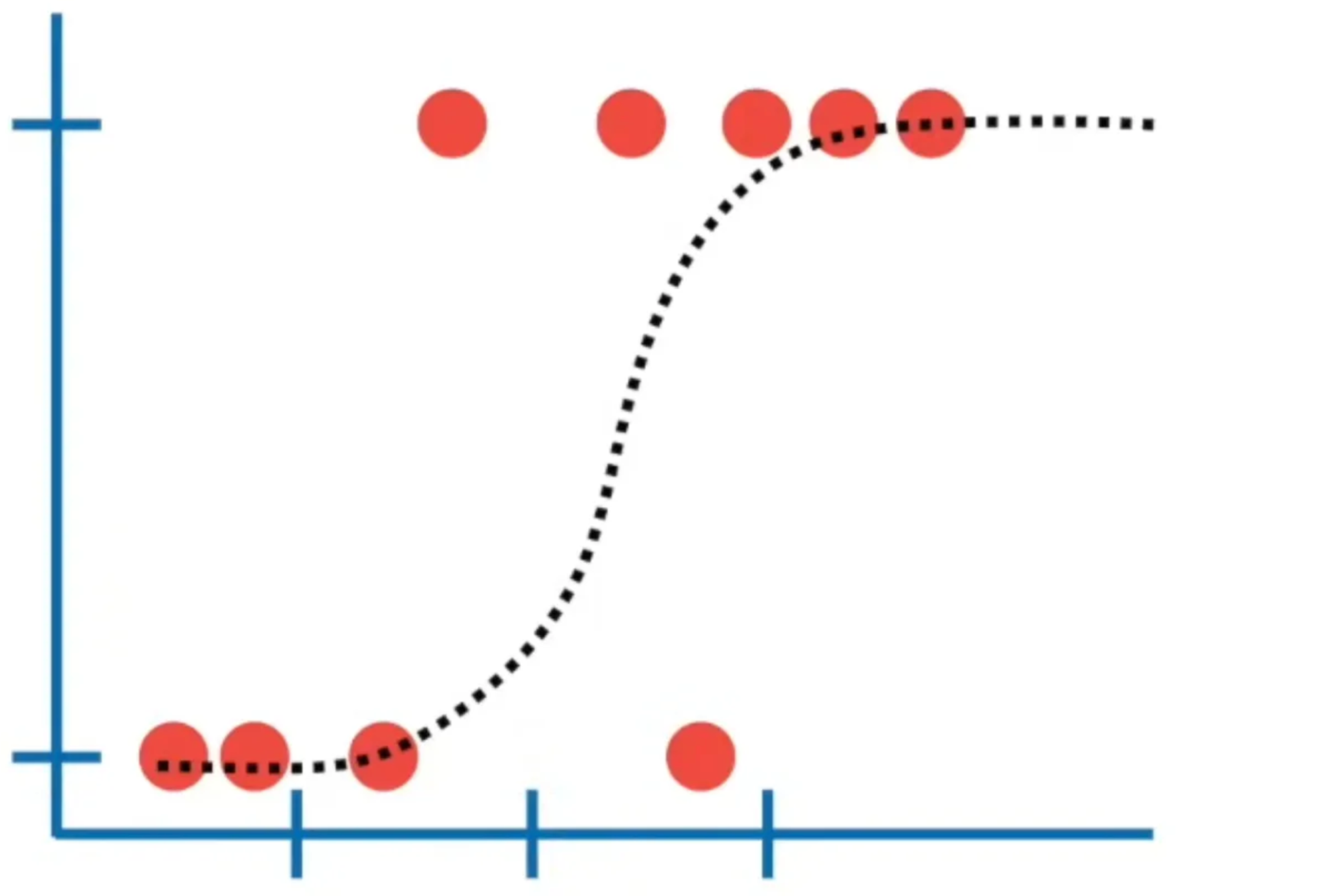
Sigmoid Function:
p = 1 / (1 + e^(-z))
Where:
p: Probability of the target class being 1.z: Linear combination of input features.
Logistic Regression Equation (Single Feature):
p = 1 / (1 + e^(-(w0 + w1 * x)))
Where:
p: Probability of the target class being 1.x: Input feature.w0: Intercept (bias term).w1: Weight (coefficient) for the feature.
Advantages of Logistic Regression:
- Simple and interpretable: It's easy to understand how the model works.
- Computationally efficient: It can be applied to large datasets.
- Works well with linearly separable data.
Limitations of Logistic Regression:
- Non-linear relationships: Logistic Regression struggles when the relationship between features and the target variable is non-linear.
- Sensitive to outliers: It is affected by outliers in the dataset, which can distort predictions.
- Assumes a linear decision boundary: It may not perform well if the data cannot be separated linearly.
Real-world use cases:
1. Medical Diagnosis (e.g., Predicting Disease Outcome)
- Problem: Logistic Regression can be used to predict whether a patient is likely to have a particular disease (e.g., diabetes, cancer) based on their medical history and health metrics (e.g., blood pressure, age, BMI).
- Example: Predicting whether a patient has diabetes or not based on features like glucose level, BMI, age, and insulin resistance.
- Why Logistic Regression: The outcome is binary (disease vs. no disease), and the relationship between the features and the outcome is often linear or approximately linear, making Logistic Regression a good choice.
Practical Example:
- A healthcare provider can use Logistic Regression to predict whether a patient will develop heart disease based on factors like cholesterol levels, smoking habits, age, and exercise routine.
2. Email Spam Detection
- Problem: Logistic Regression can classify emails as either spam or non-spam (ham) based on certain features (e.g., words, frequency of specific keywords).
- Example: An email service like Gmail or Outlook uses Logistic Regression to identify spam emails and filter them out.
- Why Logistic Regression: The model works well for binary classification problems (spam or not spam) and can efficiently handle textual data when combined with techniques like TF-IDF or bag of words.
Practical Example:
- Email providers analyze text features such as frequency of certain words (like "win", "free", etc.) to classify emails. Logistic Regression helps to classify new incoming emails as spam based on this training data.
3. Customer Churn Prediction
- Problem: Companies, particularly in telecommunications and subscription services, use Logistic Regression to predict whether a customer is likely to churn (i.e., cancel a subscription or stop using the service).
- Example: A telecom company can predict whether a customer will leave based on features like usage patterns, payment history, and customer service interactions.
- Why Logistic Regression: The outcome is binary (churn or not churn), and it allows companies to proactively offer retention strategies for customers who are likely to leave.
Practical Example:
- A subscription service like Netflix or a telecom provider uses Logistic Regression to predict customer churn based on features like average viewing time, payment failures, and customer service issues.
4. Credit Scoring (Loan Approval)
- Problem: Financial institutions use Logistic Regression to predict the likelihood of a loan applicant defaulting on their loan based on features like credit score, income, employment status, and loan amount.
- Example: Banks can use Logistic Regression to decide whether to approve a loan application or not.
- Why Logistic Regression: It is a binary classification problem (approve or deny), and the relationships between financial indicators and the likelihood of default are often linear.
Practical Example:
- A bank can predict whether a person is likely to default on a loan by analyzing their credit score, employment history, and past financial behavior.
5. Marketing Campaign Effectiveness
- Problem: Logistic Regression can help companies determine the likelihood that a customer will respond positively to a marketing campaign, such as purchasing a product or subscribing to a service, based on features like previous purchase behavior, demographics, and response to past campaigns.
- Example: An e-commerce company can use Logistic Regression to predict whether a customer will click on a promotional email or whether they will make a purchase after viewing an ad.
- Why Logistic Regression: The outcome is binary (response/no response), and the model works well with marketing features such as past purchases, email click-through rates, and demographic data.
Practical Example:
- An online retailer might use Logistic Regression to predict whether a customer is likely to click on a promotional email based on past behavior such as purchase history, site visits, and email engagement.
Quick Python Project
A Python project using Logistic Regression to predict whether a person has diabetes based on certain health features.
Data Set:
| Pregnancies | Glucose | BloodPressure | SkinThickness | Insulin | BMI | DiabetesPedigreeFunction | Age | Outcome |
|---|---|---|---|---|---|---|---|---|
| 6 | 148 | 72 | 35 | 0 | 33.6 | 0.627 | 50 | 1 |
| 1 | 85 | 66 | 29 | 0 | 26.6 | 0.351 | 31 | 0 |
| 8 | 183 | 64 | 0 | 0 | 23.3 | 0.672 | 32 | 1 |
| 1 | 89 | 66 | 23 | 94 | 28.1 | 0.167 | 21 | 0 |
| 0 | 137 | 40 | 35 | 168 | 43.1 | 2.288 | 33 | 1 |
| 5 | 116 | 74 | 0 | 0 | 25.6 | 0.201 | 30 | 0 |
| 3 | 78 | 50 | 32 | 88 | 28.3 | 0.168 | 26 | 0 |
| 10 | 115 | 75 | 25 | 0 | 31.7 | 0.472 | 34 | 1 |
| 7 | 109 | 64 | 23 | 132 | 34.9 | 0.261 | 38 | 1 |
| 4 | 140 | 70 | 34 | 0 | 35.6 | 0.451 | 45 | 1 |
Save this data as diabetes.csv
Solution:
import pandas as pd
from sklearn.linear_model import LogisticRegression
# Load the dataset (Ensure 'diabetes.csv' is in the current directory)
df = pd.read_csv('diabetes.csv')
# Separate the features and the target variable
X = df.drop('Outcome', axis=1) # Features (input variables)
y = df['Outcome'] # Target variable (1 for diabetes, 0 for no diabetes)
# Initialize the Logistic Regression model
model = LogisticRegression(max_iter=200)
# Train the model using the dataset
model.fit(X, y)
# Example of predicting the outcome for a new input (for a new patient)
new_data = pd.DataFrame({
'Pregnancies': [1],
'Glucose': [90],
'BloodPressure': [70],
'SkinThickness': [25],
'Insulin': [0],
'BMI': [30.5],
'DiabetesPedigreeFunction': [0.201],
'Age': [29]
})
# Make a prediction for the new data
prediction = model.predict(new_data)
# Output the predicted class (0: No Diabetes, 1: Diabetes)
print("Prediction (0: No Diabetes, 1: Diabetes):", prediction[0])
Let’s make predictions:
1- Sample Input:
If the new data is:
Pregnancies: 1
Glucose: 90
BloodPressure: 70
SkinThickness: 25
Insulin: 0
BMI: 30.5
DiabetesPedigreeFunction: 0.201
Age: 29
Sample Output:
Prediction (0: No Diabetes, 1: Diabetes): 0
This means the model predicts the patient does not have diabetes based on the input features.
2- Sample Input:
If the new data is:
{
'Pregnancies': [1],
'Glucose': [90],
'BloodPressure': [70],
'SkinThickness': [25],
'Insulin': [0],
'BMI': [30.5],
'DiabetesPedigreeFunction': [0.201],
'Age': [29]
}
The prediction is:
Prediction (0: No Diabetes, 1: Diabetes): 0
Note: This example demonstrates how you can simulate a larger dataset, train a logistic regression model, and use it for predictions. You can continue expanding this dataset with more rows to improve the model’s generalizability. Let me know if you'd like further modifications or another example!
Here’s a step-by-step explanation of the code:
1. Import Required Libraries
import pandas as pd
from sklearn.linear_model import LogisticRegression
pandas: Used for data manipulation and creating DataFrames (structured data tables).LogisticRegression: A machine learning algorithm from scikit-learn for classification tasks.
2. Load the Dataset
df = pd.read_csv('diabetes.csv')
- This assumes the dataset (
diabetes.csv) is in the current directory. pd.read_csvreads the file and loads it as a DataFrame into the variabledf.
Dataset Example: The dataset contains information about patients, with features like Glucose, BMI, etc., and a target variable Outcome indicating diabetes (1) or no diabetes (0).
3. Separate Features and Target Variable
X = df.drop('Outcome', axis=1) # Features (input variables)
y = df['Outcome'] # Target variable (1 for diabetes, 0 for no diabetes)
Xcontains the independent variables (features) likePregnancies,Glucose, etc., used to predict the outcome.yis the dependent variable (Outcome) we are trying to predict:1for diabetes.0for no diabetes.
4. Initialize the Logistic Regression Model
model = LogisticRegression(max_iter=200)
LogisticRegression: Used for binary classification (two categories: diabetes/no diabetes).max_iter=200: Sets the maximum number of iterations for the optimization algorithm to converge.
5. Train the Model
model.fit(X, y)
- The
.fit()method trains the model on the dataset. - The logistic regression model learns the relationship between features (
X) and the target variable (y) during this step.
6. Prepare New Data for Prediction
new_data = pd.DataFrame({
'Pregnancies': [1],
'Glucose': [90],
'BloodPressure': [70],
'SkinThickness': [25],
'Insulin': [0],
'BMI': [30.5],
'DiabetesPedigreeFunction': [0.201],
'Age': [29]
})
- This is a new patient's data we want to predict for:
- The values correspond to the features in the dataset (e.g.,
Pregnancies,Glucose, etc.).
- The values correspond to the features in the dataset (e.g.,
- The data is passed as a dictionary and converted to a DataFrame using
pd.DataFrame.
7. Make a Prediction
prediction = model.predict(new_data)
model.predict()uses the trained model to predict the outcome for thenew_data.- Returns
1(diabetes) or0(no diabetes).
8. Output the Prediction
print("Prediction (0: No Diabetes, 1: Diabetes):", prediction[0])
- The prediction is printed:
0: Indicates no diabetes.1: Indicates diabetes.
Key Points
- Logistic Regression is a supervised learning algorithm used for binary classification.
- The dataset must have the same structure during training and prediction.
- Input values (features) for prediction should match the trained model's features.
💬 Join the DecodeAI WhatsApp Channel for regular AI updates → Click here