Google’s Nested Learning: The Breakthrough That Fixes AI’s Biggest Flaw
The 2016 Paper That Changed AI Forever: In 2016, Google researchers published a landmark paper introducing the Transformer architecture — the foundation of today’s most powerful AIs, including GPT, Gemini, Claude, and every major LLM.
It unlocked something the world had never seen before:
- Machines that can understand language
- Generate human-level text
- Pass tough exams
- And process massive knowledge instantly
That single innovation triggered the modern AI revolution.
❌ But There’s a Problem We Overlooked
For all their intelligence, these models have a hidden disability: They don’t learn anything new after training.
Once trained for months using gigantic GPUs, LLMs become static:
✔ They can use knowledge
✘ But can’t update it on their own
✘ They can’t permanently remember new facts
✘ They can’t continuously improve from interactions
✘ They can’t adapt without retraining the whole model
Researchers call this issue:
AI anterograde amnesia — the inability to form new long-term memories.
And bolting on more parameters doesn’t fix it.
We created geniuses who forget every new lesson as soon as the conversation ends.
Enter Google’s Solution: Nested Learning
This is where Google’s latest research, Nested Learning (NL), comes in.
NL proposes a new AI architecture built to:
- Learn constantly
- Update internal knowledge in real-time
- Consolidate important information over long periods
- Become truly self-improving
In short: AI that doesn’t stay stuck in the past.
Official link: Introducing Nested Learning: A new ML paradigm for continual learning
The core idea of this research on Nested Learning (NL) is to fix a major flaw in today's smartest AI systems, like the large language models (LLMs) that power sophisticated chatbots.
Here is a simplified explanation of the problem, the solution, and the resulting new AI architecture.
1. The Problem: Static Genius and AI Amnesia
We have created incredibly intelligent AI using deep learning, which essentially means stacking many computational layers to give the model huge knowledge capacity.
However, once these large models are fully trained (a process that takes months and massive computing power), they become static.
- The Analogy of Amnesia: The paper compares this static nature to anterograde amnesia. The AI’s mind is divided: it remembers everything from the "long past" (the initial training data stored in its core memory layers, or FFNs) and it can process information in the "immediate present" (the chat session context, or short-term memory).
- The Critical Flaw: The information you provide the AI in a new conversation never permanently changes its core, long-term memory parameters. It can’t truly "learn" new skills or knowledge continuously over time; it can only quickly adapt to the immediate context (in-context learning). Stacking more layers in the old way doesn't solve this fundamental inability to continually learn or self-improve.
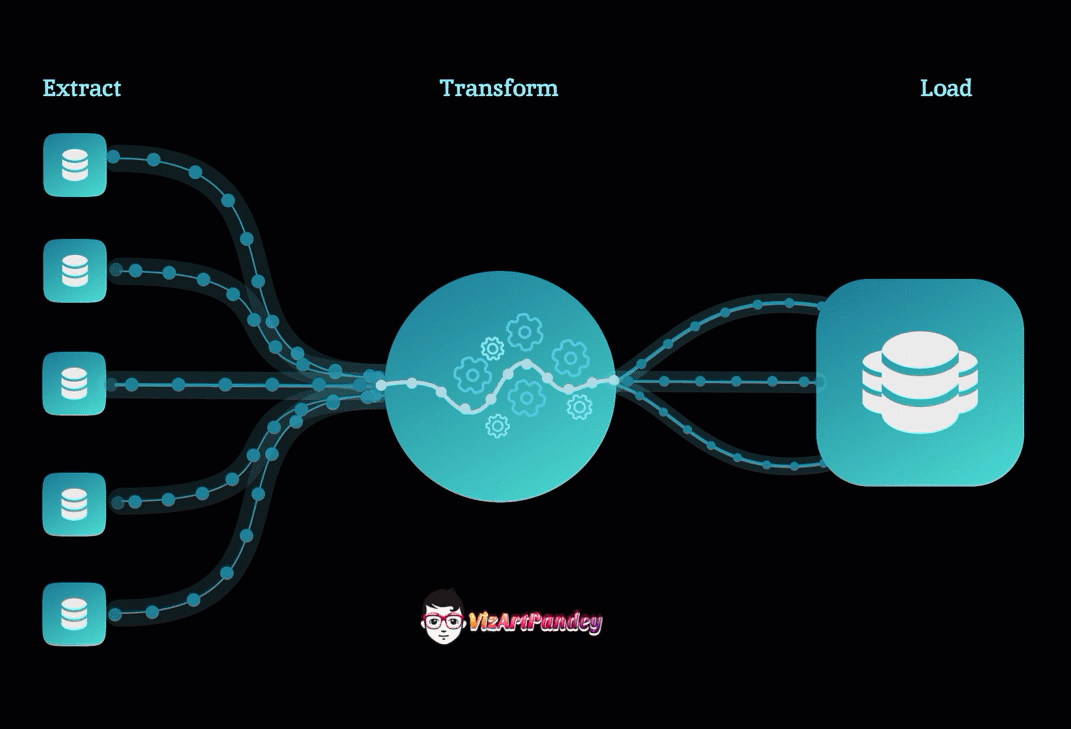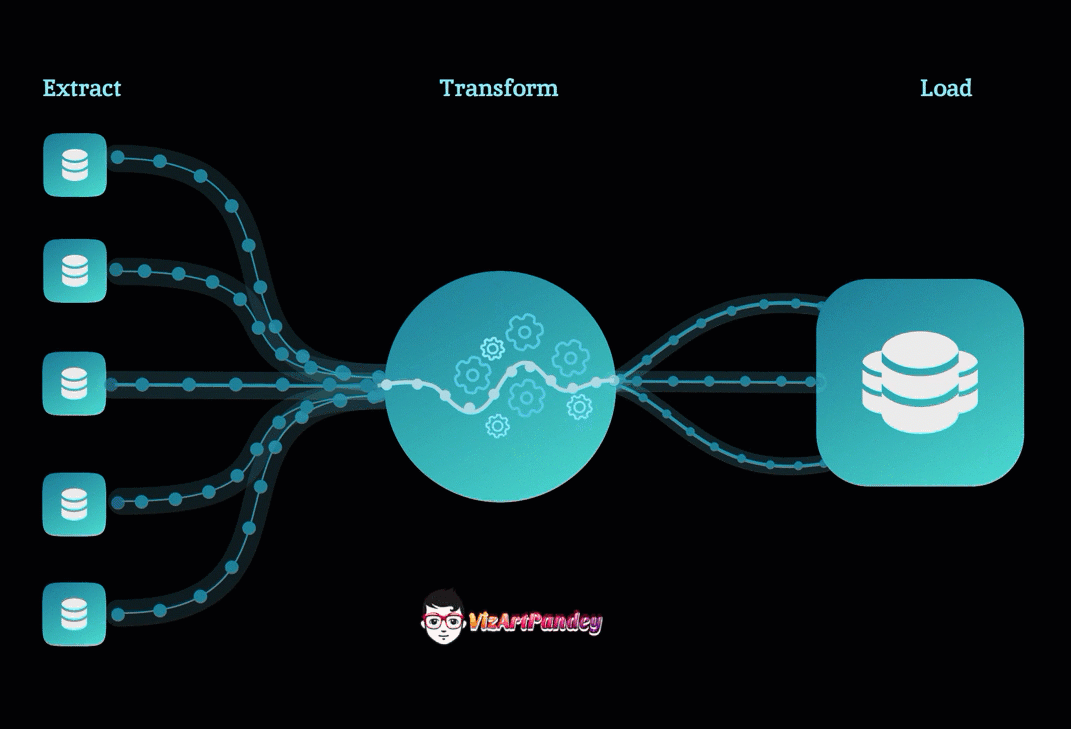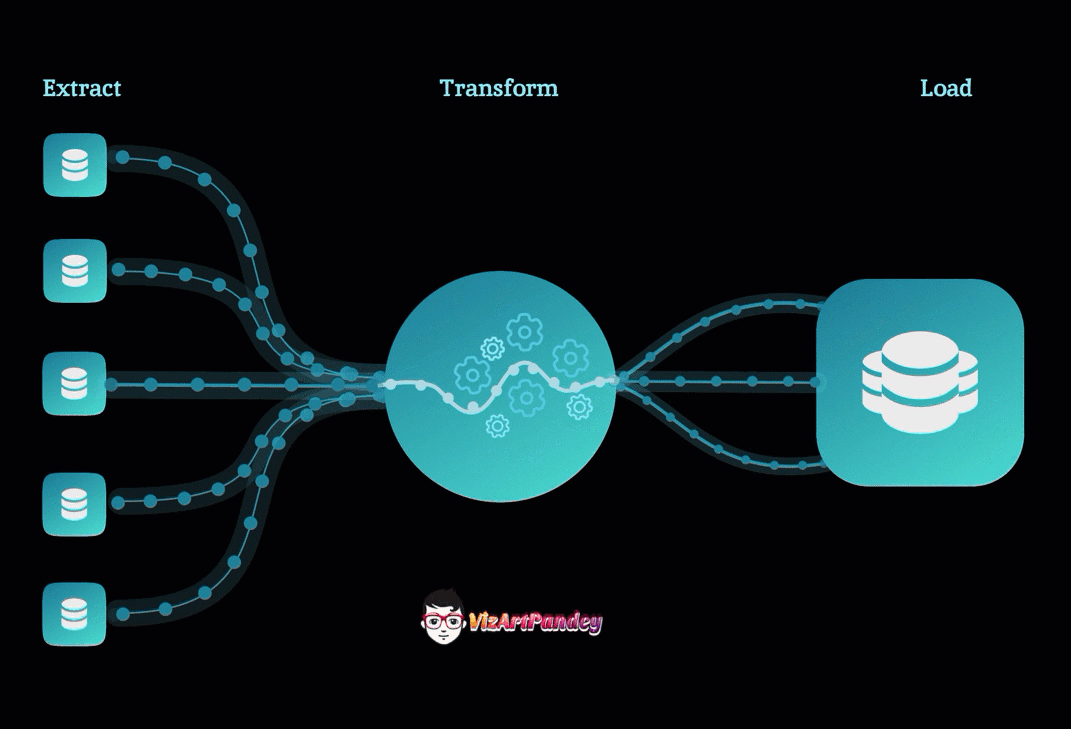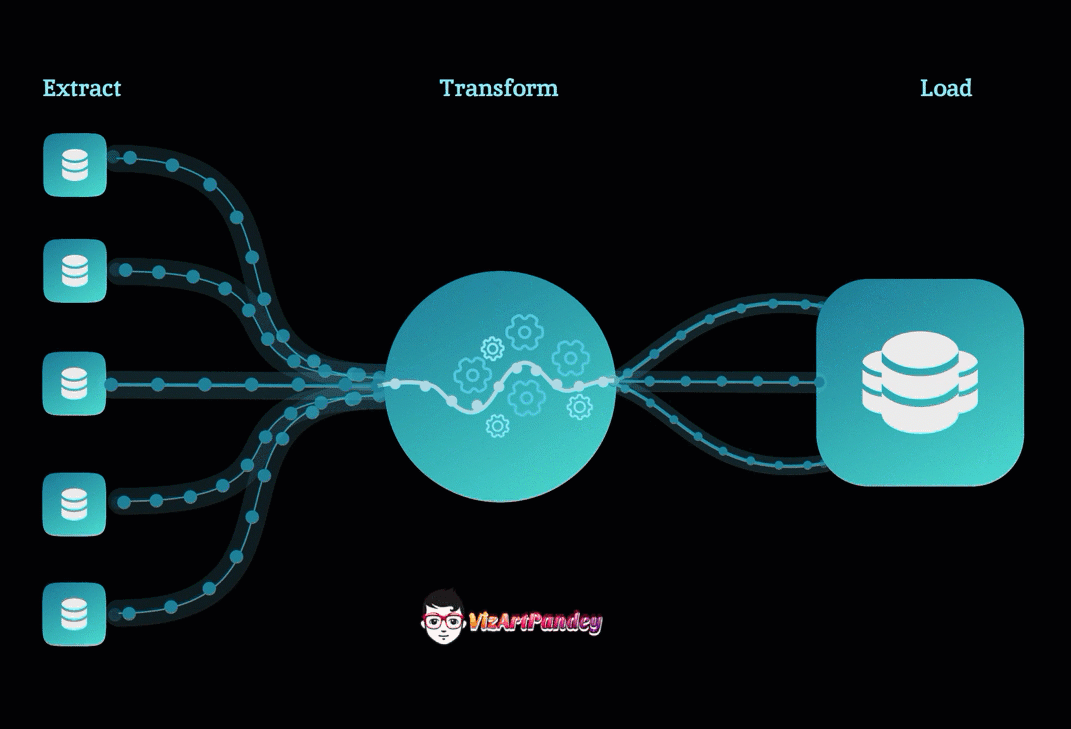
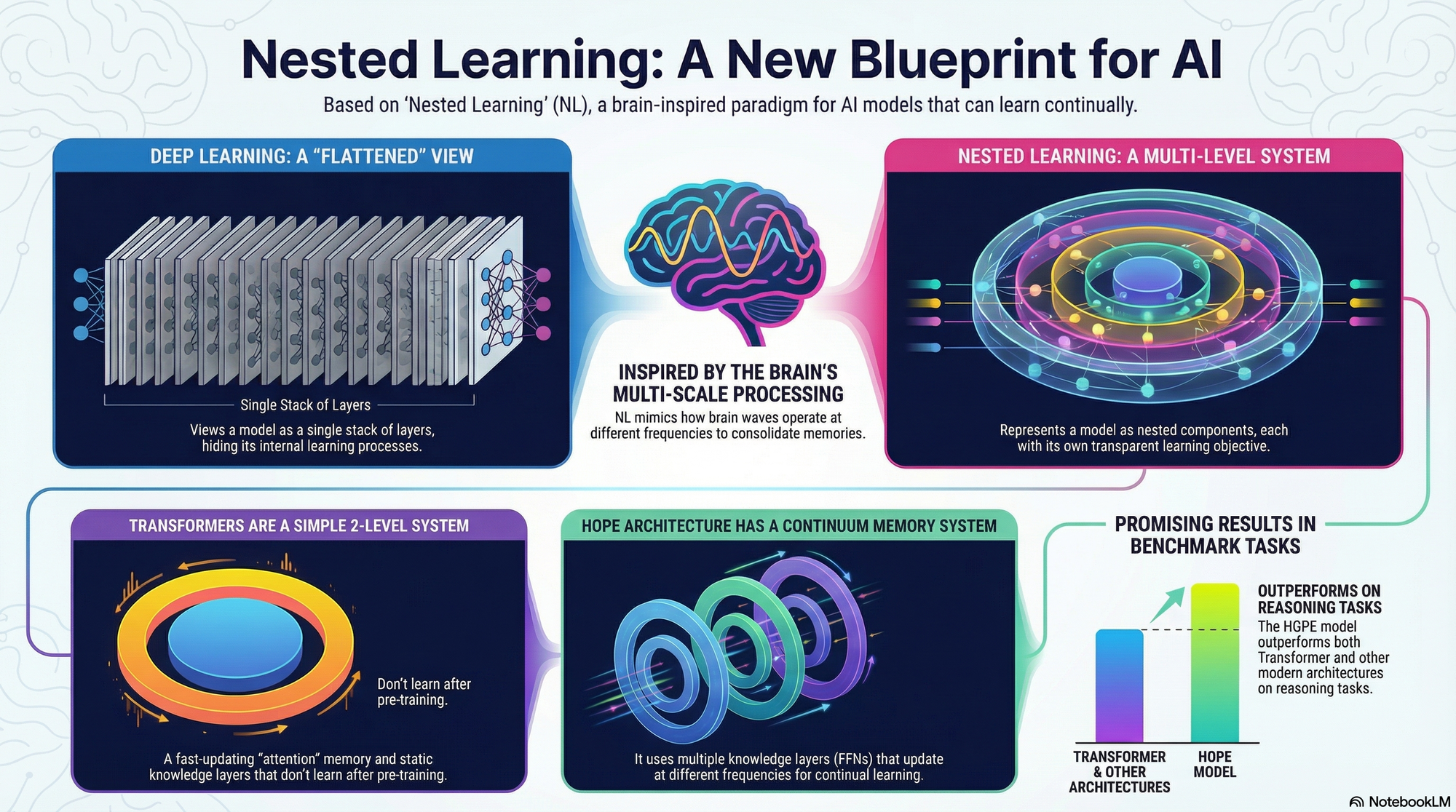
2. The Solution: Nested Learning (NL)
Nested Learning proposes a new blueprint for building AI that overcomes this amnesia by making the internal learning process more transparent and flexible.
Instead of thinking of the AI as one giant, flat processing tower (the traditional deep learning view), NL treats the AI as a collection of separate, integrated learning systems working together.
The Core Principle: Multi-Speed Learning
NL takes inspiration from the human brain's ability to constantly change and reorganize itself (neuroplasticity). Our brains manage information using different "speeds" or frequencies—some thoughts are fast and immediate (like Gamma waves), while others consolidate slowly over days or weeks (like Delta waves).
NL applies this concept by organizing the AI’s internal components (its parameters) into "levels" based on how frequently they are allowed to update.
- Higher Level = Slower Update: The highest-level components update very slowly, integrating highly abstract knowledge over long periods, similar to long-term memory consolidation.
- Lower Level = Faster Update: The lowest-level components update quickly, dealing with the rapid flow of data in the moment.
This system creates a more expressive architecture because the model can process data across these different time scales simultaneously.
3. The New Tools NL Provides
NL provides three key innovations to build these multi-speed, self-improving systems:
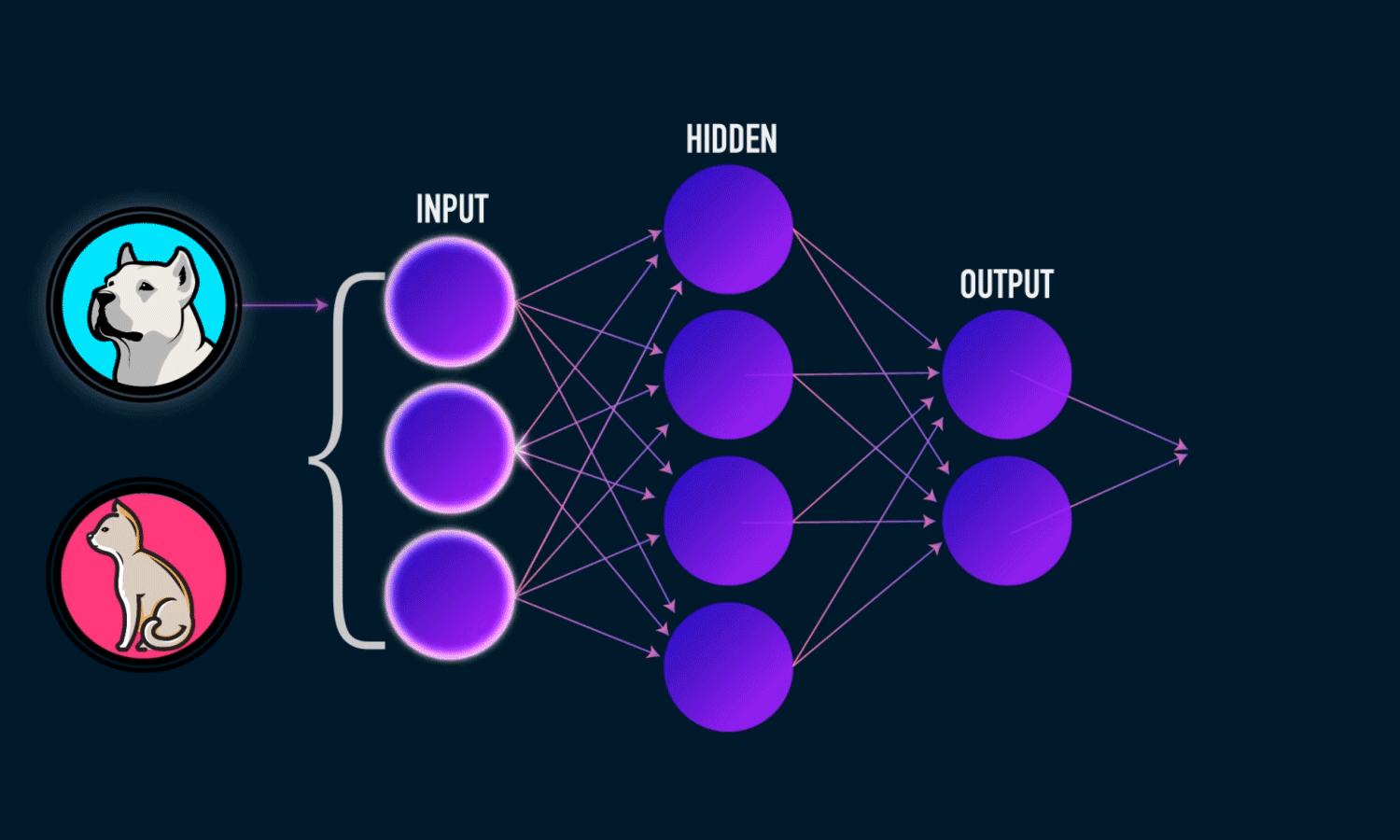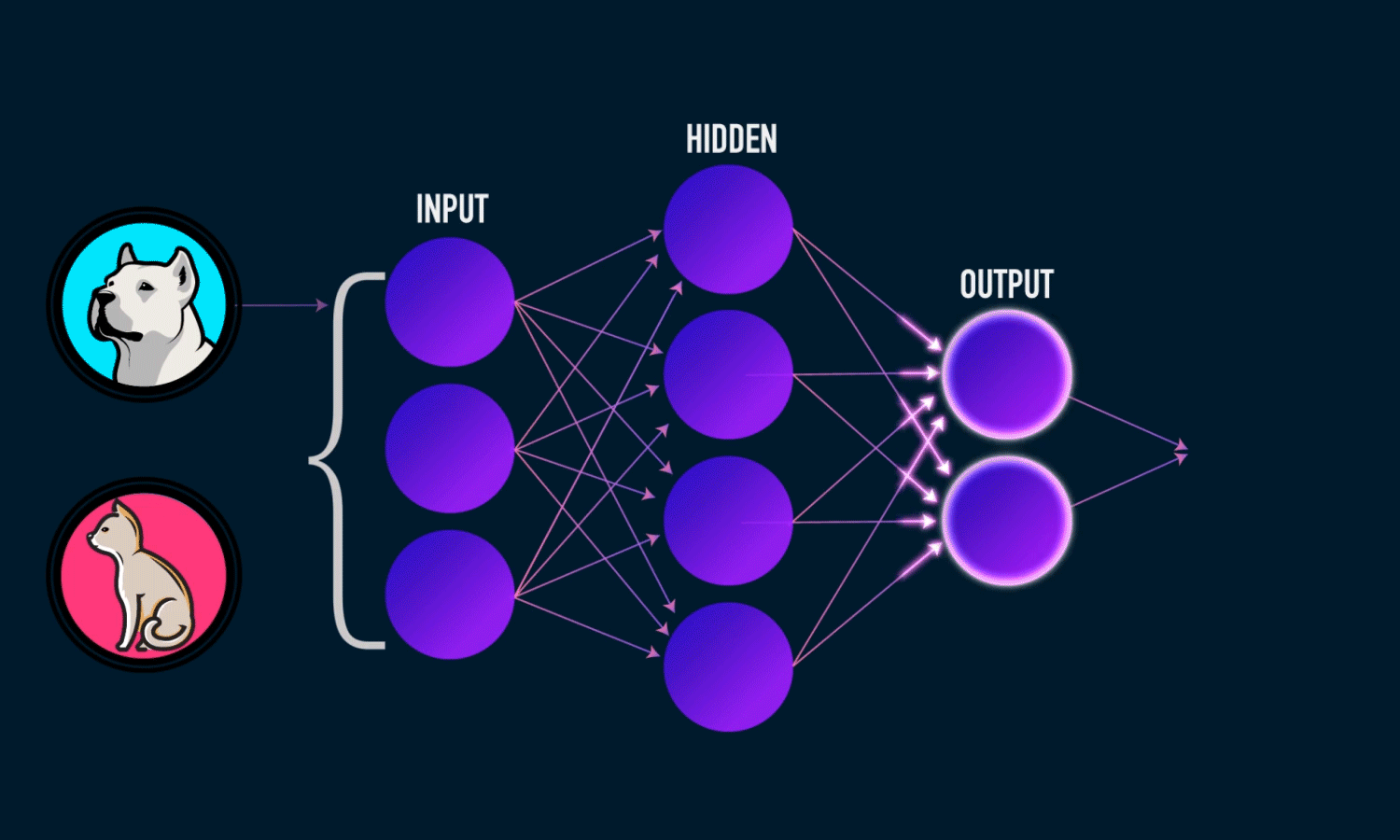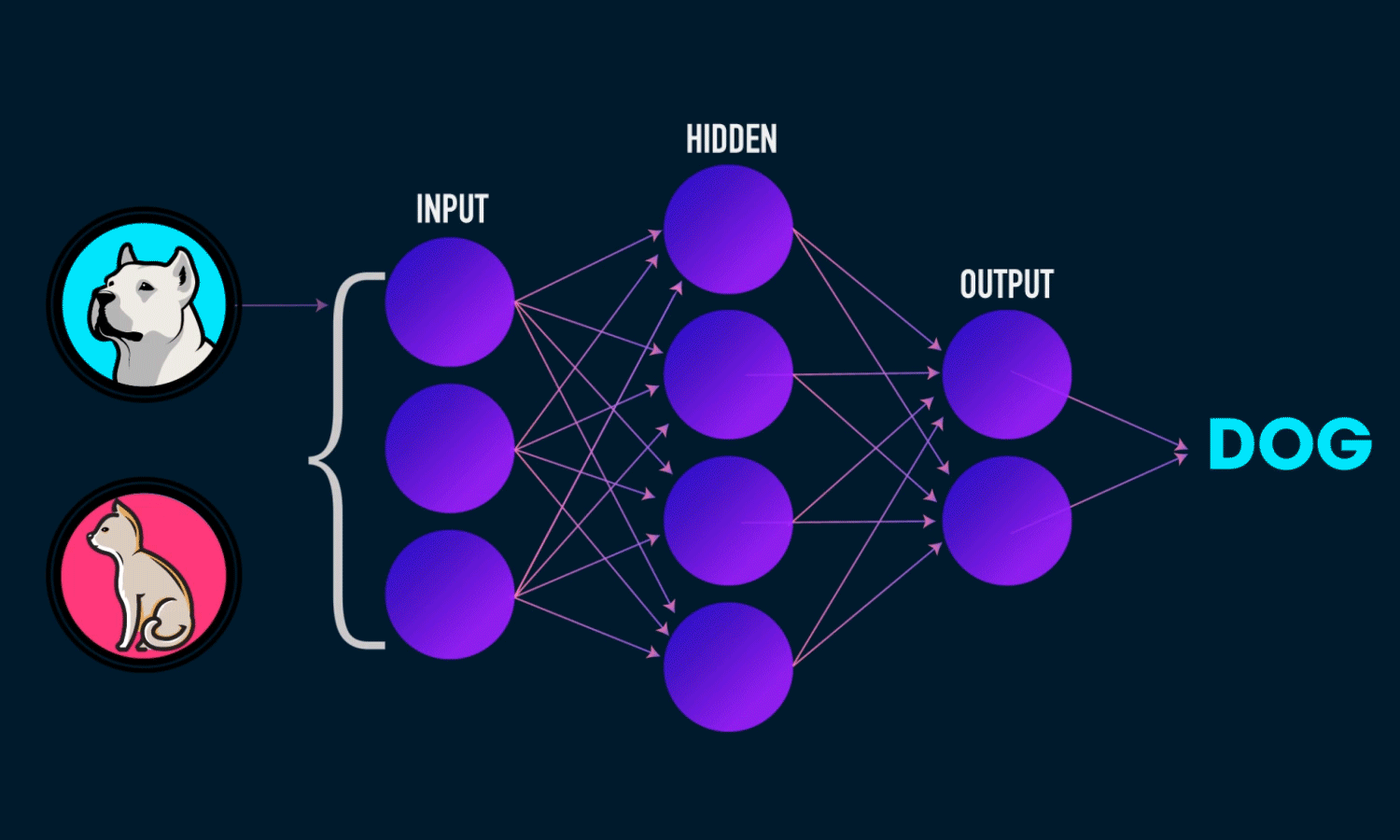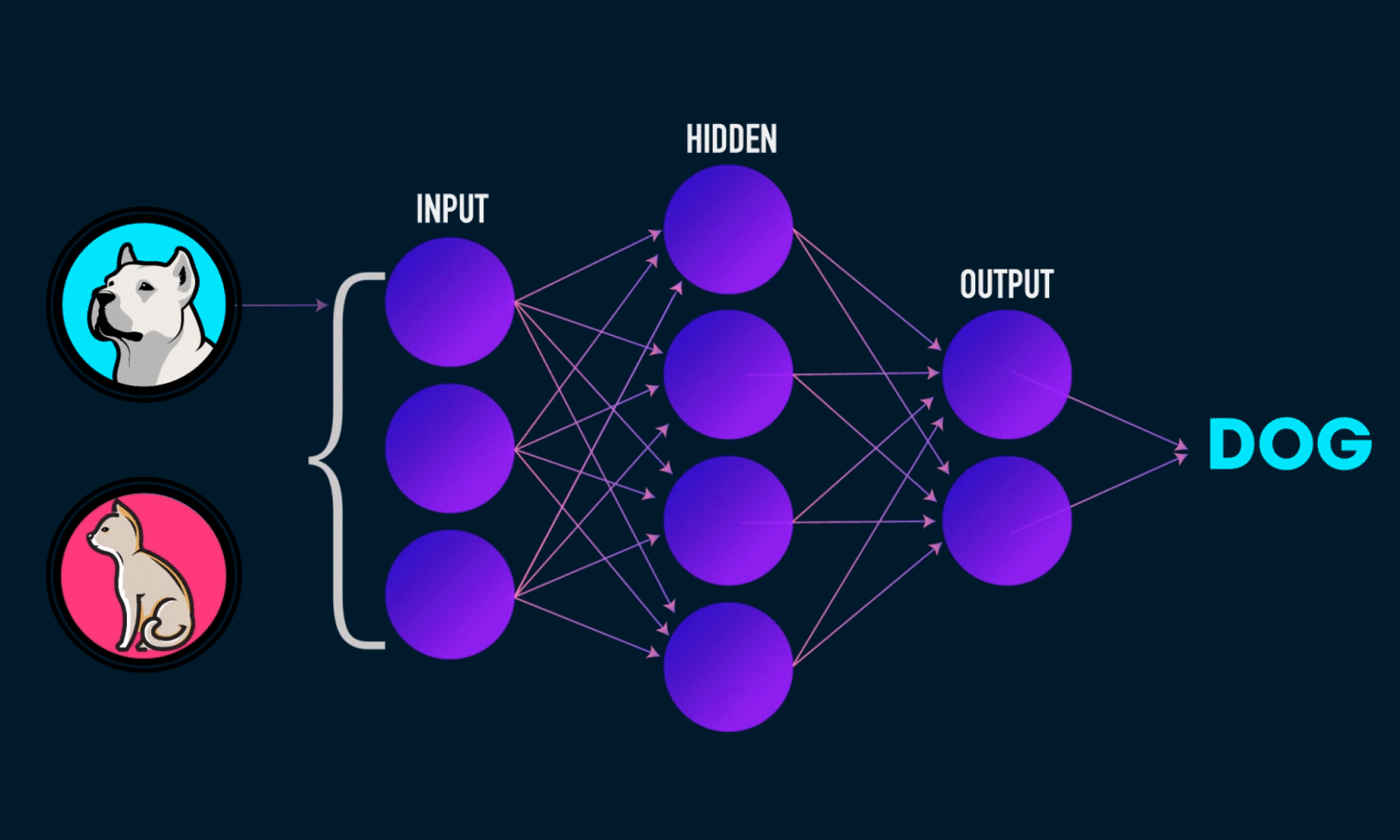
A. Deep Optimizers: Making the AI’s "Tutor" Smarter
The "optimizer" is the specific algorithm that teaches the AI how to adjust its weights during training (like SGD or Adam). NL shows that traditional optimizers are fundamentally just simple memory systems that compress the history of learning errors (gradients).
- The Improvement: NL upgrades these simple memory systems. Instead of a basic, linear form of memory, we can give the optimizer a more powerful, deeper learning module (like a small neural network called an MLP) to store and compress past gradients.
- The Result: This creates Deep Optimizers, which have greater capacity to capture how the model learned in the past, leading to more efficient and effective learning, such as the advanced Muon optimizer.
B. Continuum Memory System (CMS): Layered Knowledge
The CMS is the physical implementation of the multi-speed memory organization. Instead of relying on a simple separation between short-term (Attention) and long-term (FFN), CMS creates a chain of memory blocks, typically Feed-Forward Networks (FFNs), where each block has a designated update schedule.
- How it Works: Each FFN block is assigned a specific chunk size or update frequency. A block that updates frequently is responsible for capturing immediate, short-term knowledge, while a block that updates only every million steps is responsible for compressing that information into abstract knowledge over very long periods.
C. HOPE: The Self-Teaching AI
HOPE (Hybrid Optimization and Plasticity Engine) is the sequence model designed using the NL framework.
- Self-Referential: HOPE is unique because it is designed to be a self-referential learning module—meaning it learns how to modify its own update algorithm.
- Architecture: Unlike standard AI architectures (like Transformers), which have only one main FFN layer, HOPE has multiple FFN layers (e.g., Low Frequency FFN, Mid Frequency FFN, High Frequency FFN) that integrate the Continuum Memory System.
- Results: HOPE shows very good performance in challenging tasks like continual learning and language modeling, outperforming older Transformers and even recent competitors like Titans and DeltaNet in certain benchmark tests, demonstrating the benefit of organizing learning by frequency.
In essence, Nested Learning gives AI the ability to truly multitask internally, allowing different parts of its "mind" to learn, memorize, and consolidate information at their own optimal speeds, preventing the static amnesia that plagues current generation models.