How Do AI Models Learn?
Ever wonder how AI models learn and predict the impossible? In just 10 minutes, we’ll demystify all the complexities—no PhD required to understand it!
It took me days to fully grasp this, but I’ll help you understand it in less than 10 minutes. All you need to do is read the entire article carefully, with full focus, and in one go.
Let's say you are creating an AI model to produce the addition of numbers.
Say 2+2=4
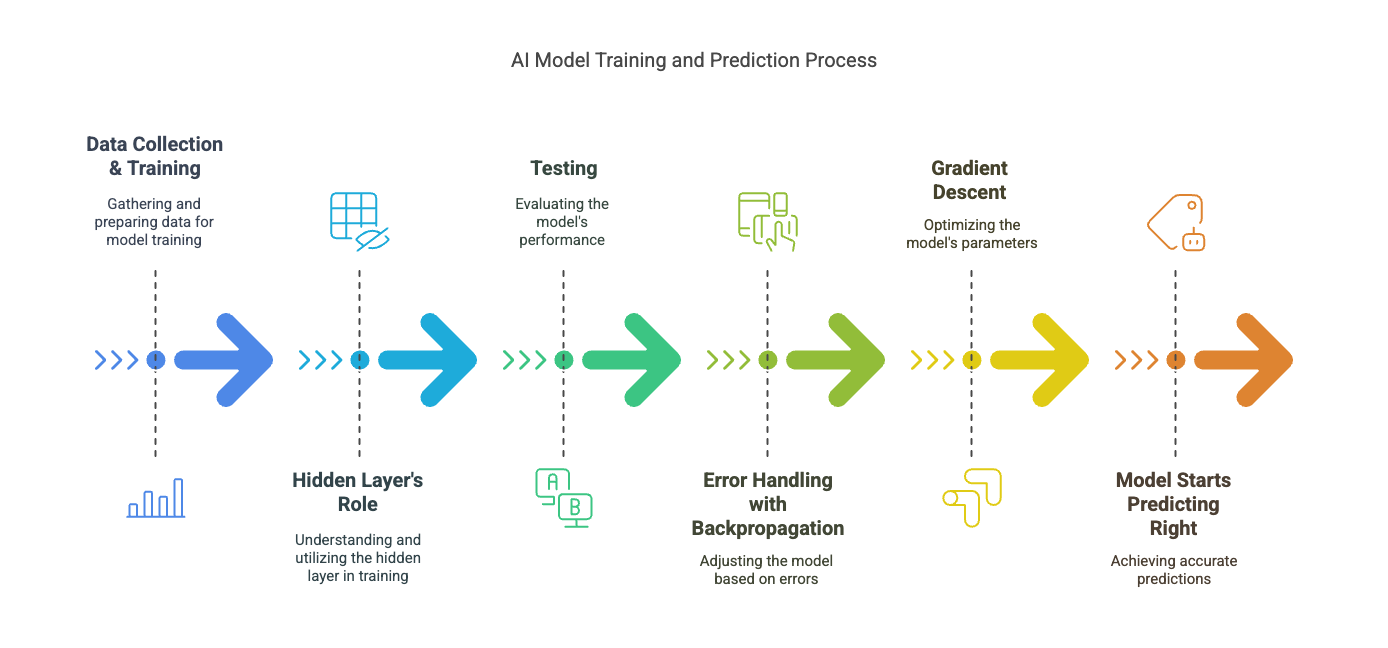
Step 1: Data Collection & Training the Model
Collect the clean and labelled data of additions with no mistakes. Make an AI model and feed this data into it.
[We will discuss it later, 'how to make such an AI model', for the time being just stay with me]
- The model starts by being trained on a large labeled dataset (say 10,000+ addition problems: "2+2=4", "3+3=6", etc.).
- The dataset (70-80% of it) is fed into the neural network for learning. Here, the data is used to teach the model the basic patterns, like recognizing that the sum of two numbers follows a consistent rule.
- The network tries to learn patterns from this data by adjusting its internal settings, such as weights and biases.
These settings help the model understand how to map inputs (numbers) to the correct output (sum).
If you don't know what is 'AI Model', weights and biases in general or how to feed data to train, don't worry we will make a tiny NN, get it trained, and make it predict.
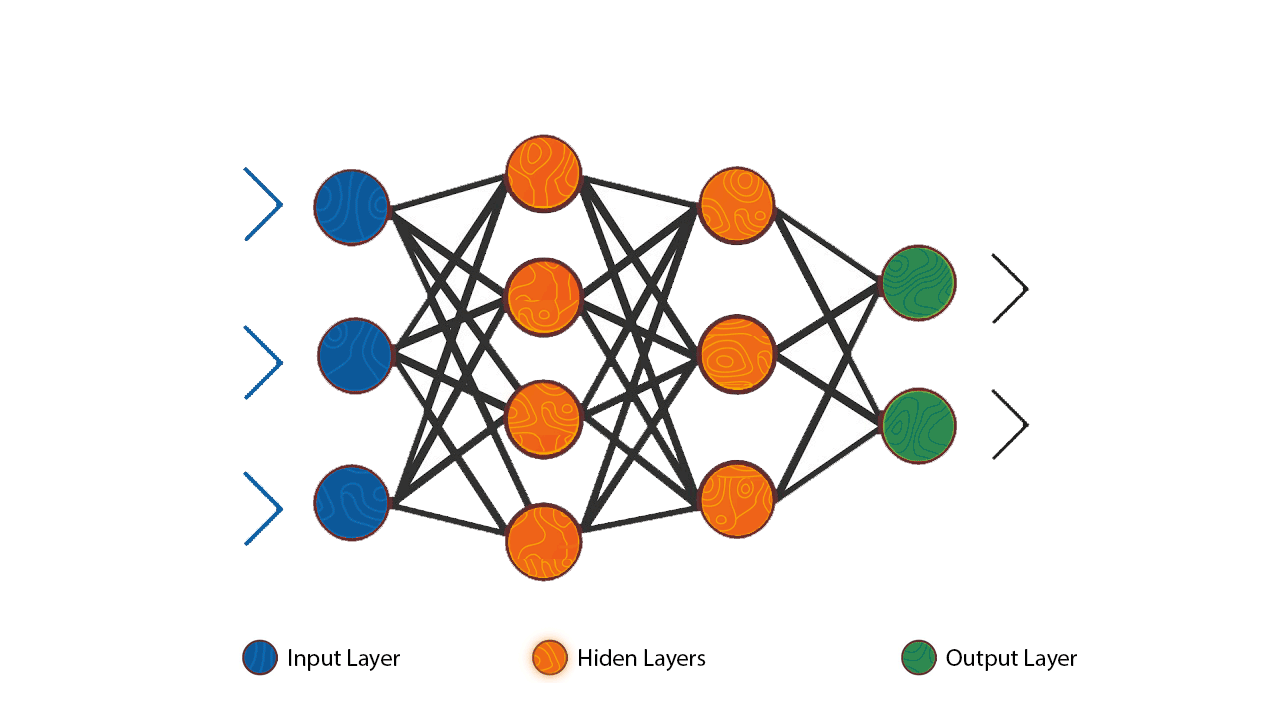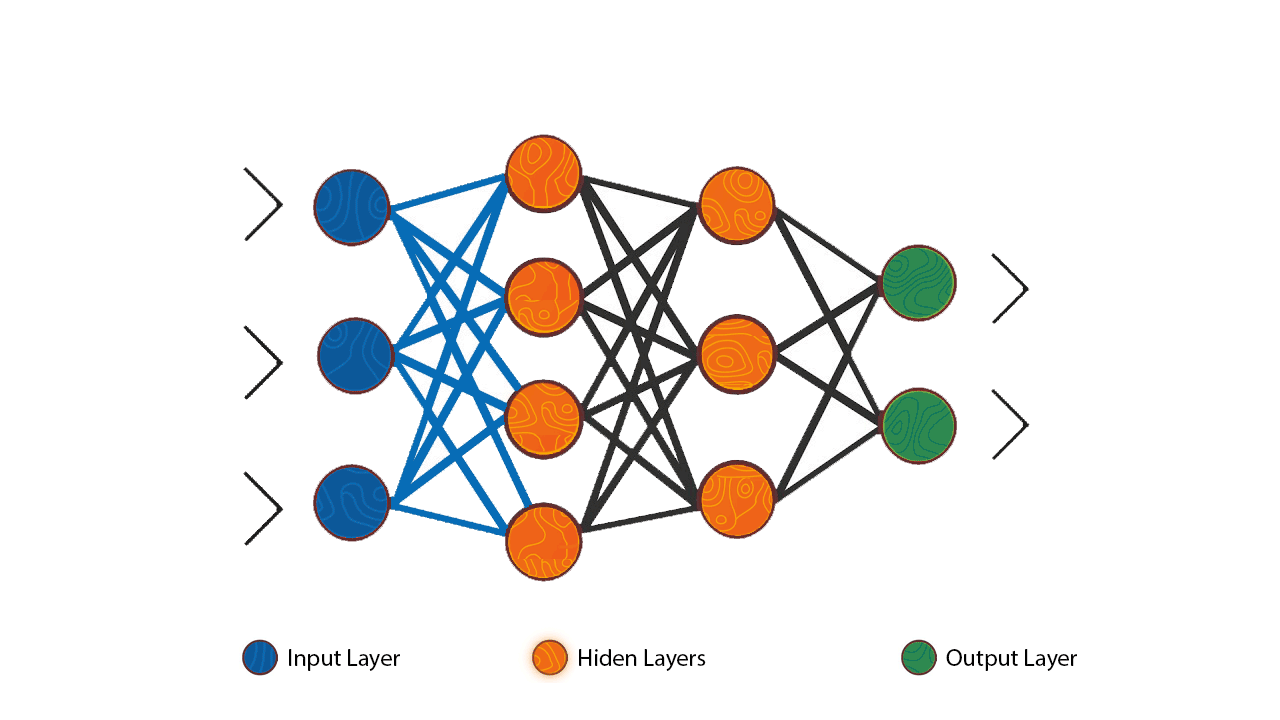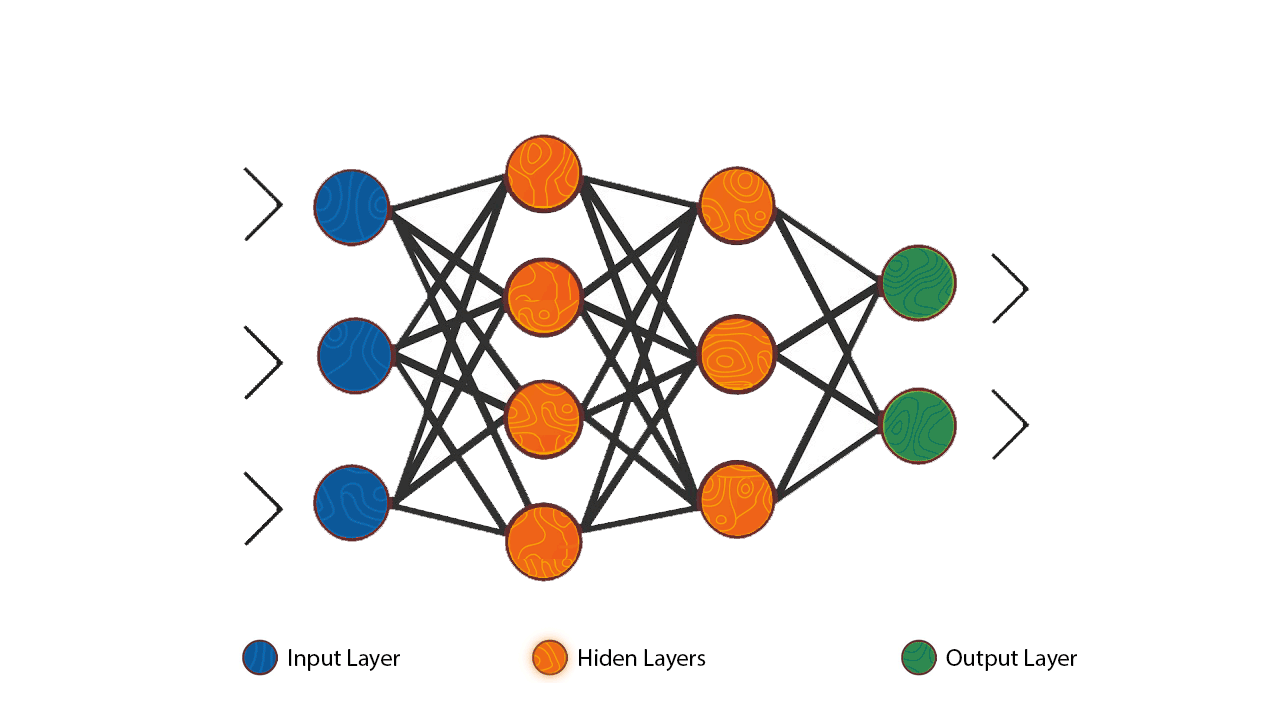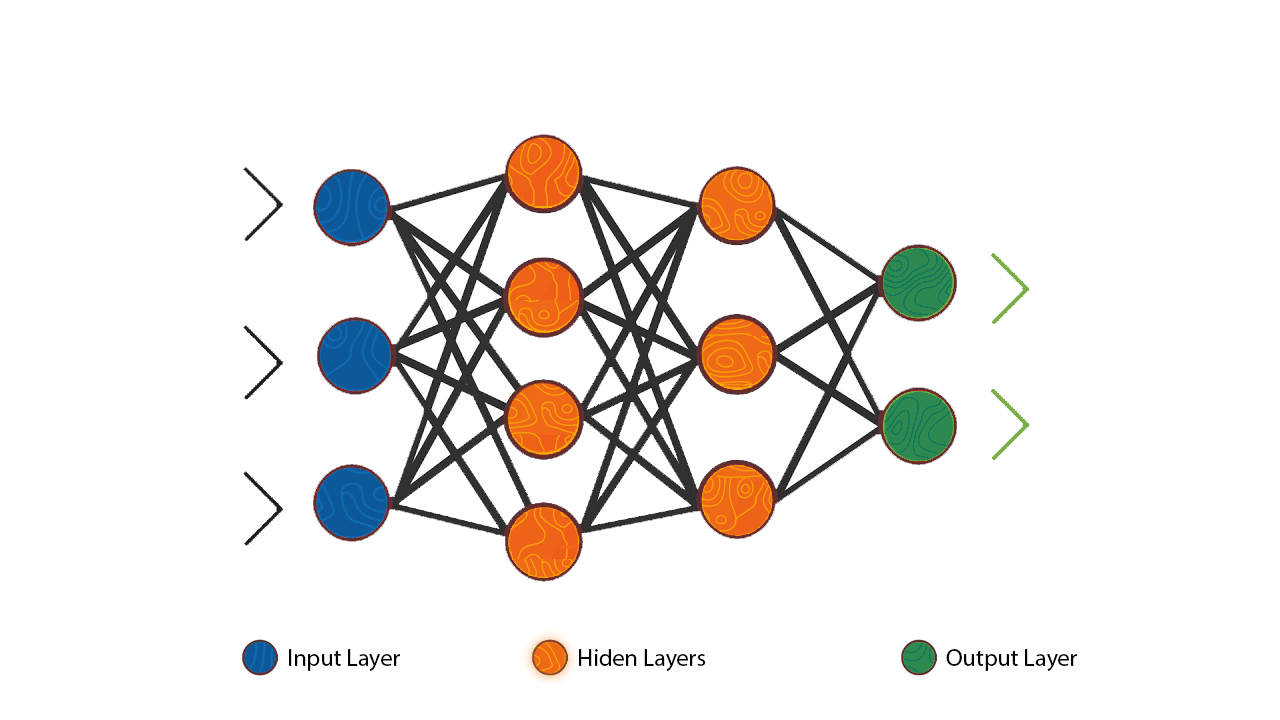
Step 2: The Hidden Layer's Role
The "hidden layer" in the network works behind the scenes to capture these patterns. It transforms the input data (e.g., 2+2) into something the model can learn from.
We are feeding the data from the left [input layer] and the output coming from the right [output layer]. The hidden layer works like a black-box and understand the pattern of the out put and try to adjust its knobs [weights and biases] to come closer to predicting the output.
The algorithm to find out the appropriate weights and biases is Gradient Descent,; which minimizes the loss function [the difference between actual output and model output], iteratively adjusting weights and biases in the direction that reduces the error most rapidly, i.e., the steepest descent.
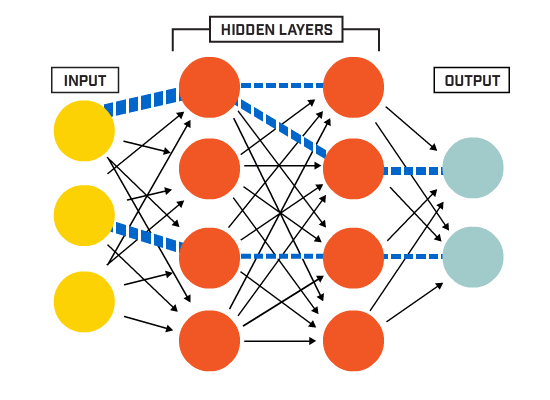
The hidden layer creates a more abstract representation of the data, which helps the model understand complex relationships.
Step 3: Testing
Remember, we used a 70% dataset for training; now we will be using the remaining 20-30% of the data as a test to evaluate how well the model has learned. This step helps check if the model can generalize its learning to new, unseen examples.
- Now, we test the model with a new problem, like "10+10".
- If the model answers "17" (which is wrong). The loss function calculates how far the model's prediction is from the correct answer (20). This helps the model understand its mistake.
Step 4: Error Handling with Backpropagation
Once the loss function identifies the error, backpropagation kicks in. This is the process where the error is sent back through the network.
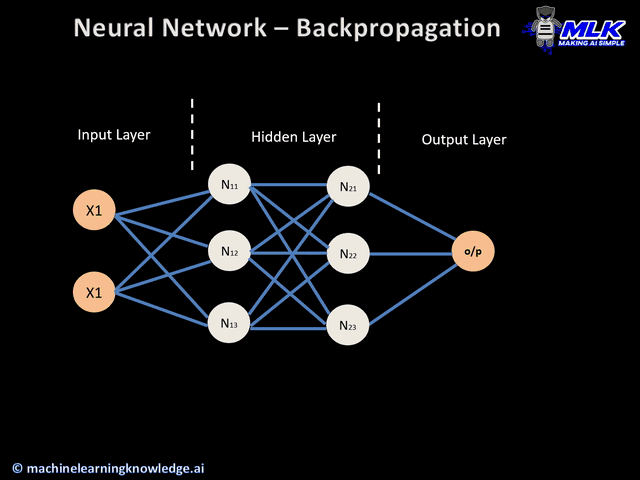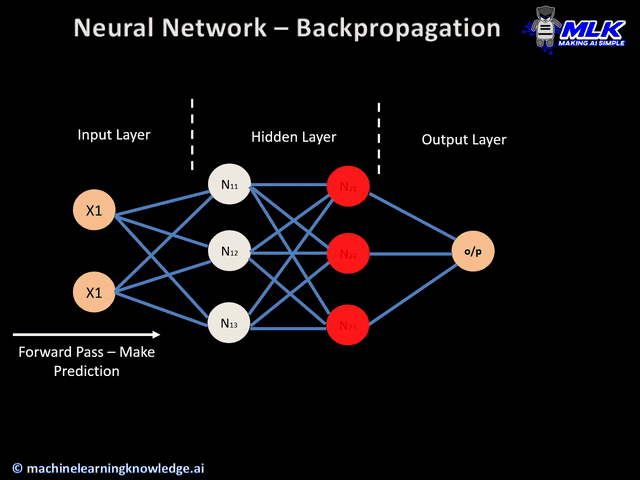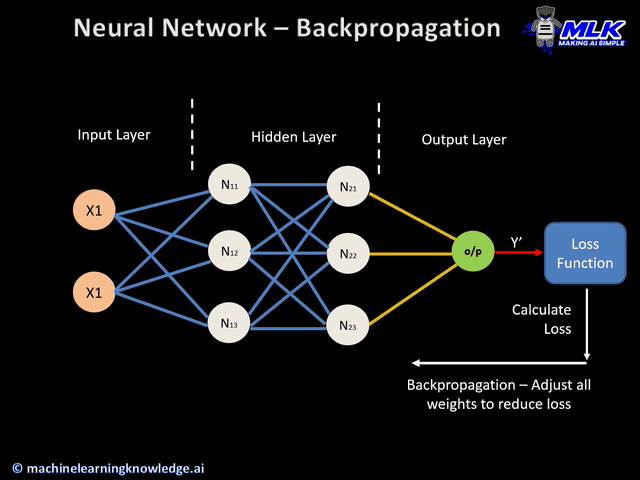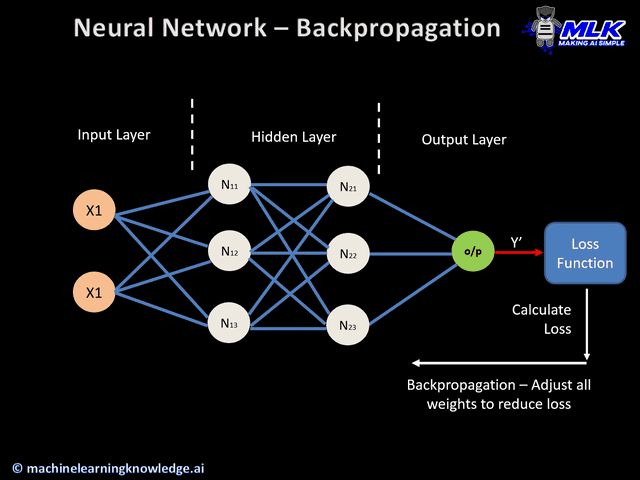
The network adjusts its weights and biases (its internal settings) to reduce the error. This is done using a method called gradient descent.
Remember the Imitation Game movie, where Turing cracked the Enigma code? Just like Turing adjusted the machine’s settings to accurately decode messages, a neural network adjusts its weights and biases through backpropagation. This process fine-tunes the model's parameters, minimizing the loss function to ensure accurate predictions, much like Turing's machine deciphering encrypted codes.

Step 5: Gradient Descent
Gradient descent adjusts the weights in small steps based on the error. It aims to make the model better at predicting the right answers by gradually minimizing the error over time.
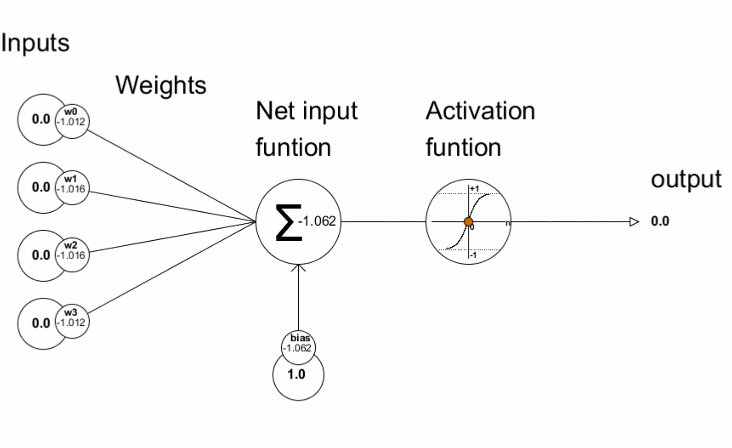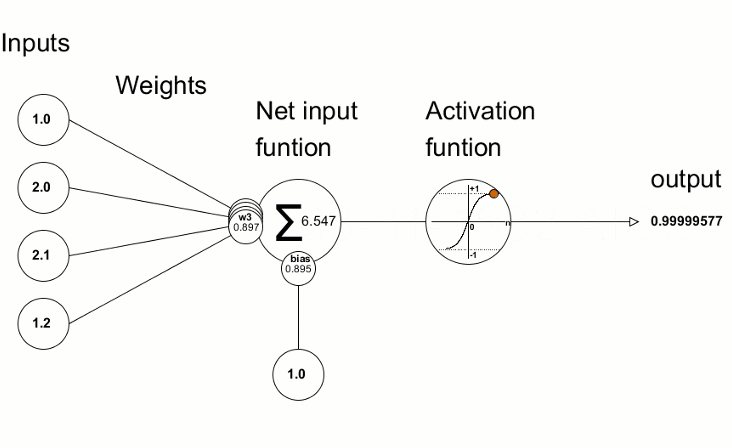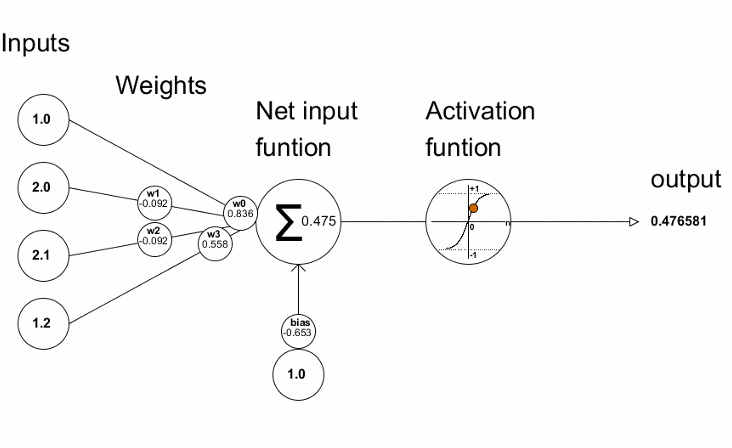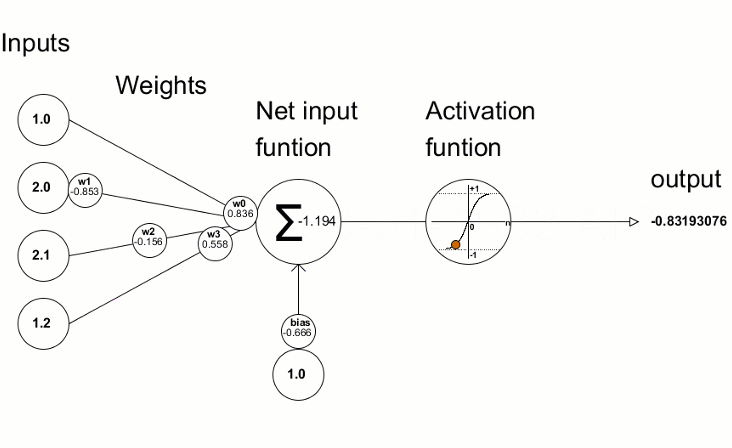
We put the input as 3+3, of the result comes as 5, then we calculate the loss function [See how the loss function is calculated here]
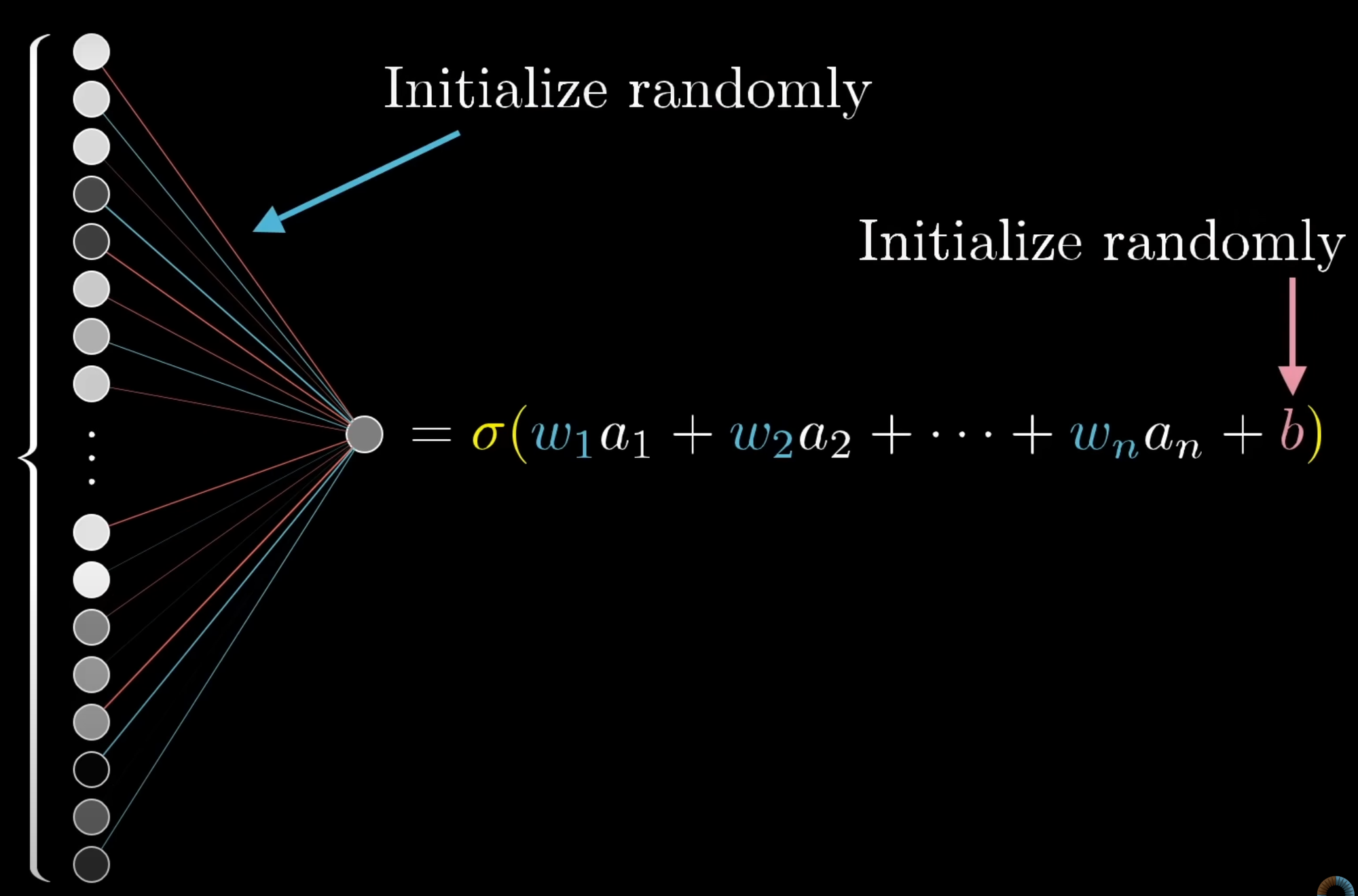
With the help of Gradient Descent, we find out the values of weights and biases to change because this is what we have in our hand; we can not influence the output directly, but we can change the weights and biases [starting with a random number] and change them accordingly.
The model continues this process: learning from training data, testing on new data, calculating errors, and adjusting its settings.
End goal: Minimising the cost function to near zero so that the difference between model output and actual output would be close to zero.
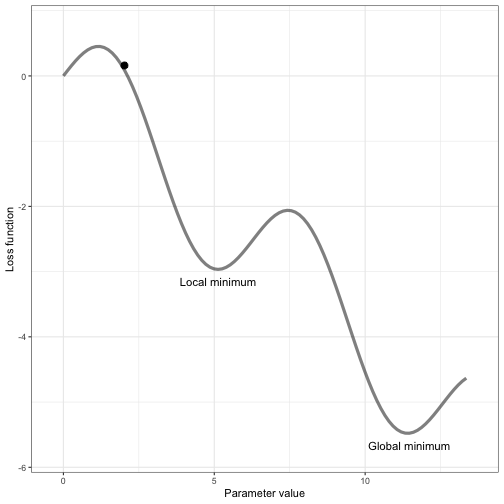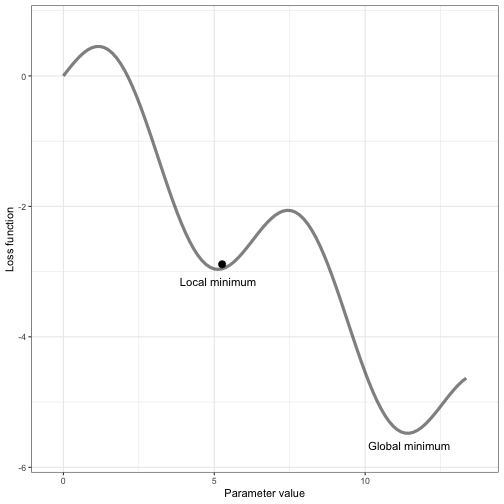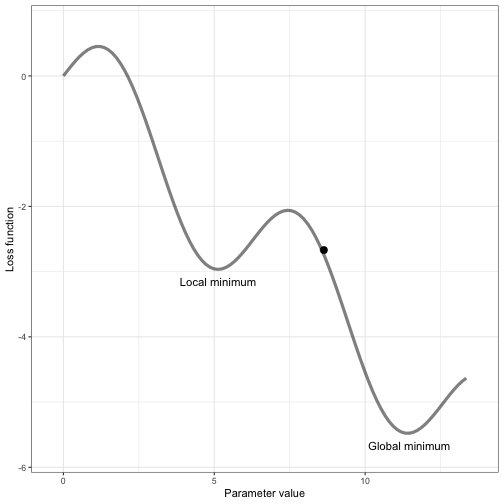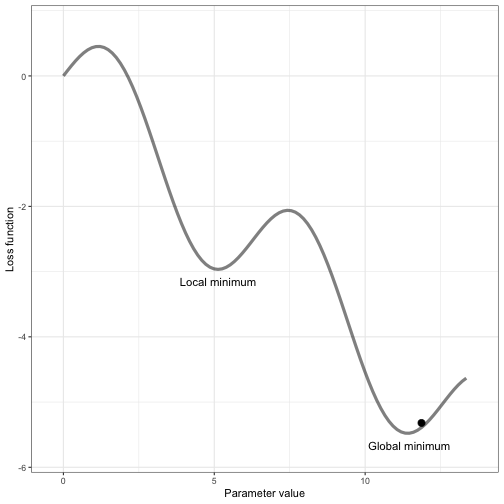
Each time the model makes a mistake, the weights and biases are fine-tuned, and it gets closer to giving the correct answers.
Step 6: Model starts predicting, 'Right'
- After enough cycles of learning and testing, the model reaches a point where its predictions are accurate. In the above image, that point is the Global minimum, i.e. minimal loss or the Steepest descent, we win.
- For example, when asked "6+6", it correctly answers "12" because it has learned the pattern from the data.
Let's sum up together the most important concepts that we can learnt here
Gradient Descent is an optimization technique used to minimize the loss function in machine learning and neural networks. It works by adjusting the model's parameters—weights and biases—based on the error or loss produced by the current model's predictions. Weights and biases are the internal parameters of the model that are learned during training. The learning rate controls how much the weights and biases should be adjusted with each iteration of gradient descent. Backpropagation is the process used to compute the gradients (i.e., the change required in weights and biases) by propagating the error backward through the network. This allows the network to fine-tune the weights and biases to reduce the loss function, which quantifies the model's error. By continuously updating the parameters in small steps (governed by the learning rate), the model gradually converges toward an optimal solution with minimal loss..
Watch these 3 videos without any gaps and thank me later.
If you haven't learned about Neural Networks or Deep Learning or how Neural Network learns, then read these two first: